Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:09
0:15
0:20
0:23
0:26
0:28
0:36
0:39
0:42
0:45
0:48
0:49
0:53
0:55
0:57
1:00
1:00
1:02
1:05
1:08
1:10
1:12
1:13
1:15
1:17
1:19
1:21
1:21
1:24
1:26
1:28
1:32
1:33
1:35
1:37
1:39
1:42
1:44
1:46
1:49
1:51
1:52
1:54
1:55
1:55
1:58
2:00
2:02
2:05
2:06
2:07
2:10
2:12
2:13
2:16
2:18
2:21
2:24
2:24
2:27
2:30
2:32
2:33
2:35
2:38
2:39
2:41
2:42
2:46
2:49
2:50
2:50
2:53
2:55
2:58
2:58
3:00
3:01
3:03
3:04
3:06
3:07
3:08
3:09
3:11
3:12
3:14
3:16
3:16
3:20
3:23
3:25
3:25
3:27
3:30
3:33
3:34
3:36
3:37
3:37
3:40
3:43
3:44
3:47
3:48
3:49
3:51
3:54
3:56
3:59
4:00
4:02
4:05
4:07
4:08
4:10
4:11
4:13
4:15
4:19
4:22
4:25
4:28
4:30
4:32
4:34
4:37
4:39
4:41
4:43
4:45
4:48
4:49
4:53
4:54
4:57
4:59
5:00
5:03
5:04
5:07
5:10
5:11
5:13
5:14
5:16
5:18
5:21
5:23
5:25
5:28
5:32
5:32
5:33
5:36
5:39
5:42
5:45
5:45
5:48
5:50
5:54
5:55
5:57
5:58
6:01
6:02
6:03
6:04
6:06
6:08
6:10
6:11
6:12
6:14
6:15
6:17
6:21
6:22
6:24
6:26
6:28
6:30
6:31
6:34
6:36
6:36
6:38
6:40
6:41
6:42
6:44
6:44
6:45
6:46
6:50
6:51
6:52
6:55
6:56
6:57
7:00
7:02
7:03
7:05
7:06
7:08
7:10
7:13
7:16
7:17
7:18
7:20
7:22
7:24
7:25
7:27
7:28
7:31
7:34
7:34
7:36
7:37
7:40
7:42
7:43
7:45
7:45
7:46
7:48
7:51
7:52
7:54
7:57
7:59
8:01
8:04
8:05
8:07
8:09
8:10
8:12
8:14
8:16
8:18
8:20
8:21
8:25
8:25
8:27
8:29
8:30
8:32
8:35
8:37
8:38
8:39
8:41
8:44
8:45
8:46
8:49
8:50
8:53
8:55
8:57
8:59
9:02
9:02
9:05
9:06
9:08
9:09
9:09
9:10
9:13
9:16
9:19
9:20
9:22
9:24
9:26
9:28
9:29
9:31
9:33
9:34
9:38
9:39
9:40
9:42
9:43
9:46
9:48
9:50
9:52
9:53
9:56
9:58
9:59
10:00
10:03
10:04
10:06
10:09
10:11
10:13
10:13
10:16
10:18
10:21
10:22
10:23
10:25
10:28
10:29
10:32
10:35
10:37
10:39
10:40
10:42
10:42
10:45
10:48
10:49
10:51
10:53
10:55
10:57
10:59
11:00
11:00
11:03
11:04
11:05
11:08
11:09
11:09
11:11
11:13
11:15
11:15
11:17
11:19
11:21
11:23
11:26
11:27
11:28
11:30
11:33
11:36
11:39
11:42
11:43
11:44
11:46
11:48
11:50
11:54
11:57
12:00
12:03
12:04
12:07
12:08
12:09
12:11
12:13
12:15
12:18
12:21
12:24
12:27
12:30
12:31
12:34
12:38
12:41
12:44
12:45
12:48
12:50
12:54
12:55
12:56
13:09
13:11
13:23
13:26
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
¡Hola, humanas y humanos!
Aquí estamos con un episodio nuevo de BIMPRAXIS.
En el episodio de hoy seguimos con la
serie dedicada a los RAG, los Retrieval Aumented
Generation.
Hoy traemos una potente combinación de técnicas.
Una combinación muy, muy potente, sí.
Vamos a ver cómo estos sistemas están empezando
a, bueno, a razonar de verdad.
Exacto.
El objetivo de los RAG, para poner un
poco de contexto, es dar a las IAs
la capacidad de buscar en nuestro propio conocimiento,
en nuestros documentos, vaya.
