Buenas, esto es BIMPRAXIS, el podcast donde el BIM se encuentra con la inteligencia artificial.
Download transcript (.srt)
0:09
0:20
0:28
0:29
0:45
0:50
0:56
1:01
1:03
1:09
1:12
1:13
1:20
1:27
1:28
1:34
1:39
1:42
1:48
1:54
2:00
2:00
2:05
2:07
2:12
2:18
2:21
2:29
2:34
2:35
2:42
2:49
2:50
2:51
2:55
3:02
3:10
3:12
3:15
3:17
3:20
3:25
3:27
3:34
3:40
3:41
3:41
3:46
3:53
3:58
4:01
4:02
4:07
4:11
4:16
4:23
4:27
4:37
4:39
4:41
4:41
4:45
4:50
4:53
4:56
4:59
5:03
5:06
5:07
5:11
5:16
5:20
5:26
5:28
5:32
5:33
5:38
5:40
5:43
5:48
5:51
5:54
5:58
6:00
6:04
6:08
6:10
6:13
6:16
6:21
6:24
6:28
6:30
6:34
6:37
6:40
6:43
6:47
6:51
6:55
6:57
6:57
7:00
7:03
7:07
7:10
7:12
7:16
7:20
7:25
7:27
7:30
7:32
7:36
7:37
7:39
7:42
7:45
7:48
7:52
7:56
8:00
8:05
8:06
8:07
8:08
8:13
8:14
8:18
8:21
8:25
8:30
8:31
8:33
8:37
8:40
8:43
8:44
8:48
8:50
8:53
8:55
8:59
9:02
9:04
9:07
9:10
9:14
9:17
9:19
9:21
9:23
9:25
9:30
9:32
9:37
9:38
9:40
9:45
9:47
9:51
9:56
10:01
10:02
10:05
10:06
10:07
10:12
10:14
10:18
10:19
10:21
10:26
10:28
10:33
10:37
10:41
10:42
10:46
10:48
10:50
10:54
10:57
10:59
11:01
11:06
11:07
11:10
11:13
11:17
11:21
11:22
11:25
11:30
11:34
11:37
11:40
11:45
11:49
11:53
11:54
11:57
12:03
12:04
12:05
12:06
12:07
12:08
12:09
12:12
12:17
12:22
12:28
12:32
12:33
12:37
12:44
12:50
12:57
13:02
13:08
13:14
13:20
13:25
13:30
13:32
13:38
13:43
13:46
13:51
13:55
14:00
14:02
14:09
14:13
14:19
14:23
14:27
14:32
14:32
14:39
14:42
14:48
14:52
15:06
15:12
15:20
Exploramos la ciencia, la tecnología y el futuro desde el enfoque de la arquitectura, ingeniería y construcción.
¡Empezamos!
Y si el componente fundamental de la inteligencia artificial moderna, ese ladrillo, por así decirlo, con el que se construye casi todo,
tuviera una alternativa radicalmente distinta y quizás mucho más potente.
Es una pregunta potentísima, sí, y nos lleva directos al centro del análisis de hoy.
Porque a veces, para dar un salto adelante, hay que cuestionar los cimientos.
Y hoy vamos a hablar precisamente de eso.
Además, es que es una conversación que encaja a la perfección en la serie especial que estamos haciendo para BIMPRAXIS,
los papers que cambiaron la historia de la IA.
Totalmente. Buscamos justo eso.
Esos documentos que no solo mejoran lo que ya hay, sino que abren puertas a formas completamente nuevas de pensar.
Y el de hoy es un candidato perfecto, vamos. Es casi una provocación al statu quo del deep learning.
Totalmente.
Hoy nos vamos a sumergir en un artículo muy, muy reciente que está generando un debate enorme.
Se titula CAN, Colmogoros Arnold Networks.
Está liderado por Ziming Liu y su equipo.
Y la primera versión es del 30 de abril de 2024. O sea, que está recién salido del horno.
Así es. Y nuestra misión hoy es desentrañar qué son exactamente estas redes CAN.
¿Por qué se proponen como una alternativa a los omnipresentes perceptrones multicapa, a los MLPs?
Claro.
Y sobre todo, ¿qué implicaciones podría tener este cambio de paradigma para el futuro del deep learning?
Vale, vamos a desgranar esto.
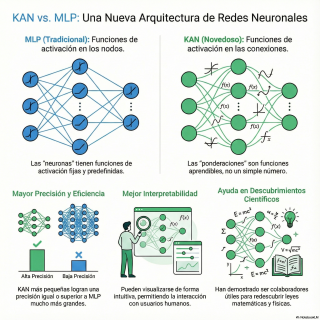
Para entender por qué es tan rompedor, quizá tengamos que recordar un poco cómo funcionan las redes.
