Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:10
0:15
0:20
0:23
0:26
0:28
0:37
0:39
0:41
0:43
0:45
0:46
0:48
0:51
0:54
0:57
0:58
1:00
1:01
1:03
1:06
1:07
1:10
1:11
1:14
1:17
1:18
1:19
1:20
1:22
1:24
1:24
1:27
1:28
1:30
1:33
1:36
1:39
1:41
1:42
1:44
1:47
1:48
1:51
1:54
1:56
1:57
1:58
2:00
2:03
2:04
2:06
2:08
2:10
2:12
2:14
2:17
2:18
2:22
2:24
2:26
2:28
2:30
2:34
2:36
2:37
2:41
2:43
2:45
2:48
2:52
2:54
2:56
2:56
2:59
3:01
3:03
3:05
3:06
3:09
3:12
3:13
3:16
3:19
3:22
3:23
3:25
3:27
3:29
3:31
3:34
3:36
3:37
3:41
3:42
3:44
3:45
3:46
3:49
3:51
3:53
3:56
3:57
3:58
4:00
4:01
4:02
4:04
4:07
4:09
4:11
4:12
4:14
4:18
4:19
4:21
4:24
4:26
4:29
4:32
4:32
4:33
4:35
4:38
4:39
4:42
4:45
4:47
4:47
4:50
4:52
4:54
4:55
4:58
5:00
5:02
5:03
5:04
5:05
5:07
5:09
5:10
5:13
5:14
5:16
5:19
5:21
5:23
5:25
5:27
5:28
5:30
5:32
5:35
5:36
5:37
5:39
5:42
5:44
5:46
5:48
5:51
5:52
5:55
5:57
5:59
6:00
6:02
6:03
6:05
6:07
6:11
6:14
6:16
6:18
6:19
6:22
6:25
6:28
6:30
6:32
6:34
6:36
6:36
6:38
6:40
6:42
6:46
6:48
6:50
6:51
6:54
6:55
6:57
7:00
7:02
7:03
7:05
7:07
7:08
7:08
7:10
7:12
7:15
7:16
7:18
7:19
7:21
7:22
7:24
7:26
7:28
7:30
7:31
7:34
7:35
7:36
7:38
7:40
7:43
7:44
7:48
7:50
7:51
7:52
7:54
7:56
8:00
8:04
8:05
8:08
8:11
8:14
8:15
8:18
8:19
8:20
8:23
8:24
8:25
8:27
8:28
8:29
8:31
8:32
8:33
8:37
8:39
8:41
8:43
8:44
8:46
8:48
8:50
8:51
8:52
8:55
8:57
8:59
9:01
9:03
9:05
9:07
9:09
9:10
9:11
9:13
9:15
9:17
9:19
9:21
9:23
9:25
9:28
9:30
9:33
9:36
9:37
9:38
9:40
9:43
9:44
9:46
9:47
9:49
9:53
9:57
9:59
10:00
10:02
10:06
10:08
10:09
10:12
10:13
10:15
10:17
10:20
10:22
10:24
10:27
10:29
10:32
10:33
10:35
10:38
10:39
10:41
10:44
10:46
10:46
10:49
10:51
10:52
10:54
10:57
10:59
11:00
11:04
11:05
11:07
11:09
11:11
11:14
11:16
11:17
11:18
11:22
11:25
11:28
11:31
11:34
11:37
11:40
11:43
11:47
11:50
11:51
11:54
11:56
12:09
12:11
12:22
12:25
12:43
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Hola de nuevo a un episodio más de
BIMPRAXIS.
Hoy llegamos al número 50.
50 ya, felicidades.
Gracias.
Y para celebrar este número tan redondo, vamos
a comenzar una nueva serie dedicada a una
tecnología que está, bueno, en boca de todos.
