Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:10
0:15
0:20
0:23
0:26
0:28
0:37
0:38
0:41
0:43
0:45
0:47
0:48
0:49
0:50
0:53
0:55
0:58
0:59
1:01
1:03
1:05
1:07
1:08
1:11
1:13
1:14
1:17
1:17
1:19
1:21
1:24
1:27
1:29
1:33
1:35
1:37
1:40
1:41
1:43
1:46
1:48
1:49
1:52
1:56
1:58
1:59
2:01
2:02
2:03
2:06
2:08
2:10
2:14
2:16
2:18
2:20
2:22
2:24
2:25
2:28
2:29
2:31
2:34
2:35
2:37
2:40
2:42
2:43
2:45
2:48
2:50
2:53
2:55
2:55
2:57
2:58
2:59
3:01
3:05
3:06
3:09
3:12
3:12
3:14
3:15
3:17
3:19
3:22
3:23
3:24
3:26
3:28
3:28
3:30
3:32
3:34
3:36
3:38
3:39
3:41
3:45
3:47
3:48
3:50
3:53
3:56
3:59
4:01
4:02
4:03
4:04
4:06
4:07
4:09
4:12
4:12
4:14
4:17
4:19
4:20
4:21
4:23
4:23
4:26
4:28
4:30
4:30
4:33
4:34
4:35
4:36
4:37
4:39
4:41
4:42
4:44
4:46
4:48
4:51
4:53
4:56
4:57
5:00
5:02
5:03
5:04
5:06
5:10
5:11
5:13
5:15
5:16
5:17
5:20
5:22
5:23
5:25
5:26
5:29
5:30
5:33
5:34
5:35
5:38
5:40
5:42
5:45
5:47
5:48
5:51
5:53
5:55
5:58
6:01
6:04
6:06
6:07
6:09
6:10
6:11
6:12
6:15
6:17
6:19
6:21
6:24
6:25
6:27
6:29
6:31
6:33
6:34
6:35
6:36
6:38
6:40
6:41
6:43
6:44
6:48
6:49
6:49
6:51
6:53
6:56
6:58
6:59
7:02
7:04
7:08
7:10
7:12
7:15
7:16
7:18
7:20
7:22
7:23
7:26
7:28
7:31
7:33
7:34
7:34
7:37
7:39
7:40
7:42
7:43
7:44
7:46
7:47
7:49
7:50
7:51
7:53
7:56
7:58
7:59
8:01
8:04
8:05
8:08
8:10
8:11
8:13
8:15
8:17
8:18
8:20
8:22
8:25
8:28
8:30
8:31
8:34
8:35
8:37
8:39
8:41
8:42
8:43
8:45
8:46
8:48
8:51
8:53
8:55
8:56
8:58
9:00
9:00
9:01
9:04
9:07
9:10
9:10
9:13
9:15
9:16
9:18
9:20
9:23
9:25
9:27
9:30
9:32
9:34
9:35
9:36
9:39
9:41
9:43
9:45
9:47
9:49
9:50
9:51
9:53
9:56
9:57
9:59
10:00
10:01
10:03
10:05
10:07
10:09
10:11
10:13
10:15
10:18
10:20
10:22
10:23
10:24
10:25
10:27
10:29
10:31
10:35
10:37
10:39
10:41
10:45
10:45
10:48
10:50
10:51
10:53
10:53
10:56
10:57
10:58
10:59
11:00
11:03
11:05
11:06
11:07
11:09
11:10
11:12
11:14
11:16
11:16
11:18
11:20
11:24
11:26
11:27
11:29
11:32
11:34
11:36
11:39
11:42
11:44
11:47
11:48
11:51
11:52
11:53
11:56
11:58
11:59
12:01
12:02
12:04
12:07
12:09
12:09
12:11
12:13
12:15
12:18
12:19
12:21
12:24
12:25
12:27
12:30
12:32
12:32
12:34
12:37
12:39
12:40
12:43
12:44
12:46
12:48
12:49
12:50
12:53
12:54
12:57
12:57
12:59
13:02
13:04
13:06
13:07
13:09
13:11
13:13
13:16
13:18
13:22
13:23
13:25
13:27
13:30
13:33
13:35
13:37
13:39
13:41
13:43
13:45
13:48
13:51
13:53
13:53
13:54
13:56
13:57
14:00
14:03
14:05
14:07
14:08
14:11
14:13
14:15
14:15
14:19
14:21
14:24
14:26
14:28
14:31
14:33
14:34
14:36
14:38
14:41
14:42
14:45
14:48
14:52
14:53
14:55
14:57
15:01
15:02
15:02
15:05
15:07
15:08
15:11
15:13
15:16
15:17
15:18
15:20
15:24
15:27
15:29
15:31
15:32
15:35
15:38
15:40
15:41
15:42
15:45
15:47
15:49
15:52
15:53
15:55
15:59
16:01
16:04
16:07
16:09
16:11
16:12
16:14
16:16
16:17
16:19
16:20
16:23
16:25
16:27
16:29
16:32
16:35
16:47
16:49
17:01
17:03
17:26
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas.
