Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:10
0:15
0:20
0:23
0:26
0:28
0:37
0:38
0:42
0:44
0:47
0:50
0:51
0:54
0:57
1:00
1:01
1:03
1:07
1:08
1:10
1:12
1:13
1:15
1:17
1:18
1:20
1:22
1:26
1:27
1:30
1:33
1:35
1:36
1:38
1:41
1:43
1:45
1:47
1:49
1:52
1:55
1:56
1:59
2:02
2:03
2:05
2:07
2:10
2:13
2:14
2:17
2:19
2:20
2:21
2:22
2:24
2:26
2:28
2:29
2:31
2:32
2:35
2:36
2:39
2:42
2:43
2:46
2:47
2:47
2:49
2:51
2:54
2:56
2:59
3:00
3:04
3:08
3:11
3:13
3:15
3:17
3:20
3:23
3:25
3:28
3:31
3:33
3:34
3:36
3:38
3:40
3:44
3:45
3:48
3:50
3:52
3:55
3:57
3:58
4:00
4:03
4:06
4:08
4:09
4:10
4:13
4:15
4:17
4:19
4:21
4:23
4:25
4:27
4:29
4:30
4:32
4:33
4:35
4:37
4:39
4:42
4:44
4:45
4:47
4:50
4:53
4:54
4:56
4:58
5:00
5:03
5:04
5:05
5:07
5:09
5:12
5:15
5:17
5:19
5:22
5:24
5:25
5:28
5:30
5:33
5:37
5:37
5:39
5:41
5:42
5:45
5:48
5:50
5:52
5:54
5:55
5:57
5:58
6:00
6:02
6:03
6:05
6:06
6:09
6:11
6:13
6:15
6:17
6:19
6:21
6:23
6:25
6:27
6:29
6:32
6:32
6:34
6:35
6:37
6:40
6:42
6:45
6:47
6:50
6:52
6:55
6:58
7:00
7:01
7:02
7:03
7:04
7:06
7:08
7:10
7:13
7:16
7:16
7:20
7:21
7:24
7:27
7:28
7:31
7:34
7:37
7:42
7:44
7:47
7:49
7:51
7:54
7:57
8:00
8:02
8:05
8:08
8:09
8:11
8:13
8:15
8:17
8:20
8:22
8:26
8:27
8:28
8:31
8:32
8:34
8:37
8:38
8:40
8:41
8:44
8:46
8:49
8:50
8:53
8:55
8:56
9:00
9:02
9:04
9:05
9:07
9:11
9:13
9:16
9:20
9:21
9:23
9:24
9:27
9:29
9:30
9:31
9:33
9:35
9:38
9:39
9:44
9:47
9:50
9:52
9:55
9:58
10:00
10:02
10:04
10:07
10:09
10:12
10:14
10:15
10:18
10:19
10:22
10:25
10:28
10:29
10:32
10:34
10:37
10:38
10:39
10:42
10:44
10:46
10:48
10:50
10:52
10:55
10:58
10:59
11:03
11:05
11:07
11:08
11:11
11:12
11:13
11:15
11:17
11:19
11:22
11:24
11:26
11:27
11:29
11:32
11:34
11:37
11:38
11:41
11:44
11:49
11:52
11:54
11:56
11:57
11:59
12:00
12:03
12:06
12:07
12:09
12:10
12:13
12:15
12:16
12:19
12:21
12:22
12:26
12:29
12:31
12:31
12:33
12:36
12:38
12:40
12:41
12:44
12:47
12:47
12:51
12:55
12:57
12:59
13:02
13:04
13:07
13:08
13:10
13:12
13:13
13:15
13:17
13:19
13:22
13:24
13:26
13:29
13:32
13:33
13:36
13:37
13:39
13:42
13:44
13:46
13:49
13:51
13:53
13:54
13:56
13:58
13:58
14:02
14:04
14:07
14:10
14:11
14:13
14:15
14:17
14:20
14:23
14:26
14:26
14:29
14:32
14:34
14:36
14:40
14:43
14:44
14:47
14:49
14:51
14:53
14:55
14:56
14:57
15:01
15:03
15:05
15:07
15:10
15:12
15:15
15:16
15:20
15:22
15:26
15:29
15:32
15:33
15:36
15:38
15:41
15:44
15:46
15:49
15:51
15:54
15:56
15:58
16:02
16:05
16:08
16:10
16:13
16:15
16:17
16:19
16:22
16:24
16:27
16:39
16:41
16:53
16:56
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas.