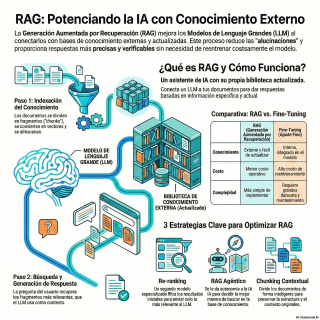
El RAG, Retrieval Augmented Generation.
Exacto.
Hoy vamos a ver qué es eso de
los RAG.
Porque, a ver, a menudo oímos que los
grandes modelos de lenguaje, los LLMs, a veces
se inventan cosas, ¿no?
O dan información que ya está anticuada.
Totalmente.
¿Y si hubiera una forma de darles, no
sé, como una biblioteca personalizada y que estuviera
siempre al día?
Pues es que has dado justo en el
clavo.
Ese es uno de los mayores desafíos de
los LLMs ahora mismo.
Claro.
Y RAG es precisamente la solución a ese
problema.
Es una arquitectura que permite que un modelo,
antes de responder, pueda consultar fuentes de información
muy específicas y, sobre todo, actualizadas.
Bien, pues vamos a desgranar esto.
La analogía de la biblioteca me parece muy,
muy potente.
Sí, funciona muy bien.
O sea, es como tener un asistente virtual
al que, en lugar de confiar solo en
lo que aprendió durante su entrenamiento hace meses
o años, que se queda viejo enseguida.
le damos acceso a una biblioteca en tiempo
real.
Eso es.
El proceso, a grandes rasgos, es bastante elegante
y se puede dividir como en tres pasos.
A ver.
Primero, la búsqueda.
El sistema recibe la pregunta y, en lugar
de lanzarse a responder, lo que hace es
usar esa pregunta para buscar en una base
de datos de conocimiento que hemos creado nosotros.
Una base de datos con nuestros propios documentos,
¿no?
PDFs, manuales, lo que sea.
Justo, lo que necesitemos.
Una vez que ha buscado, llega el segundo
paso, la recuperación.
De todo lo que encuentra, el sistema elige
sólo los fragmentos de información más relevantes, los
trocitos de texto que de verdad parecen contener
la respuesta.
Ok, busca, recupera lo importante y… El tercer
paso, la generación.
Y aquí es donde está la magia.
El modelo de lenguaje, el LLM, recibe dos
cosas, la pregunta original y, además, esos fragmentos
que hemos recuperado.
Ah, como contexto adicional.
Exacto.
Es como si le dijéramos, oye, responde a
esto, pero por favor, basándote en esta información
que te estoy dando ahora mismo.
Aquí es donde se pone realmente interesante para
mí.
Quiero entender bien ese viaje de los datos.
O sea, ¿cómo se construye esa biblioteca?
Claro.
Porque hablamos de PDFs, documentos de Notion, Excel.
¿Cómo transformamos, por ejemplo, un manual de 500
páginas en algo que una máquina pueda consultar
así de rápido?
Esa es la pregunta del millón, porque ahí
está el núcleo de un buen sistema RAG.
Hay dos fases muy claras.
La primera es la preparación de los datos.
Que se hace solo una vez, imagino.
Eso es, al principio.
Y lo primero dentro de esa preparación es
lo que llamamos chunking o fragmentación.
Trocear los documentos.
Exacto.
No le puedes dar al modelo las 500
páginas de golpe.
Sería un caos.
Así que lo divides en chunks, en fragmentos
más pequeños, más manejables.
¿Y hay un tamaño ideal para esos trozos?
¿Una frase?
¿Un párrafo?
Uf, no hay una fórmula mágica.
Ahí empieza un poco el arte de esto,
¿sabes?
Depende totalmente del caso de uso.
Un chunk muy pequeño puede no tener contexto.
Y uno muy grande puede tener demasiado ruido,
información que no viene al caso.
Justo.
El siguiente paso es clave, porque los modelos,
como bien decías, no entienden texto, entienden números.
Claro.
Así que hay que traducir.
Y eso se llama crear embeddings, o vectorizar.
Cada uno de esos chunks de texto se
convierte en una representación numérica, en un vector.
