Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:09
0:15
0:20
0:23
0:26
0:28
0:37
0:40
0:43
0:45
0:48
0:49
0:51
0:54
0:57
1:01
1:02
1:04
1:04
1:07
1:09
1:11
1:14
1:15
1:16
1:18
1:20
1:21
1:21
1:24
1:27
1:30
1:33
1:36
1:38
1:39
1:41
1:43
1:45
1:45
1:47
1:49
1:50
1:52
1:55
1:56
1:58
1:59
2:02
2:04
2:05
2:07
2:08
2:10
2:12
2:15
2:18
2:19
2:22
2:24
2:26
2:27
2:29
2:32
2:33
2:35
2:37
2:40
2:42
2:43
2:45
2:47
2:49
2:51
2:52
2:54
2:56
2:57
3:00
3:00
3:02
3:04
3:06
3:07
3:08
3:11
3:12
3:12
3:15
3:17
3:17
3:21
3:23
3:24
3:26
3:26
3:28
3:29
3:31
3:34
3:36
3:36
3:40
3:41
3:42
3:45
3:46
3:50
3:50
3:52
3:56
3:59
4:00
4:04
4:05
4:06
4:07
4:08
4:11
4:12
4:15
4:18
4:19
4:22
4:23
4:26
4:28
4:29
4:32
4:32
4:33
4:34
4:37
4:39
4:40
4:43
4:45
4:47
4:47
4:48
4:50
4:52
4:53
4:56
4:59
5:02
5:02
5:04
5:07
5:08
5:09
5:11
5:13
5:15
5:18
5:19
5:21
5:21
5:24
5:26
5:29
5:32
5:34
5:37
5:37
5:38
5:39
5:40
5:42
5:45
5:48
5:48
5:52
5:54
5:54
5:58
5:58
6:01
6:04
6:06
6:08
6:09
6:11
6:13
6:14
6:15
6:18
6:20
6:22
6:24
6:26
6:28
6:28
6:31
6:33
6:36
6:38
6:43
6:43
6:44
6:46
6:48
6:50
6:53
6:55
6:56
6:57
6:59
7:02
7:05
7:07
7:08
7:11
7:13
7:14
7:16
7:18
7:21
7:23
7:23
7:25
7:29
7:30
7:31
7:33
7:35
7:38
7:41
7:41
7:42
7:44
7:47
7:49
7:52
7:53
7:53
7:56
7:58
8:01
8:04
8:05
8:06
8:07
8:09
8:13
8:13
8:14
8:14
8:14
8:14
8:16
8:20
8:22
8:23
8:25
8:26
8:28
8:28
8:31
8:33
8:35
8:37
8:40
8:41
8:42
8:44
8:47
8:49
8:51
8:52
8:54
8:57
8:59
9:01
9:04
9:07
9:10
9:11
9:14
9:15
9:18
9:19
9:22
9:23
9:25
9:27
9:30
9:32
9:34
9:38
9:41
9:42
9:46
9:49
9:50
9:53
9:55
9:56
9:59
10:01
10:02
10:05
10:07
10:09
10:09
10:10
10:12
10:15
10:17
10:20
10:23
10:26
10:28
10:30
10:32
10:35
10:37
10:40
10:42
10:45
10:46
10:47
10:50
10:51
10:53
11:05
11:07
11:18
11:20
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Buenas, estamos ya en el episodio 45 y
seguimos con la serie Herramientas Open Source Gratuitas,
relacionadas, claro, con la IA.
Hoy traemos una que se llama FireCrowl y
ahora os explicamos qué es esto.
Bienvenidos al podcast de BIMPRAXIS.
Vamos a empezar, como siempre, por el principio.
Cualquiera que esté metido en construir aplicaciones de
inteligencia artificial sabe que todo, absolutamente todo, se
basa en los datos.
Son el combustible, sí.
Exacto.
Pero claro, conseguir esos datos en la web
suele ser el primero y el mayor obstáculo.
Uf, y tanto.
Hay que extraerlos, luego limpiarlos, ponerlos en un
formato que un...
una IA pueda entender.
Es un trabajo enorme.
Y ahí es donde entran herramientas como la
de hoy.
Justo ahí.
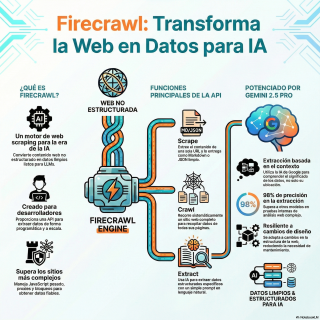
Ahí es donde entra FireCrowl.
En esencia, es una API, una interfaz de
programación, que está pensada para desarrolladores.
Su misión es muy clara.
Convertir cualquier sitio web en datos limpios y
listos para un modelo de lenguaje grande, un
LLM.
O sea, que no es la típica herramienta
visual de apuntar y hacer clic.
Para nada.
Un motor.
Uno muy potente.
Para sacar información de la web de forma
programada.
Vale, vamos a desgranar esto un poco.