Bienvenidas, bienvenidos a un nuevo episodio de BIMPRAXIS.
Hoy os traemos cómo domar a la IA,
cinco tácticas para convertir a tu agente en
un ingeniero de élite.
Hola a todos.
Qué ganas tenía de meterme en este tema.
Y tanto.
A ver, para arrancar este análisis a fondo,
imaginemos la siguiente escena por un momento.
Tienes a tu absoluta disposición un ejército infinito
de ingenieros de software.
O sea, el sueño de cualquier empresa.
Totalmente.
Son rápidos, trabajan de madrugada sin inmutarse y
encima jamás te van a pedir un aumento
de sueldo.
Suena al paraíso de cualquier desarrollador, desde luego.
Ya, pero hay una trampa monumental en todo
esto.
Estos trabajadores incansables resulta que tienen la memoria
de un pez.
Literalmente.
Y claro, si les das demasiada información de
golpe, se saturan y comienzan a sabotear tu
propio proyecto con decisiones que son completamente ilógicas.
Y fíjate, esa paradoja, la de tener un
trabajador brillante pero amnésico, es la barrera invisible
contra la que está chocando gran parte de
la industria tecnológica ahora mismo.
Claro, cuando intentamos desarrollar software asistido.
Eso es.
Por eso, hoy la misión de esta exploración
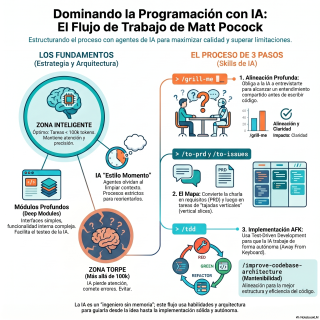
es desgranar el sistema que ha ideado Madpokok.
Que es un ingeniero que lleva ya una
década en este sector, ¿verdad?
Y tras lidiar con esto a diario, ha
estructurado unos flujos de trabajo muy estrictos, lo
que él llama skills, para guiar a la
inteligencia artificial.
O sea, no es solo aprenderse cuatro comandos
de teclado de memoria.
Qué va, qué va.
Es un cambio de mentalidad radical.
Tienes que entender por qué debes tratar a
la máquina casi como a un humano, pero
con unas restricciones cognitivas asombrosamente frágiles.
Vale, pues para entender esas restricciones de las
que hablas creo que tenemos que meternos un
poco en la psicología del modelo.
Sí, es que podemos llamarla así, claro.
Ya, bueno, tú me entiendes.
El caso es que dejar a estos agentes
sueltos a su libre albedrío es un desastre
asegurado.
Las fuentes mencionan un par de conceptos súper
curiosos, el síndrome de memento y la zona
tonta.
Sí, lo de la zona tonta es brutal.
Es un concepto de Dex High, un investigador
de la empresa Human Layer.