El modelo actual se llama perceptrón multicapa, o MLP.
Es el caballo de batalla de la IA actual.
Casi todo lo que conocemos, desde los modelos que reconocen imágenes hasta los grandes modelos de lenguaje, tiene MLPs en su núcleo.
La analogía que siempre se usa, y a mí me parece muy buena, es la de las piezas de Lego.
Sí.
Los MLPs construyen a inteligencia apilando miles o millones de piezas muy simples.
Cada pieza, cada neurona, tiene una función fija, predeterminada, que llamamos función de activación.
Eso es.
Siempre hace lo mismo.
Es como un interruptor que se enciende o se apaga a partir de cierto punto.
La complejidad, la inteligencia del modelo, surge de la inmensa cantidad de estas piezas simples y de cómo se organizan en capas.
La clave entonces, y esto el abstract del paper lo deja clarísimo, es que en los MLPs esas funciones en las neuronas son fijas.
Se elige una, como la famosa...
La famosa RELU, y se usa en toda la capa.
Y este ha sido el dogma durante décadas.
Y funciona, ¿eh? No hay duda de que funciona.
El problema es que este diseño tiene limitaciones importantes.
Una es la eficiencia.
A menudo se necesitan redes gigantescas con miles de millones de parámetros para resolver problemas complejos.
Y la otra, que es la que frustra en el día a día, la interpretabilidad.
¿Totalmente?
¿Totalmente?
Es que es una frustración que cualquiera que trabaje con estos modelos conoce.
Te pasas semanas entrenando algo, funciona de maravilla, y luego te preguntan, ¿por qué dio esa respuesta?
Y te tienes que encoger de hombros y decir, pues, porque las matemáticas funcionan.
Exacto. Se convierte en la famosa caja negra.
Sí.
Sabemos que funciona, pero no entendemos cómo toma sus decisiones, qué razonamiento interno sigue.
Y esa opacidad es un problema enorme en campos críticos.
Como la medicina o las finanzas, donde necesitas poder entender las decisiones de la máquina.
Vale. Entonces tenemos un sistema que funciona, pero es masivo, caro de entrenar y opaco.
Y si el problema es que no vemos lo que pasa dentro de los nodos.
La solución que proponen estos autores es hacer que los nodos sean casi irrelevantes y que toda la magia ocurra en los cables que los unen.
Has dado en el clavo.
Es que es un cambio de perspectiva total.
Es un cambio de perspectiva total.
El paper de las Kahn's plantea una idea radical.
Y si en lugar de tener la inteligencia dentro de los nodos, la pusiéramos en las conexiones.
¿Y esta idea de dónde sale?
¿Es algo completamente nuevo o se basa en algo que ya existía?
No surge de la nada. Y eso es lo fascinante.
Los autores se inspiran en un principio matemático bastante profundo.
El teorema de representación de Kolmogorov-Arnold.
Ah, vale.
Sin entrar en la matemática pura y dura, que es muy compleja,
lo que este teorema sugiere es que cualquier función continua, por enrevesada que sea,
se puede representar como una suma y composición de funciones más simples.
Las Kahn's son en esencia un intento de llevar esta idea a la práctica en una red neuronal.
O sea que la base teórica lleva ahí bastante tiempo,
pero ellos han encontrado la forma de convertirla en una arquitectura que funciona.
Precisamente.
La diferencia fundamental, y el artículo lo explica de forma cristalina, es esta.
Mientras los MLPs tienen funciones,
de activación fijas y simples, en los nodos,
las Kahn's tienen funciones de activación aprendibles y complejas en las aristas.
Espera, espera. Esto es importante.
En un MLP normal, el peso es solo un número, ¿no?
Un multiplicador que dice si la conexión es más fuerte o más débil.
Correcto. Un simple número.
La transformación de la señal ocurre después, en el nodo de destino.
En una Kahn, la propia conexión ya no es un número.
La conexión es una función matemática que aprende y se aprende,
se adapta durante el entrenamiento.
Y de repente lees una frase en el abstract que te rompe los esquemas.
Dicen, literalmente, las Kahn's no tienen pesos lineales en absoluto.
Y te quedas pensando, ¿cómo que no?
O sea, ¿han quitado el componente más básico de una red neuronal?
Es una declaración potentísima.
