Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:09
0:15
0:20
0:23
0:26
0:28
0:36
0:40
0:41
0:45
0:48
0:51
0:51
0:54
0:56
0:58
0:59
1:02
1:05
1:07
1:09
1:11
1:14
1:14
1:17
1:19
1:23
1:25
1:28
1:30
1:33
1:34
1:35
1:37
1:39
1:40
1:41
1:42
1:45
1:46
1:47
1:49
1:52
1:53
1:56
1:57
2:00
2:02
2:05
2:07
2:09
2:10
2:11
2:13
2:15
2:18
2:21
2:24
2:27
2:30
2:33
2:35
2:37
2:40
2:41
2:43
2:45
2:47
2:48
2:51
2:53
2:54
2:55
2:57
2:59
3:02
3:03
3:05
3:07
3:10
3:10
3:11
3:13
3:16
3:19
3:22
3:23
3:25
3:28
3:31
3:33
3:34
3:35
3:38
3:40
3:43
3:43
3:45
3:47
3:50
3:53
3:56
3:58
4:01
4:02
4:05
4:05
4:08
4:09
4:12
4:14
4:15
4:16
4:18
4:20
4:22
4:24
4:25
4:28
4:31
4:31
4:33
4:35
4:37
4:39
4:39
4:41
4:45
4:46
4:47
4:50
4:52
4:54
4:55
4:56
4:59
5:00
5:03
5:06
5:09
5:10
5:12
5:13
5:15
5:16
5:18
5:19
5:22
5:24
5:26
5:29
5:31
5:31
5:33
5:36
5:39
5:42
5:44
5:47
5:50
5:50
5:54
5:54
5:55
5:57
6:00
6:02
6:04
6:06
6:08
6:10
6:13
6:17
6:18
6:21
6:23
6:26
6:27
6:28
6:30
6:31
6:34
6:35
6:38
6:41
6:42
6:44
6:46
6:48
6:51
6:54
6:55
6:57
6:57
6:58
7:01
7:02
7:04
7:06
7:07
7:09
7:11
7:13
7:15
7:18
7:22
7:26
7:27
7:29
7:30
7:33
7:36
7:39
7:40
7:43
7:46
7:50
7:52
7:55
7:57
7:59
8:00
8:01
8:03
8:05
8:06
8:09
8:11
8:14
8:16
8:18
8:21
8:23
8:25
8:28
8:31
8:32
8:34
8:35
8:38
8:40
8:41
8:44
8:46
8:48
8:49
8:51
8:53
8:56
8:59
9:01
9:03
9:04
9:07
9:07
9:10
9:12
9:15
9:18
9:19
9:22
9:25
9:29
9:29
9:30
9:33
9:35
9:38
9:39
9:41
9:44
9:45
9:47
9:50
9:52
9:54
9:55
9:55
9:58
9:58
10:01
10:02
10:04
10:05
10:09
10:09
10:12
10:15
10:17
10:19
10:21
10:24
10:26
10:27
10:30
10:33
10:35
10:39
10:41
10:43
10:45
10:47
10:49
10:52
10:53
10:56
10:57
10:58
11:01
11:01
11:04
11:05
11:07
11:08
11:10
11:12
11:13
11:15
11:16
11:17
11:19
11:21
11:22
11:24
11:26
11:28
11:30
11:30
11:32
11:35
11:36
11:38
11:41
11:44
11:45
11:48
11:49
11:51
11:52
11:53
11:54
11:57
12:00
12:03
12:05
12:06
12:09
12:11
12:13
12:14
12:16
12:18
12:19
12:19
12:23
12:26
12:29
12:30
12:32
12:33
12:35
12:37
12:38
12:41
12:43
12:43
12:45
12:46
12:47
12:50
12:50
12:52
12:54
12:57
12:58
13:01
13:04
13:06
13:08
13:09
13:12
13:15
13:16
13:18
13:22
13:26
13:27
13:29
13:31
13:33
13:34
13:35
13:37
13:38
13:39
13:40
13:43
13:45
13:47
13:50
13:52
13:55
13:56
13:58
14:00
14:02
14:04
14:07
14:08
14:10
14:14
14:16
14:18
14:21
14:24
14:25
14:27
14:31
14:34
14:36
14:38
14:41
14:43
14:45
14:45
14:47
14:50
14:51
14:53
14:55
14:57
14:59
15:01
15:03
15:06
15:08
15:09
15:11
15:13
15:14
15:16
15:19
15:20
15:22
15:24
15:27
15:27
15:29
15:33
15:36
15:38
15:40
15:43
15:45
15:48
15:49
15:52
15:53
15:54
15:57
15:58
16:00
16:03
16:04
16:06
16:09
16:13
16:16
16:18
16:19
16:21
16:23
16:25
16:27
16:29
16:31
16:34
16:36
16:38
16:40
16:43
16:46
17:00
17:00
17:11
17:14
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas, bienvenidas, bienvenidos a un nuevo episodio
de BIMPRAXIS.