Como una coordenada en un mapa de significados,
¿no?
Me gusta esa analogía.
Es exactamente eso.
Cada trozo de texto tiene su propia coordenada.
Y estas coordenadas se guardan en una base
de datos especial, una base de datos vectorial.
Vale, que está pensada para buscar por similitud,
no por palabras exactas.
Eso es.
Hay soluciones muy complejas, pero muchas veces basta
con una base de datos postgres de toda
la vida con una extensión como PG Vector.
Entendido.
Entonces, esa es la fase de preparación.
La biblioteca está lista.
Ahora llega una pregunta de un usuario.
¿Qué pasa?
Pues se repite el proceso, pero a la
inversa.
La pregunta del usuario también se convierte en
un vector, en una coordenada en ese mismo
mapa.
Usando el mismo modelo de traducción, supongo.
El mismo, sí.
Y con esa coordenada, el sistema va a
la base de datos vectorial y le dice,
encuéntrame los 5 o 10 fragmentos que estén
más cerca de este punto.
Y esos fragmentos son los que se le
dan al ELM junto a la pregunta original.
Exacto.
Ese es el contexto.
Así es como aumentamos su conocimiento para que
dé una respuesta precisa y, sobre todo, basada
en nuestros datos.
Vale.
El proceso técnico queda claro.
Pero, vamos a la práctica.
¿Qué significa todo esto para una empresa?
Pues significa un cambio radical.
Piensa en un chatbot de servicio al cliente.
¿El que recomendaba productos de la competencia?
Ese mismo.
Con RAH, ese chatbot podría consultar en tiempo
real los manuales de producto y guiar a
una persona paso a paso para solucionar un
problema.
¿Citando la página exacta del manual?
Por ejemplo.
O un asistente para un equipo de médicos
que esté al día con las últimas investigaciones
publicadas la semana pasada, no hace dos años.
Un tutor virtual que pueda citar fuentes académicas
actualizadas para un estudiante.
Las aplicaciones son enormes.
Lo son.
Y las ventajas son muy claras.
Primero, la información está siempre actualizada.
Segundo, las respuestas son mucho más fiables.
Se reducen las alucinaciones a casi cero.
Y tercero, que para mí es crucial, son
respuestas verificables.
Se puede saber de dónde ha salido la
información.
Eso da una confianza brutal.
Y luego está el coste.
Reentrenar un modelo entero, lo que se conoce
como fine tuning, es lentísimo y carísimo.
Mientras que actualizar una base de datos es
mucho más ágil y barato.
Muchísimo más.
Ahora, bueno, tampoco es una solución mágica, tiene
sus desafíos.
Claro, no todo va a ser perfecto.
La implementación puede tener su complejidad técnica.
Y esa base de datos hay que mantenerla,
hay que actualizarla.
Y luego está la latencia.
El tiempo de respuesta, ¿no?
Porque hay más pasos.
Exacto.
Puede tardar un poquito más.
Y el coste por consulta.
Al pasarle más texto al modelo, puede ser
un poco más alto.
Hay que buscar un equilibrio.
Entendido.
O sea, el RAG básico es un punto
de partida genial.
Pero la conversación de verdad está en cómo
optimizarlo, ¿no?
Veo que a menudo se combinan varias estrategias.
Sí, aquí es donde entramos ya en la
parte avanzada.
Por ejemplo, una técnica muy común es el
re-ranking.
Reordenar, supongo.
Sí, es un enfoque de dos pasos.
En lugar de pedirle a la base de
datos los cinco mejores resultados, le pides, no
sé, 50.
Pero, espera, darle 50 fragmentos al LLM no
es contraproducente.
¿Lo puedes aturar?
Claro.
Por eso está el segundo paso.
Se usa un modelo mucho más pequeño y
especializado, un re-ranker, cuya única misión es coger
esos 50 fragmentos y reordenarlos por relevancia real.
Ah, vale.