La idea principal, entonces, es que se encarga
de las partes más frustrantes de lo que
llamamos web scraping, ¿no?
Eso es.
Por ejemplo, lidiar con esas webs modernas que
están llenas de JavaScript y cargan el contenido
poco a poco.
Que son un dolor de cabeza.
Totalmente.
O gestionar los proxys para que no te
bloqueen el acceso a la primera de cambio.
Se encarga de toda esa fontanería.
De hecho, se centra en cuatro funciones principales.
A ver.
La primera sería scrape, que es raspar.
Le das una única página web y te
saca el contenido.
¿Y cómo te lo devuelve?
Pues te lo da como un archivo Markdown
ya limpio o en formato JSON, ya estructurado.
Vale.
Luego está crawl, que es rastrear.
Esto ya es para recorrer un sitio web
entero, todas sus páginas, y recopilar los datos
del dominio completo.
Entendido.
La tercera es map, mapear.
Te da un mapa rápido de todas las
URLs de un sitio, para tener una visión
general de la estructura.
¿Y la última?
La última es extract.
Y esta es la más avanzada, porque está
impulsada por IA.
Saca datos muy específicos y estructurados de una
página.
Has mencionado lo del Markdown limpio y me
parece un detalle interesante.
Porque puede parecer algo menor, pero es bastante
importante, ¿verdad?
Es fundamental.
Reduce drásticamente la cantidad de tokens que envías
al modelo de IA.
Claro.
¿Y eso se traduce directamente?
En un ahorro de costes, en las llamadas
a la API.
Y, muchas veces, también en un mejor rendimiento
del modelo, porque le das la información mucho
más clara.
Aquí es donde la cosa se pone realmente
interesante.
En esa función extract.
¿Totalmente?
La extracción de datos de toda la vida
se basaba en apuntar a elementos muy concretos
del diseño de una web, ¿no?
Exacto.
Y si un desarrollador cambiaba algo, por mínimo
que fuera… Adiós a Scraper.
Se rompía.
Era increíblemente frágil.
Una pesadilla de mantener.
Y la función extract de Firecrawl soluciona eso.
¿Cómo?
Pues lo soluciona cambiando el enfoque.
En lugar de reglas fijas, usa inteligencia artificial.
El desarrollador le da una URL y una
instrucción en lenguaje natural.
Algo como, obtén los nombres, cargos y correos
del equipo directivo.
Ah, vale.
Le hablas como una persona.
Justo.
Y, además, defines la estructura JSON en la
que quieres recibir esos datos.
Y la IA de Firecrawl analiza la persona.
Entiende lo que le pides, encuentra la información
y te la da ya estructurada.
La ventaja principal, entonces, es la resiliencia.
Esa es la palabra.
Como entiende el significado de los datos, se
puede adaptar a los cambios de diseño sin
tener que reescribir el código.
Y sabemos qué tecnología hay detrás de esto,
¿verdad?
¿Qué motor usa?
Sí, sí, que lo sabemos.
Usan Gemini 2 .5 Pro, de Google, para
potenciar este motor de extracción.
Vaya.
De hecho, el cofundador de Firecrawl, Eric Ciarla,
dijo que este modelo fue lo que… Hizo
factible todo el proyecto.
¿Ah, sí?
Sí.
Parece que otros modelos no manejaban bien la
complejidad del contenido web real.
¿Y qué tal la precisión?
Pues en sus pruebas internas dicen que Gemini
2 .5 Pro alcanzó una precisión del 98%.
Un 98 % es una cifra altísima.
Sí.
Puede ser un poco confuso.
No hay un único modelo, sino dos.
¿Dos sistemas diferentes?
Exacto.
Y hay que entender los dos para calcular
los costes reales.
Por un lado, está el modelo de credibilidad.
Este se aplica a las funciones básicas de
scrape y crawl.
El más predecible, imagino.
Sí.
Una llamada a la API o una página
rastreada suele costar un crédito.
Los planes van desde uno gratuito con 500
créditos, que se dan una sola vez, hasta
planes de pago como el hobby, por 19
dólares, que te da 3 .000 créditos al
mes.
Vale.
Hasta ahí bien.
¿Y el segundo modelo?
Pues aquí está el detalle crucial.
La función de extracción con IA, la de
extract, no utiliza el sistema de créditos.
Ah.
Se factura aparte, basándose en tokens, muy parecido
a cómo pagas por las APIs de OpenAI
o Anthropic.
O sea que es una suscripción completamente separada.
Completamente.
Si alguien contrata, no sé, el plan estándar
para raspar datos, pensando que lo tiene todo…
Se va a llevar una sorpresa.
Necesita comprar un plan adicional solo para la
función de extracción.
Es un detalle que es fácil pasar por
alto, la verdad, y que puede generar costes
inesperados.
Desde luego.
Los planes para extract empiezan en 89 dólares
al mes, por 18 millones de tokens al
año, y de ahí para arriba.
Entonces, ¿qué significa todo esto?
Que la suscripción a Firecrawl es en realidad
solo el punto de partida.