Hoy os traemos la anatomía de cómo integrar
herramientas de IA en un código de hace
15 años sin destruir el proyecto o en
el intento.
Y a ver, es un desafío que representa,
o sea, el verdadero campo de batalla de
la ingeniería actual.
Totalmente.
Porque, seamos sinceros, generar un bloque de código
desde cero en un entorno aséptico es, bueno,
un truquito que cualquier modelo de IA te
hace hoy en día antes del desayuno.
La fricción real, la de verdad.
Ocurre cuando chocamos con el mundo real, ¿no?
Claro, exacto.
Y por eso nuestra inmersión profunda de hoy
se centra en un caso real.
El que documentó el desarrollador Dan Delimarski y
el ecosistema donde él decide experimentar.
Ojo, no es un lienzo en blanco, es
su propio blog personal.
Un proyecto que lleva vivo y funcionando nada
menos que 15 años.
Que se dice pronto.
Ya te digo, 15 años en el mundo
del desarrollo web no es que sea mucho
tiempo.
Es que es una era geográfica.
Es una era geológica entera.
Han nacido y muerto decenas de lenguajes ahí
en medio.
Sí, sí.
Y la herramienta que utiliza para este experimento
es la línea de comandos, la CLI de
GitHub's PetKit.
Su objetivo sobre el papel es, a ver,
bastante mumbano.
Quiere añadir una nueva funcionalidad a este blog
milenario.
Específicamente quiere una lista de lectura, rollo la
página de libros de la escritora Molly White,
para tener un registro visual de lo que
va leyendo.
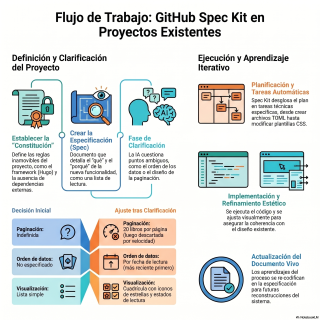
Vale, vamos a desglosar.
Vamos a desglosar esto, porque el contexto técnico
aquí lo es absolutamente todo.
El blog de Den usa un generador de
sitios estáticos que es Hugo, emplea Tailwind CSS
y además corre sobre un tema modificado.
Tela, ¿no puedes entrar ahí de cualquier manera?
Claro, para que una IA no entre ahí
como un elefante en una cacharrería, primero necesita
límites absolutos.
Es exactamente igual que invitar a un contratista
a reformar una cocina en una casa centenaria.
Muy buena analogía.
Si antes de mirar a Zulejos, lo primero
que tienes que hacer es sentarte con él
y decirle, oye, estos son los muros de
carga.
Bajo ninguna circunstancia puedes tirar estas paredes, porque
si lo haces, se nos cae el edificio
entero encima.
Es que es tal cual.
Si dejas a un modelo de lenguaje actuar
por libre, su instinto siempre va a ser
añadir la tecnología más moderna con la que
lo han entrenado.
Por eso, el primer paso en SpecKit no
es pedirle que programe, sino usar un comando
que es la barra Constitution.
¡Ostras!
Ahí es donde redacta.
Esta es la constitución del proyecto.
Es un documento que marca esas restricciones inquebrantables.
Y las reglas de DENZ fueron tajantes.
O sea, primera regla, es un sitio estático
puro.
Solo se puede usar Hugo.
Segunda regla, cualquier estilo visual tiene que usar
las convenciones que ya existen.
Pero la tercera regla es la que me
parece clave.
A ver.
Cero dependencias externas.
¿Absolutamente prohibido?
Añadir un nuevo archivo Package .json.
Claro.
Y aquí me quiero detener, porque para la
gente que no está todo el día picando
código, ¿por qué añadir un simple gestor de
paquetes es un pecado capital en este contexto?
Pues porque meter un Package .json es abrir
la caja de Pandora del ecosistema Node .js.
Es invitar al proyecto a ese agujero negro
que es la carpeta Node Models.
Te llenas de archivos sin darte cuenta.
Exacto.
Instalas una tontería para formatear un texto y
de repente ¡pum!
Descargas cincuenta mil pequeños archivos de terceros que
tienes que mantener y vigilar por temas de
seguridad.
Madre mía.
Y el blog de Derm es estático.
