Buenas, esto es BIMPRAXIS, el podcast donde el BIM se encuentra con la inteligencia artificial.
Download transcript (.srt)
0:09
0:20
0:28
0:30
0:44
0:45
0:54
1:00
1:03
1:09
1:13
1:21
1:22
1:29
1:33
1:36
1:42
1:43
1:46
1:50
1:55
2:03
2:10
2:13
2:14
2:16
2:19
2:21
2:24
2:28
2:30
2:31
2:35
2:40
2:43
2:45
2:50
2:56
3:00
3:01
3:03
3:05
3:13
3:13
3:19
3:26
3:28
3:33
3:37
3:39
3:42
3:48
3:49
3:51
3:54
3:58
4:00
4:01
4:03
4:10
4:12
4:16
4:17
4:20
4:21
4:24
4:25
4:32
4:37
4:42
4:42
4:48
4:51
4:53
4:54
5:01
5:05
5:06
5:08
5:10
5:12
5:16
5:19
5:20
5:24
5:27
5:33
5:36
5:39
5:41
5:44
5:46
5:48
5:50
5:53
5:56
5:57
6:01
6:05
6:10
6:11
6:14
6:20
6:20
6:24
6:28
6:32
6:34
6:36
6:40
6:42
6:48
6:54
6:57
7:03
7:06
7:09
7:13
7:16
7:19
7:21
7:26
7:28
7:32
7:36
7:38
7:41
7:45
7:50
7:52
7:56
8:00
8:02
8:05
8:08
8:12
8:14
8:19
8:20
8:25
8:28
8:33
8:38
8:43
8:47
8:50
8:52
8:54
8:58
9:01
9:08
9:11
9:14
9:16
9:19
9:23
9:25
9:27
9:31
9:32
9:35
9:38
9:39
9:42
9:44
9:49
9:51
9:54
9:57
10:01
10:03
10:06
10:08
10:09
10:12
10:16
10:20
10:23
10:25
10:28
10:33
10:34
10:35
10:38
10:41
10:44
10:48
10:50
10:54
10:57
11:03
11:07
11:09
11:13
11:15
11:18
11:20
11:23
11:26
11:29
11:34
11:37
11:41
11:44
11:49
11:52
11:53
11:57
12:02
12:05
12:07
12:11
12:13
12:17
12:20
12:26
12:28
12:32
12:37
12:41
12:45
12:46
12:52
12:56
13:01
13:05
13:06
13:07
13:11
13:15
13:18
13:19
13:24
13:30
13:30
13:36
13:41
13:43
13:44
13:48
13:52
13:54
14:00
14:03
14:05
14:09
14:10
14:14
14:21
14:28
14:29
14:35
14:40
14:45
14:50
14:53
14:57
14:59
15:02
15:05
15:09
15:12
15:18
15:20
15:25
15:28
15:30
15:35
15:36
15:37
15:43
15:47
15:50
15:51
15:56
16:01
16:04
16:07
16:09
16:12
16:14
16:17
16:21
16:35
16:38
16:49
16:51
Exploramos la ciencia, la tecnología y el futuro desde el enfoque de la arquitectura, ingeniería y construcción.
¡Empezamos!
¿Alguna vez nos hemos parado a pensar en la extraña dualidad de la inteligencia artificial?
¿A qué te refieres exactamente?
Pues que, por un lado, tienes un sistema que ha absorbido, no sé, prácticamente todo el conocimiento humano escrito en Internet.
Pero, por otro, si lo dejas a su aire, puede ser, pues, completamente inútil o incluso caótico.
Ah, sí, es la gran pregunta.
La gran pregunta es, ¿cómo se le enseña a ser un copiloto fiable? O sea, ¿cómo se le enseña a comportarse?
Es que ese es el desagio central del sector en los últimos años.
Tienes esta potencia de cálculo y de conocimientos sin precedentes, pero carece de algo que es fundamental, el criterio.