Bienvenidas, bienvenidos a un nuevo episodio de BIMPRAXIS.
Hoy os traemos el fascinante mundo de los
microchips de inteligencia artificial y la estrategia radical
de Grok para desafiar el dominio absoluto de
NVIDIA.
Bueno, y para empezar fuerte, pongámonos en situación.
Imagínate que tienes 10 millones de dólares sobre
la mesa, listos para entrar en tu cuenta
bancaria.
Y la única condición es no irte de
tu empresa, quedarte exactamente donde estás y vas
y dices que no.
Madre mía, 10 millones.
O sea, rechazar eso para fundar una startup
desde cero absoluto.
A ver, hay que tener una convicción casi
temeraria para dar un paso así.
Totalmente.
Y de esa certeza es de lo que
venimos a hablar en este análisis a fondo.
Hemos estado revisando dos entrevistas recientes y larguísimas
con Jonathan Ross, que es el CEO de
Grok, para intentar entender todo esto.
Toda la industria tecnológica parece estar enfocando mal
uno de los problemas más gordos de nuestra
era.
¿Y cómo poner el software primero puede cambiar
no sólo la economía, sino la geopolítica mundial?
Sí, sí, pero es que hay que contextualizar
quién es este hombre.
No es un ingeniero cualquiera.
Cuando estaba en Google, fue el creador del
TPU, la famosa unidad de procesamiento tensorial.
Claro, el chip de inteligencia artificial de Google.
Ese mismo.
Y fíjate que lo hizo dedicando el 20%
de su tiempo libre en esos proyectos paralelos
que dejaba hacer la empresa.
O sea, mientras todo el mundo se pedea
hoy por las tarjetas gráficas de siempre, las
GPUs, Grok está jugando a otra cosa.
A un ajedrez totalmente distinto, sí.
Y para entender de dónde sale el germen
de esta idea, hay una anécdota de 2012
en el comedor de Google que me parece,
vamos, buenísima.
Ya sé por dónde vas la historia del
modelo de voz.
Esa es.
Resulta que unos investigadores acaban de conseguir que
una IA reconozca la voz humana mejor que
una persona.
Un hito brutal.
Pero estaban amargados.
Claro, porque tenían el modelo entrenado, pero ponerlo
a funcionar en la vida real para millones
de usuarios era económicamente imposible.
Costaba una barbaridad en potencia de cálculo.
Y ahí entra Ross y crea el TPU
para solucionar ese cuello de botella.
Pero lo fuerte es cuando se va de
Google.
Porque se da cuenta de que si monta
una empresa nueva y hace un chip copiando
el enfoque tradicional, centrándose solo en la fuerza
bruta del hardware, se la va a pegar.
Se la pega seguro, por culpa del software.
O sea, para que te hagas una idea,
en empresas dominantes como NVIDIA puede haber 10.000
personas, 10.000, dedicadas solo a escribir kernels.
Espera, aclaremos esto un segundo.
Escribir kernels es básicamente programar a un nivel
bajísimo, ¿no?
Muy, muy cerca de la máquina física.
Exacto, código ensamblador puro y duro.
Es un trabajo hiperartesanal donde ajustas las matemáticas
a la forma física del silicio.
Y claro, ninguna startup puede contratar a 10.000
personas de golpe para igualar eso.
Ya, es imposible competir así de la noche
a la mañana.
Entonces Grok hace lo que la industria consideró
una herejía.
Se tiran los primeros seis meses construyendo un
compilador, o sea, software, antes de diseñar siquiera
la arquitectura del chip.
Es que suena a ciencia ficción.
Hicieron un modelo matemático perfecto de cómo debería
ser el hardware ideal para la IA, crearon
el software para ese modelo y luego ya
fabricaron el chip físico para que encajara como
un guante.
O sea, lo diseñaron para ser nativo en
la nube, en entornos serverless, que básicamente significa
que el desarrollador manda el código y no
tiene que pelearse con servidores ni gestionar la
memoria.
Funciona solo, sí.
La plataforma lo ejecuta de forma invisible.
Pues, a ver, haciendo una analogía.
Esto es como si te venden un coche
de Fórmula 1 hiper rápido, pero te dicen,
oye, construyete tú el circuito y ponle el
motor de arranque pieza por pieza.
Y Grok hace lo contrario.
Construye primero la pista y la telemetría.
Y luego hace un coche a medida para
que ruede solo.
Me encanta el ejemplo.