Pero claro, no todas las formas de buscar.
Son iguales.
Y creo que lo mejor es empezar por
la más básica, la que a veces llaman
RAG vainilla o RAG ingenuo.
Sí, es el punto de partida de todo
esto.
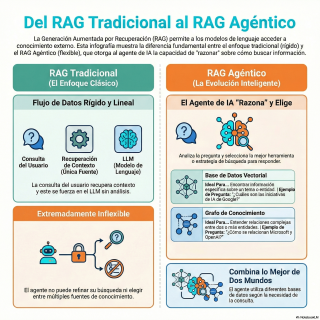
El RAG, digamos, clásico.
Venga, pues explícanos ese flujo tradicional.
A ver, es bastante lineal.
Primero, coges tus documentos, lo que sea, PDFs,
webs, da igual.
Y los partes en trocitos más pequeños.
Se les suele llamar chunks.
Claro, porque no puedes meter un informe de
100 páginas de golpe en el computador.
En el contexto del modelo no cabe.
Ni cabe ni es eficiente.
Una vez tienes esos fragmentos, creas una representación
vectorial de cada uno.
Un embedding.
O sea, lo traduces a números que la
máquina entiende.
Precisamente.
Y esos vectores, esos números, los guardas en
una base de datos vectorial.
El ejemplo de la fuente, de hecho, usa
PostgreSQL con la extensión pgVector, que es muy
popular para esto.
Vale.
Conocimiento troceado y convertido en vectores.
Y ahora llega la pregunta del usuario.
Y se repite el proceso.
La pregunta también se convierte en un vector.
Y entonces lo que hace el sistema es
buscar en la base de datos qué fragmentos
tienen los vectores más parecidos, más cercanos al
de la pregunta.
Y esos fragmentos son los que se usan
como contexto para que el LLM, el modelo
de lenguaje, genere la respuesta final.
Exacto.
Se le dice.
Responde a esto, pero usando esta información.
Suena bastante lógico.
Entonces, ¿dónde está el problema?
¿Cuál es la pega?
Pues mira, la principal debilidad es su inflexibilidad.
Es una tubería totalmente rígida.
¿Una tubería?
Sí.
El contexto se recupera y se inyecta la
fuerza en el prompt del LLM.
El agente de IA no tiene ninguna opción.
Ah, vale.
Debe usar ese contexto.
Sí o sí.
Le guste o no le guste, sea relevante
o no.
Es como si no pudiera levantar la mano
y decir, oye, esto que me has dado
no me sirve.
Justo.
No puede refinar su búsqueda ni pensar en
una estrategia mejor.
Ni consultar otras fuentes si las tuviera.
Es un receptor pasivo.
Vale.
Entonces necesitamos darle más autonomía, más iniciativa.
Aquí es donde entra en juego el concepto
de Agent X RAG, ¿no?
Exactamente.
Ahí está el cambio de paradigma.
La idea central es dar a la gente
la capacidad de razonar sobre cómo explora la
base de conocimiento.
Que deje de ser un simple ejecutor de
órdenes.
Eso es.
En lugar de ese paso previo forzado, el
agente ahora puede, por ejemplo, formular sus propias
consultas para buscar.
O sea, reformular mi pregunta para que la
base de datos la entienda mejor.
Sí.
O puede decidir si necesita buscar más información
o refinar la búsqueda que ya ha hecho.
Y lo más importante, puede elegir entre diferentes
herramientas o fuentes de conocimiento si las tiene
disponibles.
Es un cambio fundamental, vaya.
De ser un receptor pasivo de contexto a
ser un explorador activo de la información.
Totalmente.
¿Qué pasa de ser un bibliotecario que solo
busca en el fichero?
¿Qué le dicen a ser un investigador que
decide qué libros consultar?
Y aquí es donde se pone realmente interesante.
Porque el material que analizamos no se queda
solo en darle autonomía a la gente, sino
que le da una herramienta completamente diferente.
Los grafos de conocimiento.
Y esto es crucial.
Porque no es solo darle a elegir, es
darle opciones que son conceptualmente distintas.
A ver, explícanos la diferencia.
¿Base de datos vectorial?
¿Oltragrafo de conocimiento?
Mira, la base de datos vectorial es ideal
para encontrar información por similitud semántica.
Lo que hablábamos.
Responde genial a preguntas como, ¿qué iniciativas de
IA tiene Google?