El criterio, exacto.
No tiene un sentido innato de lo que es útil o seguro o simplemente coherente para una persona.
Es como tener un motor de Fórmula 1 sin volante ni frenos.
Una metáfora bastante acertada, sí.
Y, precisamente, de cómo se instaló un sistema de dirección mucho más eficiente va el análisis de hoy.
Bienvenidos a todos.
Además, hoy es un día un poco especial.
Hoy alcanzamos un pequeño hito en nuestra colaboración con BIMPRAXIS.
Es la décima entrega de esta serie especial, los papers que cambiaron la historia de la IA.
Y para celebrarlo, hemos escogido un artículo que, en mi opinión, es un ejemplo perfecto de elegancia científica.
Un trabajo de 2023 que miró un problema que todo el mundo atacaba con, bueno, con fuerza bruta y complejidad
y propuso una solución de una simplicidad absoluta.
Asombrosa.
El título ya da pistas.
El título ya es toda una declaración de intenciones.
Direct Preference Optimization.
Your language model is secretly a reward model.
Tu modelo de lenguaje es secretamente un modelo de recompensa.
Suena casi a thriller de espías, ¿eh?
Un poco, sí.
Pues el plan para los próximos minutos es justo ese.
Entender por qué el método anterior para educar a estas IAs era tan aparatoso.
Cómo este ideal lo cambió todo de la noche a la mañana.
Y sobre todo, por qué este avance es tan relevante.
Y relevante para la tecnología que muchísimos ya usamos a diario, además.
Bien, para entender la genialidad de la solución, primero hay que entender la magnitud del problema.
Partimos de estos modelos de lenguaje gigantescos, los LLMs.
¿Entrenados para una sola cosa?
Para una sola cosa.
Predecir la siguiente palabra en una secuencia.
Y son increíblemente buenos en eso, pero claro, esa habilidad no se traduce directamente en ser un buen conversador o un asistente útil.
Exacto.
A esa falta de educación, digamos, la llamamos el problema del alineamiento.
Un modelo no alineado puede darte respuestas verborreicas, inventarse datos con total seguridad, quedarse atascado en bucles…
O cosas peores.
O, en el peor de los casos, generar contenido dañino porque lo ha visto en algún rincón oscuro de Internet.
El objetivo es alinearlo con los valores y las intenciones humanas.
O sea, que sea útil, honesto y seguro.
Y hasta la llegada del paper de hoy.
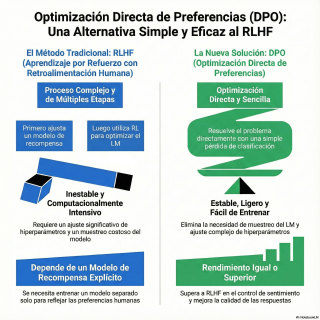
Sí, el estándar de oro para conseguir esto era un método con un nombre bastante intimidante.
RLHF.
Uf, RLHF.
Que son las siglas de Reinforcement Learning from Human Feedback.
O sea, aprendizaje por refuerzo con retroalimentación humana.
Y era un proceso, ¿eh?
Tan complejo como su nombre sugiere.
El propio artículo lo describe así, ¿no?
Sí, el propio artículo lo describe como un procedimiento de múltiples etapas y cada una era un desafío en sí misma.
A ver, describamos ese proceso.
Porque creo que ilustra perfectamente contra qué luchaban los investigadores.
¿Cuál era el primer paso?
Pues el primer paso era puramente humano.
Y masivo.
Se recopilaban miles y miles de datos de preferencias.
¿Cómo?
Esencialmente se le pedía a un grupo enorme de personas que evaluaran las respuestas del modelo.
Se les presentaba una pregunta y dos respuestas de la IA y tenían que elegir cuál es mejor.
Ya, a veces por utilidad, otras por seguridad, estilo.
Lo que fuera.