Es tal cual.
Pero esto me genera una duda razonable.
Si el software es el verdadero dolor de
cabeza, y hasta gigantes como Meta o Google
sufren con ello, ¿por qué absolutamente todas las
startups siguen cometiendo el error de empezar por
el silicio?
Por pura inercia cultural, la verdad.
A los ingenieros de hardware les apasiona el
hardware, les fascina buscar el nanosegundo de ventaja
física.
Pero Ross lo explica muy bien con un
escenario demoledor en las entrevistas.
¿Qué escenario plantea?
Pues imagina que haces el chip del futuro,
el más rápido de la historia.
Una maravilla.
pero si a los clientes les quitas una
sola función de software que ya usan hoy
en día, como el Speculative Decode o el
Prefix Caching, no te lo compra nadie.
Cero ventas, claro.
Nadie lo querría en sus centros de datos.
Oye, desgranemos un poco esos conceptos porque la
jerga técnica a veces asusta, y esto es
clave.
¿Qué es exactamente el Speculative Decode?
Es pura magia matemática, te lo prometo.
Básicamente la IA redacta en borrador varias palabras
futuras, las adivina, mientras todavía está procesando la
actual.
Si acierta, aprueba todo el bloca de golpe
y se ahorra muchísimo tiempo.
Ostras, qué bueno.
Es como ir rellenando el texto por adelantado.
¿Y el prefix caching qué hace?
Eso es guardar en memoria trozos de conversación
que se repiten mucho para que el modelo
no tenga que volver a leer todo el
historial cada vez que le haces una pregunta
nueva.
Son trucos 100% de software.
Si tu chip nuevo no soporta esto, su
rendimiento real se hunde.
Clarísimo.
O sea, el silicio sin software no es
nada.
Y bueno, una vez solucionado este problema inmenso,
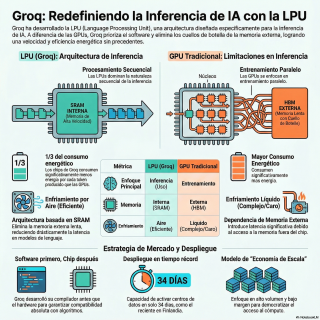
llegamos a la máquina en sí, el chip
LPU de Grok, la unidad de procesamiento de
lenguaje.
Aquí es donde empieza la verdadera guerra técnica
contra las famosas GPU.
Contra las tarjetas gráficas, exacto.
Y la diferencia por la que una arquitectura
es superior a otra está en las matemáticas
de la inferencia, que es la fase de
responder a los usuarios.
Porque entrenar una IA es un problema distinto,
¿verdad?
Es un problema paralelo.
Eso es.
Al entrenar, coges trillones de datos y pones
a miles de chips a devorarlos a la
vez, cada uno por su lado.
Para eso, las GPUs, que nacieron para calcular
millones de píxeles en la pantalla de un
videojuego al mismo tiempo, son perfectas.
Pero la inferencia, cuando el modelo genera texto
palabra por palabra, es secuencial.
O sea, matemáticamente no puedes adivinar el token
100 de una frase sin haber calculado primero
el 99.
Imposible.
Tiene que ir en orden.
Hay un ejemplo en las fuentes que ilustra
esto a la perfección.
Imagina que encargas un informe súper importante.
Si pones a 10 personas a escribirlo a
la vez en habitaciones separadas y sin comunicarse.
Sale un Frankenstein, un desastre sin sentido.
Tal cual.
Eso representaría intentar usar una GPU para inferencia.
En cambio, si coges a una sola persona
brillante y la pones a escribir, revisar y
reescribir 10 veces en secuencia lógica, te sale
un informe impecable.
Y a una velocidad vertiginosa.
Esa es la esencia del LPU de Grok.
Y fíjate, para conseguir que el hardware ejecute
esa secuencia tan rápido, tomaron otra decisión drástica.
Quitaron por completo la memoria externa.
Adiós a la memoria externa, la famosa HBM.
Pero a ver, ¿por qué?
Si todas las tarjetas gráficas la usan.
Sí, pero es un problema puramente físico.
Los cables finísimos que conectan el procesador con
esa memoria externa funcionan en realidad como pequeños
condensadores eléctricos.
Uy, espera, detengámonos en la física de esto.
¿Qué significa a nivel práctico que actúen como
condensadores?
Pues que cada vez que quieres mandar un
1 o un 0 por ese cable, primero
tienes que llenarlo de electrones.