Eso significa que no procesa bases de datos
ni lógicas complejas.
Solo entrega un HTML casi a la velocidad
de la luz.
Si añades dependencias externas, te cargas esa pureza
que lleva quince años protegiendo.
Entendido.
La pureza manda.
Pero, revisando esto, hay un detalle que me
dejó, bueno, dándole vueltas.
Durante esta fase de la Constitución, ¿qué es
lo que se puede hacer?
Durante la Constitución, Derm usó Cloud Sonnet 4
y la IA sugerió por su cuenta una
regla ética.
Ah, sí, lo vi.
Decía, en plan, todo el contenido debe estar
escrito por humanos y ser genuino.
Y a simple vista parece una regla fantástica,
¿verdad?
Sí, suena muy bien.
Yo la habría dejado, pero Derm la eliminó
inmediatamente.
¿Por qué rechazar una buena práctica ética así?
Pues porque en el ámbito puramente de ingeniería,
la ética del contenido es ruido.
Ruido puro.
Derm la descartó porque es irrelevante para el
código.
La Constitución tiene que centrarse solo en la
infraestructura.
Zapatero a tus zapatos, vaya.
Exacto.
Si incluyes una directiva filosófica sobre quién escribe,
estás distrayendo al modelo.
La IA está ahí como arquitecto técnico para
construir las estanterías, no para ser descensor literario
de los libros que vas a poner en
ellas.
Vale, tiene todo el sentido.
Mantener el enfoque en los ladrillos digitales.
Entonces, una vez que la IA sabe perfectamente,
lo que no puede hacer, llega el momento
de decirle qué queremos construir.
Y aquí, ¡buf!, la industria del software lleva
décadas tropezando con la misma piedra.
Ya te digo.
Los humanos somos un desastre total detallando requisitos
técnicos.
Totalmente.
Es un problema crónico con los documentos de
requisitos del producto, los PRD.
A nadie le gusta escribirlos, porque tienes que
imaginar las 100 formas diferentes en las que
un usuario podría romper el sistema.
Y siempre nos dejamos algo.
Y aquí es donde… El proceso con SPECIT
da un giro, o sea, ¡brillante!
DEN usa primero el comando SPECIFY para decirle
a la IA, más o menos, que quiere
una ruta alimentada por archivos TOMEL, que es
un formato muy sencillo.
Pero la verdadera magia ocurre cuando ejecuta el
comando CLARIFY.
¡Ostras, sí!
El CLARIFY es brutal porque invierte a los
roles.
La IA deja de generar código a ciegas
y analiza el borrador.
Y usando su conocimiento, empieza a hacerle preguntas
al desarrollador, para iluminar sus puntos ciegos.
¡Es buenísimo!
Leyendo el caso de estudio, de verdad, ¡es
divertidísimo!
La IA de repente se transforma en un
gestor de proyectos súper exigente, interrogando a un
desarrollador que, pobre, claramente no había pensado en
los detalles.
Seguro que le pilló sin tomarse el primer
café.
Seguro.
Vamos a repasar el interrogatorio porque no tiene
desperdicio.
La primera pregunta de la máquina fue, ¿cómo
se van a ordenar los libros?
Una omisión clásica.
Nosotros asumimos que hay un orden.
Pero el ordenador necesita reglas matemáticas.
Den tuvo que decidir ahí mismo que se
ordenarían por fecha de finalización.
Los más recientes, arriba.
Luego, la IA le ataca con el diseño.
Le suelta, ¿cuántos libros deben mostrarse por página?
Claro, la paginación.
Den, pensando rápido, dijo que 20 libros por
página estaría bien.
Y la tercera pregunta fue puramente visual.
Le dijo, ¿cómo se mostrarán las calificaciones?
¿Quieres dibujar estrellas, poner un número, o las
dos cosas?
Y Den optó por estrellas visuales y el
número al lado para que fuera accesible.
Pero la cuarta pregunta, esa es la que
demuestra que estamos ante algo diferente.
La IA le pregunta, ¿qué pasa con los
libros que has empezado a leer pero aún
no has terminado y no tienen fecha de
finalización?
Brutal.
A mí me parece fascinante.
O sea, ¿cómo Narizas sabe la IA que
eso va a ser un problema?
Lo detecta porque estos modelos analizan millones de
repositorios de código.
La IA sabe, estadísticamente, que en bases de
datos con fechas, si dejas un valor vacío
o nulo, el frontend explota.
Te rompe el ordenamiento de la primera pregunta.
Madre mía, qué fuerte.
Y claro, ante eso Den decidió que los
libros inconclusos se quedarían anclados arriba del todo
en una sección de leyendo actualmente.
