Ep. 24
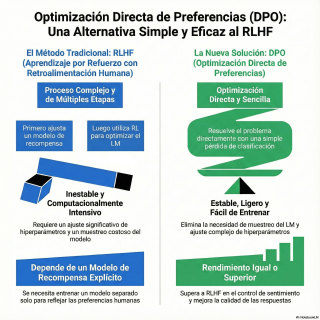
¿Te has preguntado por qué alinear los grandes modelos de lenguaje (LLMs) con las preferencias humanas sigue siendo un reto tan grande? 🤔 Tradicionalmente, el aprendizaje por refuerzo con retroalimentación humana (RLHF) ha sido el estándar de oro, pero es un proceso notoriamente complejo, inestable y costoso. En este episodio, analizamos el paper que propone un cambio de paradigma total: “Direct Preference Optimization: Your Language Model is Secretly a Reward Model”. Descubriremos la teoría de que tu propio modelo de lenguaje ya esconde la clave para alinearse, eliminando la necesidad de la maquinaria pesada del aprendizaje por refuerzo tradicional. 🛠️ Hablaremos de DPO, un algoritmo innovador que simplifica radicalmente el entrenamiento al transformar el problema de alineación en una simple pérdida de clasificación. 📉 Olvídate de entrenar modelos de recompensa separados o de lidiar con muestreos constantes durante el ajuste fino; DPO ofrece una solución estable, ligera y de alto rendimiento que iguala o supera a los métodos actuales como PPO. 🚀 Si quieres entender la técnica que está haciendo que el control y el ajuste fino de la IA sean más accesibles y eficientes que nunca, ¡no te pierdas este análisis a fondo! 🎧✨ Fuentes y enlaces de interés: • 📄 Paper Original (arXiv): Direct Preference Optimization