Significa que cada conexión no es solo un potenciómetro que sube o baja una señal,
sino que es un pequeño procesador en sí mismo.
Concretamente, lo que usan es una función llamada spline.
¿Vale? Has dicho la palabra técnica.
¿Qué es una spline, en términos que podamos entender todos?
A ver, piensa en una de esas reglas de dibujo flexibles que se usaban antes.
Una spline no es más que una serie de pequeños trozos de curvas sencillas,
unidas de forma suave.
¡Ajá!
La idea es que puedes doblar y torcer esa regla
para que se ajuste a cualquier contorno que quieras.
Pues, en una Kahn, cada conexión es una de esas reglas flexibles.
La red aprende a doblar cada una de estas splines
hasta que su forma representa a la perfección
la relación matemática entre las dos neuronas que conecta.
La analogía de los cables que usábamos antes ahora cobra todo el sentido.
Un MLP tiene cables rígidos que solo transmiten una señal con más o menos fuerza.
Mmm.
Y una Kahn tiene cables flexibles y programables
que no solo transmiten la señal,
sino que la transforman de maneras complejas mientras viaja de un punto a otro.
Exacto.
La inteligencia, la complejidad,
se ha desplazado de los nodos a las conexiones.
Los nodos en una Kahn son increíblemente simples.
A menudo solo suman las señales que les llegan.
Toda la carga del aprendizaje recae en esas splines de las conexiones.
Vale, si mueves la inteligencia, las conexiones y las haces tan flexibles,
la intuición me dice que eso tiene que tener dos efectos enormes.
Primero, que necesitas menos piezas, porque cada pieza es mucho más potente.
Eso es.
Y segundo, que puedes mirar dentro de esa conexión,
Eso es. Y segundo, que puedes mirar dentro de esa conexión,
ver la forma que ha aprendido y entender qué está haciendo.
¿Es eso lo que prometen?
Has descrito perfectamente las dos grandes promesas del paper.
La primera es la precisión y la eficiencia.
Citan directamente que Kahn's mucho más pequeñas
pueden lograr una precisión comparable o mejor que MLPs mucho más grandes.
Esto es importantísimo.
Si se confirma a gran escala,
significaría que podríamos obtener los mismos o mejores resultados
con modelos que requieren muchísimos menos recursos.
Menos coste, menos consumo energético.
Y va más allá.
El paper también habla de leyes de escalado neuronal más rápidas.
Espera un momento, eso es clave.
Porque el gran problema de los modelos gigantes
es que llega a un punto de rendimientos decrecientes.
Tienes que duplicar el tamaño del modelo para obtener una mejora mínima.
Sugieren que las Kahn's rompen con eso.
Esa es la teoría que proponen, ¿sí?
Que si a un MLT y a una Kahn's les das
un doble de datos, la Kahn, en teoría,
aprenderá más y mejorará su rendimiento de forma más acelerada.
Es una cuestión de eficiencia en el aprendizaje.
Vale, esa es la primera gran ventaja.
Más con menos.
Pero para mí la verdadera bomba es la segunda.
La interpretabilidad.
El paper afirma que las Kahn's pueden visualizarse intuitivamente.
Si cada conexión es una función visible,
significa que podríamos literalmente ver cómo una red ha aprendido el concepto de
Kahn's.
Es exactamente ese nivel.
Y lo fascinante es que no se quedan en la teoría, muestran una aplicación práctica
para demostrarlo.
Cuentan en el abstract que usaron Kahn's como colaboradoras para que científicos,
tanto matemáticos como físicos, pudieran redescubrir leyes fundamentales de la naturaleza.
O sea, no es sólo que podamos ver lo que hace la red, sino que lo que vemos tiene
sentido científico.
Ida entre la salinidad y la temperatura a cierta profundidad.
Increíble.
La Kahn's.
No sólo predijo, sino que le dio una nueva pista sobre la física del océano.
Es un salto cualitativo enorme.
Es pasar de una herramienta de predicción opaca a una herramienta de descubrimiento
científico.
Pensemos en la medicina.
Un MLP te puede dar un diagnóstico con un 99% de acierto, pero ningún médico lo usaría
porque es una caja negra.
Con una Kahn's podrías visualizar las funciones y descubrir que una conexión ha modelado
una curva que relaciona tres biomarcadores de una forma que nadie había descrito.
No sólo tienes un diagnóstico, tienes una nueva hipótesis para investigar la causa
de la enfermedad.
Todo esto suena casi demasiado bueno para ser verdad.
Pero seamos escépticos un segundo.
¿Cuál es la trampa?