Tienes que cargarlo de electricidad para que la
señal llegue al otro lado y luego descargarlo.
Ah, o sea que cuanta más distancia hay
hasta la memoria externa, más energía desperdicias sólo
en cargar y descargar cables.
Exacto.
Gastas mucho más energía moviendo el dato de
un lado a otro que haciendo la operación
matemática en sí.
Por eso Grohe usa sólo memoria interna, la
SRAM.
El dato vive exactamente donde se hace el
cálculo.
O sea, viaja milímetros en vez de centímetros.
Y el impacto de rediseñar esto a gran
escala es asombroso.
En los fuentes explican que para correr un
modelo masivo como llama Maverick, no dividen el
trabajo a ver qué chip está libre.
No, no.
Conectan más de 3.000 microchips directamente entre sí.
Sin switches de red intermedio, sin nada.
Es como una línea de montaje en una
fábrica, ¿no?
El token viaja por el silicio de los
3.000 procesadores casi al instante, perfectamente coreografiado.
Y el efecto dominó que provoca no usar
memoria externa te cambia todo el sistema.
Al no desperdiciar electricidad moviendo datos, el consumo
se desploma.
Hablamos de gastar una tercera parte de la
energía por cada palabra.
Y esto, fíjate, soluciona el que seguramente sea
el mayor cuello de botilla de la IA
hoy en día.
El problema térmico.
La refrigeración.
Claro, porque montar un centro de datos basado
en tarjetas gráficas ahora mismo es una pesadilla,
que tarda años.
Necesitas permisos eléctricos bestiales y sistemas de refrigeración
líquida complejísimos porque los chips son auténticos hornos.
literalmente hornos industriales.
Sin embargo, Grok levantó un centro de datos
operativo en Finlandia en 34 días y otro
en Arabia Saudí en 51 días.
Es un ritmo de otro planeta.
Lo consiguen porque están aprovechando lo que la
industria desecha.
Como no necesitan esa refrigeración líquida tan extrema,
funcionan con aire.
Así que alquilan los espacios enormes refrigerados por
aire que los gigantes de la nube están
abandonando por obsoletos.
Los enchufan y en semanas están operando.
¡Qué pasada!
Y esto nos empuja directamente a un concepto
geopolítico muy fuerte, la IA soberana.
Un concepto que está cambiando las políticas de
Estado.
Países enteros como Canadá o Arabia Saudí se
han dado cuenta de que la capacidad de
computación es ahora mismo como las plantas de
energía en la revolución industrial.
Claro.
Si estás en plena revolución, depender de un
país vecino para que te dé la electricidad
que mueve tus fábricas es un suicidio.
Exactamente.
Estas naciones ven que la IA va a
ser el motor económico y se niegan a
depender de que cuatro corporaciones de Estados Unidos
decidan cuándo les toca comprar GPUs en una
lista de espera de años.
Quieren su infraestructura ya, bajo su propia jurisdicción.
Y con la tecnología de Grok, que gasta
poca energía y se enfría por aire, les
cuadra perfecto.
Pero a ver, planteado así suena impecable, te
lo compro.
Ya viene el pero.
Sí, tengo que hacer de abogado del diablo
con el tema financiero.
En las fuentes, Ross dice que quiere acaparar
el 50% de la inferencia mundial tirando los
precios casi a cero.
Actuar como el Costco o el Amazon mayorista
de los chips.
Volumen muy alto, margen muy bajo, sí Pero
frente a los márgenes del 80% que tiene
Nvidia ¿Cómo convences tú a los inversores de
Silicon Valley De que ganar menos dinero por
operación es una victoria?
Es una pregunta buenísima La clave es entender
que entrenaría y usaría Son mercados con economías
opuestas El entrenamiento es pura investigación y desarrollo
Ahí paras márgenes del 80% Por tener el
modelo más inteligente del mundo Cueste lo que
cueste Vale, pero la inferencia es el día
a día.
Es cada vez que el usuario usa la
aplicación en el móvil.
Y para que ese volumen gigante de operaciones
sea viable, el coste tiene que tender a
cero.
Y aquí viene lo fascinante del argumento de
Ross.
Él dice que Grok es, irónicamente, lo mejor
que les ha pasado a los accionistas de
Nvidia.
Eso sí que me parece contraintuitivo total.
¿Cómo vas a ser aliado si quieres hundir
los precios?
Por pura lógica financiera, si Grok absorbe el
mercado de inferencia barata, Nvidia no tiene que
meterse en esa guerra de precios.