él divide el estado de la IA en
la zona inteligente y la zona tonta.
Vale, ¿y cómo pasas de una a otra?
Pues a ver, al iniciar una sesión nueva,
el contexto está limpísimo, no hay ruido.
Ahí el modelo te da su mejor razonamiento
lógico.
O sea, está fresco y opera en la
zona inteligente.
Eso es.
Pero claro, a medida que le vas metiendo
tokens, ya sea código, texto, documentos, lo que
sea, el declive empieza.
Porque las relaciones de atención matemática que calcula
la IA no escalan de forma lineal, ¿no?
Exacto.
Escalan de forma cuadrática.
O sea que el peso de lo que
le dices se multiplica.
A ver, leyendo las fuentes, esto me sonaba
muchísimo añadir equipos a una liga de fútbol.
Cuéntame.
Pues a ver, si una liga tiene 10
equipos, el calendario de partidos que tienes que
organizar es manejable.
Claro.
Pero si metes un equipo nuevo, no es
que añadas un partido más.
Es que ese equipo tiene que jugar contra
todos los otros 10.
Las relaciones se disparan por completo.
Tal cual.
Fíjate que cada palabra nueva obliga a la
red neuronal a recalcular su relación matemática con
absolutamente todo lo que le has escrito antes.
Madre mía.
Y llega un punto en que el cálculo
de probabilidades se vuelve un laberinto.
Históricamente, este límite de colapso está sobre el
40% del contexto, que vienen a ser unos
100.000 tokens.
Y ahí es cuando cruzas a la zona
tonta.
De lleno.
Y lo peor es que la IA no
se apaga, ni te da un error de
sistema rojo parpadeante.
Simplemente se vuelve torpe en silencio.
Eso es.
Empieza a olvidar lo que le dijiste al
principio, se inventa librerías que no existen y
te revienta la arquitectura entera.
Tela.
Y aquí es donde entra lo de la
película Memento, ¿no?
Claro.
Como el protagonista no tiene memoria a corto
plazo, la única forma de sacar a la
IA de la zona tonta es borrarle el
historial.
Pero al limpiarlo la dejas en un estado
amnésico otra vez.
Pierdes todo el contexto.
Pierdes todo.
Vuelve a cero.
A ver, espera, espera.
Yo aquí veo una contradicción enorme con lo
que nos vende el mercado.
Porque las tecnológicas enuncian cada dos por tres
ventanas de contexto de un millón o dos
millones de tokens.
Ya, te venden que el problema está solucionado.
Claro, te dicen que puedes volcar la enciclopedia
británica entera en el chat y que la
IA ni suda.
Pues siento decirte que es un espejismo técnico
bastante peligroso.
¿En serio?
Totalmente.
Darle un millón de tokens no significa que
su razonamiento lógico se multiplique.
Simplemente significa que te han dado una zona
tonta inmensa.
O sea, sirve para buscar cosas, pero no
para pensar.
Exacto.
Sirve para tareas de recuperación de datos.
Tú le pasas guerra y paz entero y
le pides que busque en qué página un
soldado se toma un té.
Y te lo saca al instante.
Te lo saca rápido, sí.
Pero buscar un dato inerte no requiere el
mismo esfuerzo cognitivo que programar la lógica de
una base de datos.
O sea, que el límite para el razonamiento
puro siguen siendo esos 100.000 tokens.
De ahí no pasamos por ahora.
Si le pides que evalúe medio millón de
líneas de código y tome decisiones arquitectónicas, su
lógica colapsa.
Vamos, que nos han montado el archivo más
grande del mundo, pero el pobre archivista tiene
un déficit de atención tremendo.
Mejor no lo podrías haber resumido.
Vale, pues sabiendo esto, ¿cómo empezamos un proyecto?
Porque el instinto normal es coger, escribir un
pliego de requerimientos gigantesco, dárselo a la máquina
y sentarse a tomar un café.