Y solo después de ese filtro le pasas
al LLM grande los cinco mejores de verdad.
La calidad de la respuesta mejora una barbaridad.
Inteligente.
Primero una búsqueda amplia y luego un filtro
preciso.
Me gusta.
También he leído sobre la fragmentación consciente del
contexto.
Context-aware chunking.
Exacto.
Va de la mano con lo que decíamos
antes.
No vale con cortar un texto cada mil
caracteres y ya.
Hay que respetar la estructura.
Hay que buscar los límites naturales del documento.
El final de un párrafo, un título, el
pie de una tabla… Se trata de preservar
el sentido.
Es que la calidad de lo que metes
en la base de datos tiene un impacto
directo en la calidad de lo que sacas.
Basura entra, basura sale.
De toda la vida.
Así es.
Luego, hay otra estrategia muy potente.
El agentic RAG.
El ra-agéntico.
Esto ya suena a ciencia ficción.
Bueno, un poco.
Es darle al sistema la capacidad de razonar
sobre cómo tiene que buscar.
O sea, que no siga siempre los mismos
pasos.
Eso es.
El agente analiza la pregunta y decide.
Si es una pregunta muy concreta, como cuál
fue el beneficio en 2023, pues hace una
búsqueda muy específica.
Pero si es algo más abierto, como cuáles
son los riesgos estratégicos de la empresa.
Pues a lo mejor decide que es más
útil recuperar y leerse el informe anual completo,
para tener una visión global.
Es más flexible, pero también menos predecible.
Claro, hay que programarlo con mucho cuidado para
que tome buenas decisiones.
Desde luego.
Y ya por último, una que a mí
me parece fascinante, que es el fine tuning
de los embeddings.
O sea, afinar al traductor.
Exacto.
El modelo que convierte texto en vectores suele
ser genérico, pero podemos reentrenarlo con datos de
un dominio muy específico, legal, médico, financiero, para
que entienda la jerga y los matices de
ese campo.
Y lo que se consigue es que un
modelo de embeddings pequeño, pero muy especializado, supera
a modelos gigantescos y genéricos en esas tareas
concretas.
La comprensión del dominio es mucho más profunda.
Es increíble.
Esto me recuerda a un ejemplo que leí.
Entrenar un modelo no para que busque por
similitud de significado, sino por sentimiento.
Sí, es un caso de uso genial.
De forma que una frase como el pedido
llegó roto se considere muy similar a la
web siempre dice que no hay stock.
No porque usen las mismas palabras, sino porque
ambas expresan frustración.
Ese es el poder de la técnica.
Te permite redefinir qué significa similar para tu
problema.
La personalización es total.
Entonces, si lo unimos todo, queda claro que
el RAGE no es solo una mejora técnica,
¿no?
Es un paso hacia una inteligencia artificial, no
sé, más transparente, más fiable.
Totalmente.
Es que pasamos de una IA que es
como un sabelotodo que a veces patina… ¿Y
que no sabes de dónde saca las cosas?
A una IA que se comporta como una
investigadora experta, que consulta, contrasta y cita sus
fuentes.
Y para una empresa o un gobierno, eso
es infinitamente más valioso.
Por eso se está convirtiendo en la arquitectura
por defecto para resolver problemas del mundo real.
Y esto me lleva a una reflexión final,
una pregunta que me queda en el aire.
A ver, dispara.
Todas estas estrategias se centran en encontrar información
que es semánticamente similar a una pregunta.
Pero, ¿qué pasa cuando la respuesta más útil,
la más creativa, no está en un pasaje
que suena parecido, sino en un dato que
a primera vista no parece tener relación?
¿Cómo podrían los futuros sistemas aprender a dar
esos saltos, a conectar piezas de información dispares
dispares para resolver un problema como hace la
intuición de una persona experta.
Llegamos al final por hoy.
El podcast de BIMPRAXIS está dirigido por un
humano, Julio Pablo Vázquez.
Te esperamos en el próximo episodio.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.
Música