Una salida muy elegante, la verdad.
Y la quinta pregunta ya cerraba el círculo
de la seguridad.
¿Qué hacemos si el archivo TOM está corrupto
o le faltan datos?
Pragmatismo en vena.
Porque Den le dijo que ignorara silenciosamente la
entrada con errores y renderizará el resto para
no asustar a la gente que visite la
web.
Y es que esta fase interactiva es revolucionaria.
Cuando nos quejamos de que la IA da
código basura, el 90 % de las veces
es nuestra culpa por darle un contexto pésimo.
Si obligas a la IA a preguntar primero,
las reglas quedan perfectas.
Vale.
Con los vacíos lógicos rellenados ya sabemos qué
construir.
Pero saber el qué no es saber el
cómo sin dinamitar el proyecto.
Por eso pasan al comando plan, donde la
IA toma las respuestas y diseña las tareas.
Y aquí te tengo que preguntar.
La IA propuso crear un sistema completo de
tests automatizados, pruebas de código.
Y Den literalmente intervino y se los cargó
todos.
Los borró de un plumazo.
A ver, perdóname, pero como principio de ingeniería,
quitar los tests no es una negligencia.
¿Qué pasa si una actualización le rompe la
lista mañana?
Es una reacción súper normal la tuya.
Desde un punto de vista académico, tendrías toda
la razón.
Pero lo fascinante de esto es que ilustra
por qué necesitamos al humano en el bucle.
La IA no entiende de presupuestos ni de
contexto social.
Claro, va con todo.
Exacto.
Aplica el rigor de una empresa enorme a
todo lo que hace.
Se cree que está diseñando el sistema de
frenado de un tren bala.
Pero Den es un tío manteniendo su blog
personal en su tiempo libre.
¿El contexto empresarial frente al pragmatismo personal?
Eso es.
En un blog estático, montar integración continua y
tests añade una complejidad monumental.
Ralentiza todo para una función que, si se
rompe, bueno, pues no se ve la portada
de un libro, ya está.
Den actuó como freno humano ante la sobreingeniería.
Tiene todo el sentido del mundo.
Agilidad por encima del dogma.
Y esta colaboración se afina aún más en
el siguiente paso, con el comando Analyze.
Spekit revisa el plan contra la Constitución.
Y la IA ahí brilla, porque detecta un
error tremendo de arquitectura.
El plan inicial decía de guardar los datos
en la carpeta config.
Pero la IA salta y dice, oye, las
convenciones de Hugo dicen que los datos van
en la carpeta data, no en config.
Qué nivel de detalle.
Es que ese nivel idiomático del ecosistema es
alucinante.
Sí, sí.
Demuestra que no es un simple lorito repitiendo
texto.
Entiende la semántica de las carpetas de los
frameworks modernos.
Y bueno, con el plan ya pulido, llega
el momento de ejecutar.
El comando Implement.
El choque de realidad, madre mía.
Siempre.
Siempre la teoría es perfecta hasta que abres
el navegador web.
Ya te digo.
Según cuenta Den, ejecuta el comando.
El backend funciona perfecto.
Los datos cargan.
Pero el frontend, la parte visual, es un
desastre absoluto.
En vez de una cuadrícula elegante, le sale
una lista plana y aburrida.
Típico.
Pero a ver, no lo entiendo.
Hablamos de IA que te programa algoritmos de
cifrado en segundos.
¿Y me estás diciendo que no sabe alinear
cuatro cajas en una pantalla con CSS?
Es que es una debilidad estructural gigantesca de
los modelos actuales.
Un LLM es ciego, fundamentalmente.
No ve la pantalla.
No tiene razonamiento espacial.
Ah, claro.
Solo predice texto.
Exacto.
Escribir Python es… … lógica secuencial.
Pero el CSS, especialmente una cuadrícula o flexbox,
es contextual y en dos dimensiones.
La IA puede adivinar qué clases de Tailwind
suelen ir juntas.
Pero no sabe cómo van a colisionar esos
píxeles en la pantalla del usuario.
Siempre hace falta iteración visual humana.
Es como si te hace los planos de
la casa perfectos, pero le tienes que decir
tú si el sofá va a caber por
la puerta del salón.
Tal cual.
Por eso, Den combina Cloud Sonnet 4 y
GPT -5 para ir refinando el diseño.
Le meten unas pastillas visuales muy chulas para
las fechas.
La etiqueta de lectura obligatoria.
Un contador.
Se empieza a ver genial.
Pero ojo que aquí ocurre un pivote técnico
brutal.
¿Te acuerdas de que habían exigido paginación de
20 libros en la fase de clarificación?