Correcto.
Al construir una solución de IA personalizada, hay
otros costes, y son significativos.
Como por ejemplo… El tiempo de ingeniería.
Suele ser el mayor gasto.
Necesitas desarrolladores cualificados para construir la aplicación, probarla,
mantenerla.
Claro.
Las horas de desarrollo.
Luego, los costes del LLM.
Firecrawl te da los datos, pero todavía tienes
que pagar a un proveedor como OpenAI o
Anthropic para que los procesen.
Y la infraestructura, donde corre todo.
Por supuesto.
Los costes de infraestructura.
Necesitas un sitio donde alojar la aplicación, bases
de datos vectoriales como Pinecone, etc.
Y también he leído que puede haber problemas
de escalabilidad.
Sí, algunos usuarios han señalado que en rastreos
a gran escala es muy fácil agotar los
créditos.
Y eso te puede llevar a tarifas por
exceso de uso que disparan la factura.
En resumen, Firecrawl te da las materias primas,
y de excelente calidad por lo que parece.
Sí.
Pero la empresa todavía tiene que construir la
fábrica, desplegarla y mantenerla para usar esos datos.
Esa es la disyuntiva.
Exactamente.
Las fuentes lo comparan con un enfoque de
plataforma todo en uno.
Es la diferencia entre comprar las piezas para
montar el coche… O comprar el coche ya
fabricado.
Justo.
Son dos filosofías distintas.
Una es para quien quiere construir algo a
medida, desde cero, y la otra es para
quien busca resolver un problema de negocio concreto
de forma rápida.
Vale.
Entonces, para dejarlo claro, ¿quién es el usuario
ideal de esta herramienta?
Es ideal para equipos técnicos que están construyendo
aplicaciones de IA personalizadas desde cero.
¿Desarrolladores?
¿Ingenieros?
Sí.
De hecho, se integra con herramientas que ya
usan, como Landchain, donde funciona como un cargador
de documentos.
Sí.
De hecho, se integra con herramientas que ya
usan, como Landchain, donde funciona como un cargador
de documentos.
Además, al ser de código abierto, pues el
código es transparente y la comunidad puede contribuir.
O incluso puedes autoalojar la herramienta en tus
propios servidores.
Que eso para muchas empresas es clave.
Fundamental.
¿Y para qué se está usando en el
mundo real?
¿Qué casos de uso destacan?
Pues… son bastante variados.
Uno muy claro es crear asistentes de IA
más inteligentes.
Alimentar chatbots con contenido web que sea preciso
y en tiempo real.
Vale.
Otro es el enriquecimiento de leads.
Mejorar los datos de ventas con información extraída
de la web sobre posibles clientes.
Eso es muy potente para un equipo comercial.
Muchísimo.
Y también para la investigación profunda.
Para extraer información exhaustiva para análisis de mercado
o para temas académicos.
Y no hay que olvidar que, por debajo,
gestiona automáticamente tareas complejas, como el manejo de
proxies, contenido bloqueado por Javascript, e incluso puede
analizar archivos PDF y 12x que encuentre en
la web.
Entonces, como conclusión, Firecrawl es una herramienta que,
además de ser una herramienta potente y muy
bien diseñada, pero para una tarea muy, muy
específica.
Sí, convertir la web en datos estructurados para
los modelos de IA.
Si se cuenta con el equipo de ingeniería,
con el presupuesto y con el tiempo para
construir una solución a medida, parece una pieza
excelente para el puzzle tecnológico.
Pero si el objetivo es resolver un problema
de negocio, rápido y fiable, es fundamental entender
el coste y el esfuerzo total, no sólo
el precio de la herramienta.
La elección depende enteramente del objetivo final.
Y para terminar, un último apunte que invita
a pensar en el futuro.
Firecrawl está experimentando con un framework de agentes
llamado Fire1.
Ah, sí.
Usa Gemini 2 .5 Pro para interpretar la
intención del usuario y navegar por la web
de forma autónoma.
Y esto apunta a un futuro muy interesante.
Ya no sólo pedimos datos de una página,
sino que le damos a una IA un
objetivo.
Exacto.
Y que ella averigüe por sí misma, cómo
navegar, hacer clic y extraer lo que necesita.
La pregunta que queda en el aire es,
¿qué pasaría si en lugar de programar un
scraper, simplemente le diéramos a una IA un
objetivo de negocio y la dejáramos navegar por
la web para cumplirlo?
Y así hemos llegado al final por hoy.
Os recordamos que detrás de las voces sintéticas
que se escuchan en estos episodios, sí, son
generadas por IA, en concreto por Notebook LM,
pues se encuentra un humano con duodeno, pulgares
y algún michelin, entre otras cosas.
Estamos hablando de Julio Pablo Vázquez, el responsable
de elegir los temas, el enfoque y hacer
de hombre orquesta.
Si se escucha algún error, pedimos disculpas en
su nombre, porque lo más probable es que
se trate de un error humano.
Hasta la próxima, amigos.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.