Entrenar una función completa en cada conexión en lugar de un simple número debe tener
un coste computacional brutal, ¿no?
Esa es la pregunta del millón.
Y el paper es honesto al respecto.
Si bien el modelo final es más eficiente, el proceso de entrenamiento puede ser más
exigente.
Otimizar millones de curvas flexibles es un desafío.
Claro, puede ser más lento.
Es un área de investigación muy activa ahora mismo, cómo hacer este entrenamiento tan
eficiente como el de los MLPs.
Es un trade-off.
Y tengo otra duda.
Con tanta flexibilidad en cada conexión, ¿no corren el riesgo de memorizar los datos
de entrenamiento en lugar de aprender patrones generales?
El sobreajuste, el famoso overfitting, me parece un peligro.
Es un riesgo muy real.
Los autores lo saben, y proponen técnicas de regularización específicas que básicamente
penalizan a las splines que se vuelven demasiado complejas o ruidosas.
Es como decirle a la red, intenta encontrar la curva más simple posible que explique
los datos.
Pero, sin duda, calibrar esto será uno de los grandes retos.
Entonces, si intentamos resumir el cambio fundamental, es pasar de una arquitectura
donde la complejidad reside en apilar verticalmente nodos altos, a una arquitectura donde la complejidad
reside en apilar verticalmente nodos altos, a una arquitectura donde la complejidad reside
en apilar verticalmente nodos altos, a una arquitectura donde la complejidad reside en apilar
verticalmente nodos altos.
Y desde una arquitectura donde la complejidad reside en apilar verticalmente nodos altos,
a una architectura donde la complejidad reside en apilar verticalmente nodos altos, o sea,
de un código de datos más o menos simples, a una donde la complejidad está en las propias
conexiones, que son inteligentes, flexibles y sobre todo interpretables.
Si conectamos esto con el panorama general, el artículo posiciona a las CANs como alternativas
prometedoras a los MLPs y hay que recalcar la importancia de esa frase.
Los MLPs no son una parte más de la IA, son el cimiento de casi todo.
Claro.
Desde la visión por computador, hasta los gigantescos LLMs, todos
dependen de los MLPs. Por lo tanto, si las CANS demuestran ser una alternativa viable, no estaríamos
hablando de una mejora incremental, estaríamos hablando de un posible cambio de los cimientos
de todo el edificio. Es una analogía muy buena y el artículo no lo presenta como un producto final,
sino como una nueva vía de investigación. La conclusión es muy clara, las CANS abren
oportunidades para seguir mejorando los modelos de Deep Learning actuales. Lo que nos han dado es
un nuevo tipo de ladrillo y ahora la comunidad tiene que ver qué se puede construir con él.
Así que, para recapitular los puntos clave, las CANS proponen una arquitectura novedosa,
inspirada en un teorema matemático de hace décadas. Mueven el aprendizaje de los nodos
a las conexiones, usando funciones flexibles en lugar de simples pesos.
Y las grandes promesas son dos.
Una mayor precisión con modelos mucho más pequeños. Y, quizás, lo más revolucionario,
una interpretabilidad, que podría convertir a las redes neuronales en colaboradoras para
el descubrimiento científico. Exacto.
Un cambio de paradigma que ataca de raíz dos de los mayores problemas del Deep Learning actual,
el tamaño y la opacidad. Y esto me lleva a la reflexión final.
Has mencionado que la base de todo esto es un teorema matemático que tiene décadas de antigüedad.
Así es. El teorema de Kolmomoroff-Arnold,
en el que se basan estas redes, existe desde la década de 1950. La base matemática ha estado ahí,
esperando en un cajón, durante más de 70 años. Increíble.
Esto nos obliga a preguntarnos qué otras ideas antiguas, qué otros teoremas olvidados en viejos
libros de texto, podrían estar esperando simplemente las herramientas computacionales
adecuadas para revolucionar la inteligencia artificial del mañana.
Es una idea fascinante. La próxima gran revolución podría no venir de una idea
completamente nueva.
Sino de una vieja idea vista con nuevos ojos. Y con esa reflexión cerramos nuestro análisis de hoy.
Un placer como siempre.
Pero nuestro viaje por los artículos que definen la inteligencia artificial no ha hecho más que empezar.
Mañana analizaremos otro paper que marcó un antes y un después en este campo.
Una exploración fascinante que no se pueden perder.
Y hasta aquí el episodio de hoy. Muchas gracias por tu atención.
Esto es...
BIMPRAXIS. Nos escuchamos en el próximo episodio.