Queda protegida.
Ah, ya lo veo.
No tienen que devaluar sus productos estrella.
Pueden seguir vendiendo sus tarjetas al 80% de
margen destinadas solo a entrenamiento.
Eso es.
El mercado se bifurca, uno domina la investigación
cara y el otro monopoliza la ejecución masiva
y barata.
Vale, he entendido el modelo, pero vamos, sobrevivir
a escalar esto a semejante velocidad pasa factura.
Sabemos que la plataforma pasó de procesar casi
nada a servir 20 millones de tokens por
segundo en apenas 18 meses.
Y eso casi destruye la empresa.
Literalmente estuvieron a tres semanas de declarar la
bancarrota.
Madre mía, a tres semanas.
Y aquí es donde la cultura interna demostró
su valor.
Porque en tecnología, cuando pasa esto, lo habitual
es hacer despidos masivos.
Pero si hacían eso, se quedaban sin los
ingenieros que necesitaban para solucionar el problema.
Así que miraron a la historia, mi Litter.
a los bonos de la Segunda Guerra Mundial
y crearon los bonos GROC.
Propusieron a la plantilla recortes de sueldo voluntarios
a cambio de acciones.
El 80% de la plantilla aceptó el trato.
Es brutal.
Y lo más revelador, la mitad llegó a
bajarse el sueldo hasta el mínimo legal permitido.
Eso no se hace solo por dinero, requiere
una fe ciega en la tecnología.
Y esa experiencia de supervivencia extrema les generó
fobia a lo que ellos llaman la diabetes
financiera.
La diabetes financiera.
Qué buen concepto para describir el exceso de
dinero en Silicon Valley.
Sí.
Tener demasiado capital rápido adormece la innovación, porque
tapas los errores con dinero.
La escasez les obligó a ser más creativos.
Por eso también hablan mucho de contratar para
la suerte.
Que, ojo, no es magia ni superstición.
Es construir un equipo que esté predispuesto a
aprovechar oportunidades que otros ignoran.
El mejor ejemplo es cuando pivotaron hacia los
grandes modelos de lenguaje, los LLM.
Al principio, sus propios ingenieros dudaban de meterse
ahí.
Pensarían que no podían competir con los gigantes
establecidos, lógico.
Claro, pero Ross insistió.
Vieron que su hardware secuencial encajaba perfecto con
cómo los modelos generan texto palabra a palabra.
Apostaron, se hicieron virales y capitalizaron algo para
lo que ya estaban preparados.
Ya, pero liderar a este nivel de caos
y velocidad no se hace dando micro órdenes
a los ingenieros.
Y ahí entra el detalle físico de la
moneda de desafío que todos llevan en el
bolsillo.
Una moneda inspirada en el libro Turn the
Ship Around sobre un submarino nuclear estadounidense, ¿sí?
¿Y qué nos dice esa moneda sobre su
estilo de liderazgo intencional?
Pues que en vez de dar órdenes microscópicas
y decirle al equipo cómo hacer su trabajo,
marcaron un objetivo simple y binario grabado en
la moneda, alcanzar los 25 millones de tokens
por segundo.
Fijas el norte magnético, das el contexto y
dejas que los expertos empujen el barco.
Es una lección organizativa brillante, la verdad.
Y bueno, para cerrar este análisis, me gustaría
plantear un pensamiento provocador a la audiencia.
A ver, cuéntanos.
Hay un dato que me dejó pensando.
Ross destacó que de los 2 millones de
desarrolladores que usan su plataforma, 400.000 operan desde
la India, con una ética de trabajo implacable
y sin las comodidades de Silicon Valley.
Es un ejército de talento puro, sí.
Su pregunta me queda en el aire.
Si el coste de pensar y razonar, mediante
IA, tiende a cero gracias a tecnologías como
las de Grok, ¿Estamos a punto de ver
cómo las próximas cinco tecnológicas más grandes del
mundo nacen no en California, sino en regiones
emergentes que sepan exprimir al máximo esta computación
democratizada?
Es para pensarlo, desde luego Antes de despedirnos
hasta el próximo programa, os informamos de que
las voces que oyes han sido generadas por
la IA de Notebook LM y que dirigiendo
el podcast se encuentra Julio Pablo Vázquez, un
humano que te envía saludos En caso de
error, probablemente sean errores humanos.
¡Nos escuchamos!
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS Nos escuchamos en el próximo
episodio