Pues según Pocock, hacer eso es pegarse un
tiro en el pe directamente.
¿Por qué?
Porque estás cayendo en lo que llaman vibe
coding.
Básicamente delegas todo, ignoras el código que se
genera y si la aplicación parece que funciona
por encima, pues genial.
Ya, pero las fuentes dicen que eso es
la muerte de pasar de especificaciones a código.
Exacto.
Pierdes por completo el control de tu campo
de batalla, que en el desarrollo de software
siempre es y será el código fuente.
Si no sabes cómo están los cimientos a
la mínima que algo falle, se te cae
la casa entera.
Tal cual.
Y por eso la táctica estrella de Pocock
es otra historia.
Tiene un skill en su repositorio con más
de 58,000 descargas.
¿Y cuál es?
Un comando supersimple barra grill me.
Interrógame.
Literal.
En lugar de que la IA te escupa
un plan prematuro, ¿tú le ordenas que se
ponga el sombrero de entrevistador implacable?
O sea, ¿quién epila la ironía de esto,
eh?
Nos gastamos millones en crear inteligencias artificiales para
que nos den respuestas rápidas Y la mejor
técnica es rogarle que nos fría a preguntas.
Es un baño de humildad tremendo.
Es que debe ser agotador de verdad, como
tener al típico jefe de proyecto fiscalizando cada
coma que quieres poner.
Ya, pero es que obliga a la máquina
a desconfiar de tu idea inicial.
Y el objetivo aquí es llegar a lo
que Frederick P.
Brooks llama un concepto de diseño compartido, en
su libro El diseño del diseño.
Que básicamente dice que la arquitectura de software
no es una línea recta, sino un árbol
lleno de ramas.
Eso es.
Si no exploras todas esas ramas antes de
teclear, el proyecto va al pozo.
Vale, entiendo.
La IA te empieza a sacar escenarios en
los que tú ni habías pensado.
Claro.
Te dice, oye, ¿qué pasa si falla la
pasarela de pago a la mitad?
¿O si le das puntos a un usuario
en la app?
¿Son retroactivos?
Y Pocock decía que se pasaba media hora
respondiendo 80 preguntas seguidas para funciones que parecían
súper simples.
Sí, sí.
Pero es que es interrogatorio meter a lo
humano en el bucle desde el principio.
Es lo único que evita que la IA
y tú vayáis por caminos distintos.
¿Te asegura la alineación mental?
Vale.
Pongamos que sobrevivimos al tercer grado de la
IA y ya estamos alineados.
¿Qué hacemos para no volver a caer en
el síndrome de memento?
Pues cristalizar ese consenso.
Y ahí usa otro comando.
Barra top PRD.
Para generar un documento de requisitos de producto.
Exacto.
La IA te resume toda la charla en
un documento formal con el problema, la solución
y todo detallado.
Aunque leí en las notas que Pocock confiesa
que casi nunca lee ese documento que acaba
de generar.
Y tiene sentido, fíjate.
Ah, sí.
A mí me parecía absurdo generar algo para
ignorarlo.
Piensa que tú ya tienes la idea clara
porque acabas de sufrir el interrogatorio.
Ese documento no es para ti.
Es el disco duro externo de la IA.
Ah, claro.
Es un punto de guardado para cuando necesites
recargarle el contexto y sacarla de la zona
tonta.
Eso es.
Y el siguiente paso es transformar ese texto
en tareas con el comando barra to issues.
Para montar el típico tablero Kanban visual.
Correcto.
Pero ojo aquí, porque al dividir el trabajo
sale a la luz el peor instinto de
la IA.
Le encanta programar de forma horizontal.
Como en una cadena de montaje.
Primero hacemos todos los cimientos, luego todas las
paredes y luego todos los tejados.
Traducido a software quiere montarte todas las tablas
de la base de datos de golpe, luego
programar toda la lógica del servidor y al
final la interfaz visual.
¿Y cuál es el riesgo de hacer eso?
