Ep. 106
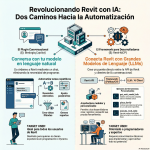
E106_GBrain es una memoria para Agentes IA alternativa a Obsidian
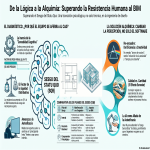
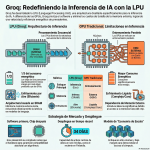
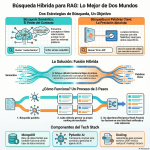
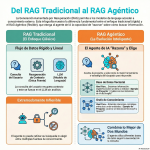
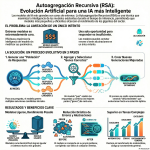
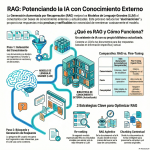
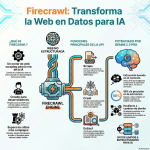
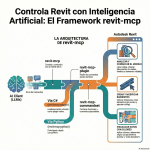
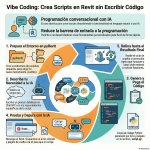
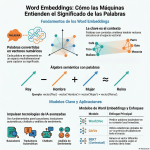
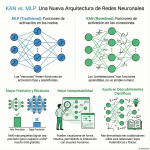
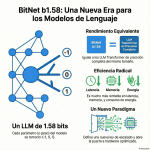
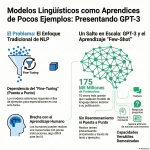
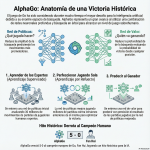
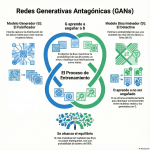
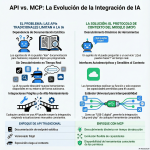
Episodio de BIMPRAXIS: La Memoria de IA y el Ecosistema Obsidian Exploramos la ciencia y la tecnología detrás de la memoria de IA, específicamente con G-Brain, y su conexión con el ecosistema Obsidian, una herramienta para tomar notas en texto plano. Analizamos cómo G-Brain busca romper el ciclo de la amnesia en la interacción con la inteligencia artificial, convirtiéndola en un compañero cognitivo real. También profundizamos en la convergencia de la vanguardia de la IA con filosofías de soberanía digital, y cómo esto puede cambiar la forma en que interactuamos con la tecnología.