O sea, un ejército de anotadores humanos enseñando al sistema, caso por caso, lo que significa mejor.
Me imagino que eso ya de por sí es un proceso lento y caro.
Carísimo.
Y solo es el principio.
Una vez que tienes esa gigantesca base de datos de comparaciones, respuesta A es mejor que B,
empieza la segunda fase, entrenar a un juez artificial.
¿Un segundo modelo?
Un segundo modelo de inteligencia artificial.
Sí, completamente separado del primero.
Su único propósito es aprender.
Aprender de esos datos para predecir qué respuesta le gustaría más a un humano.
Este es el famoso modelo de recompensa.
Entiendo.
O sea, construyes una IA para que juzgue a otra IA.
Y supongo que el tercer paso es ponerlas a interactuar.
Ahí es donde entra la parte más compleja y, como dice el paper, a menudo inestable.
El aprendizaje por refuerzo.
El modelo del lenguaje original empieza a generar respuestas.
El juez artificial.
El modelo de recompensa le pone una nota a cada una.
¿Y a base de prueba y error?
A base... Sigamos con esa analogía.
Es perfecta.
Para programar al robot, primero le das a probar miles de pares
de rebanadas de pan a un panel de expertos para que elijan su favorita.
Claro.
Con esos datos enseñas al robot a imitar sus bustos.
Y una vez que el robot funciona, pones al panadero a hornear miles de panes a ciegas
y el robot simplemente le dice caliente o frío a cada intento.
El panadero tiene que deducir
la receta correcta a partir de esas señales tan indirectas.
Es un proceso enrevesado, indirecto y que suena terriblemente ineficiente.
Lo era.
Requería mantener y entrenar dos modelos enormes.
Ajustar decenas de parámetros técnicos muy sensibles, los hiperparámetros,
y rezar para que el sistema no divergiera o colapsara durante el entrenamiento.
Que pasaba a menudo, por lo que se cuenta.
Pasaba constantemente.
Recuerdo leer los foros de desarrolladores en aquella época y...
La frustración era palpable.
RLHF era la mejor herramienta que teníamos, pero era un verdadero dolor de cabeza.
Y aquí es donde el equipo de Rafael Lobby y compañía entra en escena y básicamente
le da la vuelta a la mesa. Su propuesta se llama DPO,
optimización directa de preferencias, y esa palabra directa es la clave de todo.
Es que lo fascinante es el cambio de perspectiva.
Ellos miraron ese complejo sistema de tres fases,
con dos modelos, y se hicieron la pregunta fundamental.
¿Es realmente necesario construir ese robot catador?
¿O es posible que la información ya esté en otra parte?
¿O es posible que la información sobre lo
que constituye un buen pan ya esté de alguna manera dentro del propio panadero?
Un momento, frena ahí.
Me estás diciendo que el modelo de lenguaje, que en principio sólo sabe
predecir la siguiente palabra, ya tenía implícitamente la capacidad
de entender qué respuesta es mejor que otra.
¿Que la solución estaba oculta a plena vista?
Sí, pues eso es exactamente lo que demostraron matemáticamente.
La gran revelación del paper es que no se necesita un modelo de recompensa externo.
Descubrieron una relación matemática
directa y elegante entre la política del modelo de lenguaje,
o sea, lo que decide escribir, y la función de recompensa óptima.
O sea que. En otras palabras,
encontraron una forma de usar los datos de preferencias humanas.
Esta respuesta es mejor que esta para ajustar
el modelo de lenguaje original directamente, sin intermediarios.
Clasificación de esto es bueno y esto es malo.
Capturar toda la sutileza del lenguaje y sustituir a ese sistema tan complejo.
¿Dónde está el truco?
El truco está en la formulación matemática, que es brillante.
En lugar de un sistema de prueba y error con recompensas,
transforman el problema en uno de clasificación binaria, que es mucho más simple y estable.