Sí, sí.
Parecía inamovible.
Pues desaparece por completo.
Se la cargan.
¿Qué provocó un cambio tan drástico a mitad
de camino?
Pues fue puro pragmatismo.
Lo que podríamos llamar esencialismo de software.
Se dieron cuenta de un conflicto arquitectónico de
fondo.
Si querían paginación real, sin recargar la web
entera, tenían que inyectar código JavaScript.
Y el JavaScript rompe la regla de la
pureza estática que vimos al principio.
Exactamente.
Añadir JavaScript para un triste botón de siguiente
iba en contra de 15 años de rendimiento
extremo.
Así que Den hizo algo dificilísimo.
Priorizó la simplicidad arquitectónica sobre un capricho estético.
Prefirió una sola página larga y súper rápida.
Brillante.
Saber decir no a tu propia idea para
no romper los cimientos.
Bueno, llegamos al éxito.
El código funciona.
Es rápido.
No hay JavaScript ni necesario.
Misión cumplida.
En teoría.
Claro.
El 99 % de la gente guardaría el
código, cerraría el ordenador y a otra cosa.
Pero Den da un último paso.
Y esto transforma un simple experimento en una
lección maestra de ingeniería.
Sí, porque la innovación no acaba cuando la
pantalla se ve bonita.
Durante la iteración, aprendieron cosas.
Por ejemplo, que si no le daban un
ancho fijo a las tarjetas, rebotaban por culpa
del tamaño de los títulos.
O usar emojis específicos para cada estado, claro.
Eso es.
Y Den le ordena a la IA que
coja todos esos descubrimientos empíricos y los escriba
de vuelta en el archivo original de especificaciones,
en el spec .md.
O sea, actualiza el texto con lo aprendido.
Pero, ¿qué significa esto en realidad?
¿Por qué es tan vital hacer esto si
el código ya funciona perfectamente?
Pues porque cambia la perspectiva por completo.
Históricamente, un documento de requisitos era una servilleta
glorificada que tirabas a la basura en cuanto
escribías la primera línea de código.
Ahora, ese documento se convierte en un artefacto
independiente y vivo.
Es la única fuente de verdad.
Exacto.
Es como, a ver, como si extrajera el
ADN de la aplicación para separarlo del cuerpo
físico, ¿no?
Me encanta esa forma de verlo.
Imagina que dentro de cinco años Den se
harta de Hugo y quiere reescribir su blog
en otro lenguaje que aún ni existe.
Si no tuviera el documento, tendría que hacer
ingeniería inversa.
Leer código superviejo y volvería a cometer los
mismos errores con los anchos de las tarjetas.
Claro.
Pero con este sistema, no empieza de cero
ni se pone a discutir la lógica con
la IA del futuro.
Solo le da ese archivo superdetallado y le
dice, esta es la filosofía inmutable de mi
aplicación.
Reconstrúyela con la tecnología de hoy.
Es un cambio de paradigma total.
Pasamos de venerar el código fuente a venerar
el concepto.
O sea, la magia de la IA no
es escupir líneas de código desechable, sino obligarnos
a pensar y documentar con precisión de cirujano.
Y esto nos lleva a una reflexión final
que es, vamos, provocadora.
Si un documento vivo puede preservar la esencia
exacta de un programa sin importar en qué
esté escrito, ¿estamos ante el principio del fin
del código heredado?
El famoso código viejo intocable.
Ese que todo el mundo tiene miedo de
tocar, sí.
Ya no tienes que parchear código frágil de
hace quince años.
Le pides a la máquina que lo regenere
enterito con las librerías de esta semana.
Exacto.
Quizás en el futuro nuestro trabajo no sea
leer código viejo, sino simplemente conversar con la
IA para auditar esa constitución y esas especificaciones.
Las máquinas ya tejerán y destejerán el código
por debajo cada pocos meses.
El código pasa a ser un código.
Es un subproducto efímero.
Y la idea es lo eterno.
Una reflexión alucinante sobre cómo nos vamos a
relacionar con lo que creamos.
Merece la pena darle una vuelta cuando nos
frustremos con un sistema antiguo.
Antes de despedirnos, hasta el próximo programa os
informamos de que las voces que oyes han
sido generadas por la IA de Notebook LM
y que dirigiendo el podcast se encuentra Julio
Pablo Vázquez, un humano que te envía saludos.
En caso de error, probablemente sean errores humanos.
Nos escuchamos.
Hasta el próximo episodio de hoy.
Muchas gracias por tu atención.
Esto es BIM Praxis.
Nos escuchamos en el próximo episodio.