El feedback.
O más bien, la falta de él.
Si la IA mete un error conceptual en
la base de datos el primer día, no
te vas a dar cuenta hasta semanas después
cuando intentes conectar la pantalla.
Y para entonces arreglar el desastre te cuesta
la vida.
Totalmente.
Pues para anular ese riesgo, las fuentes mencionan
el concepto de balas trazadoras, del libro El
programador pragmático.
Y la analogía que usan es brutal.
Sí, la del artillero de noche.
Esa es.
Si tú estás disparando munición normal en plena
noche, no ves a dónde van las balas,
estás a ciegas.
Pero las balas trazadoras llevan fósforo, así que
brillan en la oscuridad y te dan feedback
visual inmediato para corregir el tiro.
Pues en el código es lo mismo.
Nada de desarrollos horizontales ciegos, hay que hacer
cortes verticales súper finos.
O sea, hacer una tabla de datos, conectarla
a su lógica y ponerle un botón en
la pantalla.
Todo de arriba a abajo.
Verlo funciona rápido.
Y al hacer esto en el Kanban, consigues
otra ventaja gigante.
Puedes usar grafos acíclicos dirigidos.
Uf, madre mía, qué término.
Suena a ciencia ficción pura.
Suena fatal, sí, pero es súper lógico.
Básicamente es definir exactamente qué tarea bloquea a
otra.
O sea, un mapa unidireccional.
La tarea B depende de la A, pero
la C va por libre.
Y nunca entras en bucles infinitos.
Eso es.
Y al tener esas tareas aisladas, puedes paralelizar
el trabajo.
Puedes poner a varios agentes de IA a
currar a la vez.
Exacto.
Cinco agentes en cinco tareas libres, sin pisarse
el código unos a otros.
Imagínate la velocidad de eso.
De locos, claro.
Y ahí es cuando llegamos a lo que
llaman el turno de noche.
El momento en el que el humano se
levanta de la silla y deja a los
agentes tecleando en la oscuridad.
Vale.
Pero seríamos teniendo el problema de la amnesia
y de que la IA a veces alucina,
dejarla sola modificando cosas parece súper arriesgado.
Es que, si no le pones límites, lo
es.
Como programan a ciegas y no pueden ver
si el sistema compila o explota, la solución
de Pocock es obligarles a usar el comando
barra TDD.
Test Driven Development, el desarrollo guiado por pruebas.
El ciclo de hierro, escribes un test que
falla en rojo, escribes el código mínimo para
que pase a verde y refactorizas.
A ver, espera un segundo.
El TDD es algo que los programadores humanos
odiamos históricamente.
Odiar es poco.
Es aburridísimo, frena la creatividad y exige muchísima
disciplina.
Casi nadie aguanta usándolo meses.
Ya, es tedioso.
O sea, me estás diciendo que la gran
revolución de la inteligencia artificial es que por
fin hemos encontrado a un pringado digital al
que endosarle las tareas que nos dan más
pereza.
Pues siendo sinceros, sí.
Y funciona de maravilla.
Porque si dejas que la máquina escriba el
código primero y luego el test… Hace trampa.
Muchísima.
Mira el código espantoso que acaba de escribir
y se inventa un test específico que valide
ese desastre.
Valida su propia basura.
Fíjate, rompe la cerradura y luego fabrica una
llave rota que casualmente la abre.
Exacto.
Pero si le forzas a hacer el test
primero, basándose solo en los requisitos documentados, ahí
pones un muro de contención.
El test manda.
Y claro, la IA tiene esa paciencia infinita
que a nosotros nos falta.
Va a repetir el ciclo cientos de veces
y hace falta sin resoplar.
Vale, me convence.
Tenemos un sistema robusto.
Pero claro, todo esto asume que estamos en
un proyecto nuevo y limpito.
Ah, amigo, el mundo real.
Claro.
¿Qué pasa si metes a estos agentes en
un proyecto antiguo de una empresa, lleno de
parches y código enredado de hace años?