Vale. Al modelo se le presentan los dos textos, el preferido por los humanos y el
preferido, y su única tarea es ajustar sus conexiones internas para aumentar la
probabilidad de generar el texto bueno y disminuir la de generar el malo.
Es un ajuste fino, directo y elegantísimo.
Y se saltan todo lo demás.
Se saltan por completo la necesidad de
entrenar un juez y todo el andamiaje del aprendizaje por refuerzo.
Volviendo a la panadería, esto sería como sentarse con el panadero,
ponerle delante dos barras de pan y decirle Mira, la corteza de esta es perfecta y la
es esponjosa. Aprende directamente de esta comparación.
Exactamente esa es la intuición.
El panadero asimila esa información y
ajusta su propia técnica sin robots de por medio.
Claro. Y las ventajas que el artículo enumera son contundentes.
Primero, la estabilidad.
Al eliminar el aprendizaje por refuerzo,
eliminas la principal fuente de dolores de cabeza y de entrenamientos fallidos.
Y segundo, el coste.
Segundo, es computacionalmente mucho más ligero.
Requiere menos memoria, menos tiempo de GPU,
lo cual es vital cuando cada hora
de entrenamiento de estos modelos cuesta una fortuna.
Entonces, si es más estable y requiere
menos recursos, ¿qué significa eso para un equipo de desarrollo pequeño?
¿Pueden ahora competir en un terreno que
antes parecía reservado sólo para los gigantes tecnológicos?
Esa es una de las consecuencias más importantes.
La simplicidad de implementación es una ventaja brutal.
Ya no necesitas un equipo de expertos
en aprendizaje por refuerzo para ajustar tus modelos.
Es mucho más sencillo de poner
en marcha.
Y había otro punto técnico clave que mencionaba el paper.
Sí, hay otro punto que ahorra una cantidad de tiempo y dinero increíble.
No necesita muestrear respuestas del modelo durante el ajuste fino.
En RLHF, el modelo tenía que generar
millones de respuestas para que el juez las evaluara.
Con DPO, ese paso desaparece.
En resumen, una solución más limpia, más barata y más democrática.
Exacto.
La teoría es impecable.
Más simple, más estable, más barato.
Pero la prueba de fuego siempre está en la práctica.
¿Los resultados experimentales respaldan
esta simplicidad tan elegante o hay alguna contrapartida en la calidad?
Esa es la pregunta del millón y los
autores se centraron mucho en demostrarlo empíricamente.
La conclusión principal, que exponen sin rodeos en el abstract,
es que DPO consigue alinear los modelos de lenguaje tan bien y en algunos casos
incluso mejor que los métodos basados en RLHF.
Incluso mejor, es increíble.
Conseguir un resultado superior con un método más simple es el santo grial
en cualquier disciplina de ingeniería.
A veces la elegancia gana a la fuerza bruta.
El paper detalla varios experimentos para demostrarlo.
Por ejemplo, en una tarea muy interesante
que consistía en controlar el sentimiento de las respuestas del modelo.
Hacerlas más positivas o negativas a propósito.
Eso es, pedirle que generara textos deliberadamente más positivos o más
negativos, pues ahí DPO
superó con claridad al método de RLHF más popular de la época,
que se basaba en un algoritmo llamado PPO.
Lo que significa que el modelo resultante era más controlable, más predecible.
Podías dirigir su comportamiento con mayor precisión.
Precisamente.
Y en tareas más estándar, como la capacidad de resumir textos
largos o mantener un diálogo coherente, los resultados fueron igual de sólidos.
O sea que igualó o mejoró la calidad.
DPO igualó o mejoró la calidad.
DPO igualó la calidad de las respuestas en comparación con los métodos anteriores.
Consiguieron lo mismo o más,
pero con una fracción de la complejidad y del coste computacional.
Ahora bien, ¿es DPO la solución definitiva para todo?