Buscará textos que usen palabras parecidas a Google,
IA, iniciativas.
Correcto.
Pero un grafo de conocimiento, un knowledge graph,
juega en otra liga.
Su fuerte no es la similitud, son las
relaciones, las conexiones entre entidades.
¿No almacena solo datos?
No, no almacena solo datos, sino cómo se
conectan esos datos.
Ahí está la clave.
Usa ejemplos muy claros en la fuente.
Por ejemplo, no tienes solo un nodo Amazon
y un nodo Anthropic.
Tienes el nodo Amazon que se relaciona con
el nodo Anthropic a través de un enlace,
una relación, que dice ha invertido en.
¡Ostras!
¡Claro!
O el nodo Microsoft que se relaciona con
OpenAI a través de relaciones como son socios
o usa exclusivamente Azure.
Captura la estructura, el esqueleto del conocimiento.
Lo veo.
El agente ahora tiene dos formas muy distintas
de ver la misma información.
Una es semántica y la otra es...
Relacional.
Una es una biblioteca y la otra es
un mapa de conexiones.
Y eso le da una potencia increíble.
Vamos a llevar esto a la práctica, que
creo que es como mejor se va a
entender.
La fuente describe un agente que tiene acceso
a las dos herramientas.
Y lo interesante es ver cómo elige una
u otra según la pregunta.
Sí.
La demostración es muy, muy clara.
Ponen tres ejemplos.
El primero, una pregunta sencilla.
¿Cuáles son las iniciativas de IA de Google?
La que ya hemos dicho.
Un caso de libro para la búsqueda vectorial.
Y el agente lo pilla al vuelo.
Su razonamiento interno es algo como...
A ver, la pregunta va sobre una única
entidad, Google.
No necesito explorar relaciones complejas.
No hay que conectar puntos, vaya.
Exacto.
Así que su acción es clara.
Elige usar la búsqueda vectorial.
¿Recupera los fragmentos sobre Google?
¿Recupera los fragmentos sobre Google y responde?
¿Eficiente y directo?
Vale.
Fácil.
Segundo escenario.
La segunda pregunta es, ¿cómo se relacionan OpenAI
y Microsoft?
Ah, amigo.
Aquí la palabra clave es relacionan.
Es una pista enorme.
Es un dispararar total.
El agente detecta que la pregunta va explícitamente
sobre la conexión entre dos entidades.
Con lo cual...
Con lo cual, elige usar la búsqueda en
el grafo.
Ignora la biblioteca de textos y se va
directo al mapa de conexiones.
Sigue el enlace entre el nodo OpenAI y
el nodo Microsoft y extrae la información de
esa relación.
Es mucho más preciso.
Te evitas el ruido de encontrar un artículo
que las mencione a las dos de pasada,
pero sin explicar nada.
Va directo al grano.
Y el tercer caso es el que lo
une todo.
La pregunta es, ¿cuáles son las iniciativas de
Microsoft y cómo se relacionan con Anthropic?
Interesante.
Es una pregunta doble.
Efectivamente.
Una parte es descriptiva, sobre Microsoft.
Y la otra es relacional, sobre su conexión
con Anthropic.
Y el agente es capaz de darse cuenta,
supongo.
Sí.
Y de descomponer la pregunta.
Su razonamiento es, vale, necesito dos tipos de
información.
Por un lado, info general de Microsoft.
Para eso lo mejor es la búsqueda vectorial.
Por otro, analizar una relación.
Para eso el grafo es la herramienta.
Con lo que decide usar las dos.
Exacto.
Lanza una consulta a la base de datos
vectorial para lo de Microsoft.
Y otra a la base de datos vectorial.
Al grafo, para ver la conexión con Anthropic.
Y luego junta los dos resultados para dar
una respuesta completa.
Y lo más importante, y creo que este
es el punto clave, no es el usuario
quien elige la herramienta.
Es el agente quien razona y toma la
decisión.
Ese es el salto cualitativo.
Pasamos de un sistema que busca a un
sistema que investiga.
Esto suena muy potente, pero también me da
la sensación de que es complejo de implementar.
¿Qué piezas se necesitan para montar un sistema
así?
Bueno, no es trivial.
Pero las herramientas son cada vez más accesibles.
La fuente menciona su tech stack, su pila
tecnológica.
A ver.
Usan Vosgres con PG Vector para los vectores,
como dijimos.
Para el grafo de conocimiento usan Neo4, que
es como el estándar de la industria.