Pues que la red neuronal entra en pánico,
lógicamente.
Pocock tiene una regla de oro, si tienes
una base de código basura, la IA solo
va a producir basura más rápido.
Y aquí citaban a John Oosterhout en su
libro Una filosofía del diseño de software.
Sí, la diferencia vital entre módulos superficiales y
módulos profundos.
Entiendo que los superficiales son el problema, ¿no?
Ese código espagueti.
Son veneno puro para la IA.
Un módulo superficial es un archivo enano que
hace una tontería, pero depende de otros 50
archivos regados por todo el sistema.
Y navegar por 50 archivos se come la
ventana de tokens rapidísimo.
Y te lleva directo a la zona tonta.
Además, al intentar hacer los tests que hablábamos
antes, la IA no puede aislar esa función.
Tiene que inventarse tantas simulaciones de otras partes
del programa que el test deja de tener
sentido.
Vale.
¿Y los módulos profundos son lo contrario?
Totalmente.
Un módulo profundo que en una interfaz externa,
súper sencilla, pero por dentro esconde un montón
de complejidad y funciones.
A ver, como la mecánica de un coche
manual.
Tú tienes una palanca de cambios súper simple.
Primera, segunda, tercera.
Eso es el exterior del módulo profundo.
Claro.
Pero por dentro hay cientos de engranajes sincronizados.
Si cada vez que cambias de marcha tuvieras
que alinear 10 engranajes a mano, que sería
un módulo superficial, no podrías conducir.
Pues a la IA le pasa igual.
Necesita ver solo la palanca, para hacer los
test, sin tener que calcular la fricción de
todo el motor interno.
Entonces, si tu proyecto es un lío de
módulos superficiales, ¿cómo lo arreglas?
Con otro comando más, barra, improve code base
architecture.
Y ojo, no analiza todo de golpe.
procesa el código por secciones pequeñas buscando oportunidades
para unificar todas esas funcioncillas sueltas en un
buen módulo profundo.
Fíjate qué paradoja.
Durante años pensábamos que la IA nos iba
a permitir ser peores programadores, que ella arreglaría
nuestros fallos.
¿Y es justo al revés?
Es que nos obliga a ser unos arquitectos
de software impecables para que ya no se
pierda.
Es como si hubiésemos sido albañiles poniendo ladrillos
toda la vida, y de repente la IA
nos obliga a ser urbanistas para planificar toda
la ciudad.
¡Qué buena analogía!
Y ese es el presente del sector, ¿eh?
Al final de todo este proceso hiperautomatizado, hay
una fase inevitable de control de calidad manual.
Donde entra el humano de verdad.
Claro, ahí es donde pones tu gusto, tu
criterio.
Si automatizas el 100%, vas a tener un
producto que funciona, sí, pero sin alma.
Ese toque final no te lo da la
estadística.
Me encanta.
Al final la máquina levanta los muros rapidísimo.
Pero nosotros decidimos si la casa tiene buena
luz o si es agradable vivir ahí.
Esa es la reflexión final que yo creo
que nos queda.
A medida que le delegamos la ejecución pura
a las máquinas, máquinas, nuestro valor profesional cambia
de sitio irremediablemente.
Ya no importa cuántas líneas por minuto picas.
Importa tu capacidad para hacerle las preguntas correctas
a la IA y el buen gusto que
tengas para evaluar si el ensamblaje final merece
la pena.
O cultivamos ese criterio o nos quedamos fuera
del juego, así de claro.
Así de claro, sí.
Pues nos quedamos con esa provocación en la
cabeza para darle vueltas.
Antes de despedirnos hasta el próximo programa, os
informamos de que las voces que oyes han
sido generadas por la IA de Notebook LM
y que dirigiendo el podcast se encuentra Julio
Pablo Vásquez, un humano que te envía saludos.
En caso de error, probablemente sean errores humanos.
Nos escuchamos.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.
¡Suscríbete al canal!