¿O existen escenarios donde el viejo y complejo RLHF todavía podría tener alguna ventaja?
Es una pregunta muy pertinente.
DPO es extremadamente bueno para optimizar
un modelo basándose en un conjunto de datos de preferencias que ya existe.
Sin embargo, hay escenarios más exploratorios,
donde quizá quieres que el modelo descubra comportamientos completamente nuevos.
Entiendo.
En esos casos, algunos argumentan que el componente de exploración del aprendizaje
por refuerzo de RLHF podría seguir teniendo valor.
Pero para la tarea más común, que es coger un modelo ya potente y pulirlo
para que sea un buen asistente, DPO se ha convertido en el nuevo estándar
de facto.
Por su eficiencia.
Y el impacto de esto va mucho más allá de un laboratorio de investigación.
Cuando una tecnología fundamental se vuelve diez veces más simple y barata,
las ondas expansivas se notan en todo el ecosistema.
Totalmente.
Piensa en una startup con un equipo de 15 personas que ha desarrollado un modelo
de lenguaje para un nicho específico, por ejemplo, el sector legal o el médico.
Vale.
Antes de DPO, el proceso de alineación para hacerlo seguro y fiable era una barrera
casi insuperable, un coste que sólo podían asumir las grandes corporaciones.
DPO les abrió la puerta.
Claro.
De repente, equipos más pequeños, con menos recursos o incluso grupos
de investigación universitarios, podían permitirse el lujo de alinear
sus propios modelos de forma eficiente.
Acelera la innovación y la competencia porque permite que más actores entren
en el juego y ofrezcan soluciones especializadas.
Un problema que era un cuello de botella técnico y económico,
se convirtió en una herramienta mucho más accesible para todos.
Sin duda.
Si tuviéramos que condensar la importancia de este paper en una sola idea, ¿cuál sería?
Para mí, la gran lección es que a veces para resolver un problema increíblemente
complejo, la respuesta no es añadir más capas, más sistemas, más complejidad.
A veces es quitar.
La respuesta es dar un paso atrás y buscar una perspectiva nueva y más inteligente.
DPO demostró que la solución al alineamiento no estaba en construir un juez
externo, sino en encontrar la manera de hablar con el modelo en un idioma que ya entendía.
Es la navaja de Occam en estado puro, aplicada a la inteligencia artificial.
La solución más simple, a menudo, es la correcta.
La clave estaba oculta dentro del propio modelo, como sugería el título.
Y esto me parece que plantea una reflexión
importante sobre cómo enfocamos la investigación en este campo.
Hay una tendencia natural a pensar que los problemas más
grandes y difíciles requieren soluciones cada vez más grandes y complicadas.
Sí, este paper es un maravilloso
recordatorio de que un destello de elegancia matemática puede ser mucho más
poderoso que la fuerza bruta computacional.
A veces el mayor avance consiste en simplificar.
Me encanta el camino que abre este descubrimiento.
Si resulta que el modelo de lenguaje era
secretamente un modelo de recompensa y esa capacidad estaba ahí latente,
esperando ser descubierta.
Exacto.
Esto nos obliga a preguntarnos qué otras capacidades fundamentales podrían tener
estos sistemas ocultas en su estructura matemática, esperando a que alguien
encuentre la llave correcta para desbloquearlas.
Es una pregunta fascinante.
Quizá no se trata sólo de hacerlos más grandes, sino de aprender a entender mejor
lo que ya son. Es una idea que da un poco de vértigo, pero es fascinante.
Una pregunta que sin duda definirá la
próxima década de investigación en IA.
Y hablando de desbloquear nuevas
capacidades, no se pueden perder el análisis de mañana.
El de mañana también es muy bueno.
Vamos a explorar un paper interesantísimo
que cambió por completo nuestra idea de cómo las máquinas pueden razonar.
Les aseguro que es uno de esos que te deja pensando durante días.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.