Y todo el cerebro de la gente lo
montan con una librería de Python que se
llama Pydantic A, servido con FastTP.
Vale.
Son herramientas más o menos conocidas en el
mundillo.
Sí, no es nada esotérico.
¿Qué es lo que se usa para montar
un sistema así?
La tecnología es solo una parte.
Lo que más me intriga es cómo le
dices a la gente cuándo usar cada herramienta,
cómo se le dan esas instrucciones, esas reglas.
Esa es la pregunta del millón.
Y la respuesta está en lo que se
llama el System Prompt.
¿El Prompt de Sistema?
¿Las instrucciones iniciales?
Justo.
Es el conjunto de instrucciones que guían todo
el comportamiento de la gente.
Es como su constitución.
El desarrollador define ahí las reglas de razonamiento.
Dame un ejemplo.
¿Qué es una de esas reglas?
La fuente cita uno muy claro de su
propio proyecto.
Le dicen algo como, usa el grafo de
conocimiento solo cuando el usuario pregunte por dos
empresas en la misma pregunta.
En caso contrario, usa la base de datos
vectorial.
Combina ambas solo si se te pide explícitamente.
O sea que es bastante explícito.
No es magia.
Para nada.
Es un trabajo de ingeniería de prompts muy
cuidadoso.
Tienes que pensar en los casos de uso
y traducirlos a instrucciones claras para la IA.
Y este prompt, claro, tienes que adaptarlo a
tus datos y a tu problema concreto.
Claro.
Me imagino que es un punto muy delicado.
Si el prompt es ambiguo o te dejas
fuera un caso importante, el agente puede tomar
una decisión equivocada.
Totalmente.
Es un proceso iterativo.
Pruebas, ves dónde fallar y refinas las instrucciones.
No hay una solución universal.
Y como apunte final, hay un detalle en
el material que es fascinante.
Sobre cómo se construyó este proyecto.
¿Ah, sí?
Es una capa meta que te deja pensando,
la verdad.
Cuéntalo.
El autor del proyecto comenta que para crear
gran parte del agente, utilizó un asistente de
codificación de IA.
Usó Cloud Code.
Espera, ¿me estás diciendo que usó una IA
para programar esta otra IA?
Una IA construyendo a otra IA.
Pero lo increíble no es solo eso, es
cómo lo hizo.
¿Cómo?
No le fue dando órdenes paso a paso
en plan, ahora escribe esta función.
No.
El propio proceso de desarrollo fue agéntico.
¿Qué quieres decir?
¿Qué quieres decir con eso?
Pues que le dio al asistente de codificación
un plan de alto nivel, una lista de
tareas y unas reglas generales.
¿Y con eso?
¿Lo dejó trabajar solo?
Lo dejó trabajar solo durante largos periodos.
La fuente habla de una sesión de 35
minutos seguidos en la que la IA estuvo
escribiendo código, creando las bases de datos, validando
su trabajo.
¡Madre mía!
Es un agente de IA que, de forma
autónoma, construye otro agente de IA.
Es una muñeca rusa de inteligencia artificial.
Así que, ¿cuál es…?
¿Cuál es la gran conclusión de todo esto,
la idea con la que nos tenemos que
quedar?
Pues yo diría que la idea principal es
que estamos yendo más allá de la simple
recuperación de información.
La combinación de este enfoque agéntico, con múltiples
formas de ver el conocimiento, vectores y grafos,
permite a las IAs no sólo recuperar datos,
sino hacerlo de una forma mucho más inteligente.
¿Mucho más humana?
Eligiendo la herramienta adecuada para cada tarea, como
haría un experto.
Exacto.
Ya no se trata sólo de buscar, se
trata de investigar.
Y esto me lleva a una reflexión final,
un pensamiento un poco provocador.
Si un agente de IA ya puede aprender
a elegir la mejor herramienta para buscar en
la información que le damos… ¿Qué pasará cuando
empiece a cuestionar la calidad de esas fuentes
que le proporcionamos?
¿Cuándo pasará de ser un recuperador de datos
a un evaluador crítico del conocimiento?
Nos despedimos por hoy, recordándoos que las voces
que escuchas han sido generadas por una IA,
Notebook LM.
Aunque el podcast no carece del factor humano,
porque en la trastienda está Julio Pablo Vázquez,
que investiga buscando temas interesantes que traeros prácticamente
todos los días.
Os manda saludos.
Hasta el próximo episodio, queridos humanos.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
El próximo episodio.