Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:09
0:15
0:20
0:23
0:26
0:28
0:36
0:39
0:40
0:42
0:45
0:48
0:50
0:50
0:53
0:55
0:57
1:00
1:03
1:04
1:06
1:08
1:09
1:11
1:14
1:16
1:18
1:18
1:21
1:23
1:24
1:25
1:27
1:30
1:34
1:37
1:38
1:40
1:43
1:44
1:48
1:48
1:52
1:55
1:56
1:57
2:01
2:03
2:05
2:07
2:09
2:12
2:13
2:14
2:17
2:19
2:21
2:23
2:25
2:29
2:31
2:33
2:36
2:38
2:40
2:44
2:45
2:47
2:51
2:53
2:54
2:55
2:58
3:01
3:03
3:06
3:08
3:12
3:13
3:14
3:17
3:19
3:23
3:24
3:26
3:26
3:30
3:32
3:34
3:36
3:38
3:40
3:42
3:42
3:44
3:44
3:44
3:46
3:48
3:50
3:52
3:53
3:55
3:58
4:01
4:01
4:02
4:03
4:05
4:08
4:11
4:13
4:16
4:18
4:23
4:24
4:25
4:26
4:29
4:31
4:33
4:35
4:36
4:37
4:40
4:43
4:44
4:45
4:47
4:49
4:53
4:56
4:57
4:58
5:01
5:04
5:07
5:10
5:12
5:15
5:15
5:18
5:21
5:23
5:23
5:26
5:28
5:30
5:33
5:35
5:36
5:40
5:43
5:43
5:44
5:47
5:51
5:54
5:55
5:57
5:58
6:00
6:01
6:03
6:04
6:06
6:07
6:08
6:10
6:11
6:13
6:15
6:16
6:18
6:19
6:21
6:22
6:24
6:26
6:27
6:30
6:33
6:34
6:35
6:38
6:42
6:42
6:45
6:47
6:49
6:52
6:54
6:58
6:59
7:00
7:03
7:07
7:09
7:11
7:15
7:18
7:20
7:22
7:25
7:28
7:31
7:32
7:34
7:35
7:38
7:40
7:43
7:43
7:47
7:48
7:51
7:53
7:54
7:56
7:58
7:59
8:02
8:04
8:06
8:09
8:09
8:10
8:13
8:15
8:20
8:21
8:23
8:25
8:29
8:32
8:34
8:36
8:38
8:38
8:41
8:42
8:45
8:47
8:49
8:51
8:52
8:55
8:56
8:59
9:01
9:02
9:03
9:05
9:07
9:10
9:12
9:14
9:17
9:20
9:22
9:24
9:27
9:29
9:32
9:32
9:35
9:35
9:37
9:40
9:43
9:45
9:46
9:48
9:51
9:53
9:56
9:59
10:02
10:04
10:05
10:08
10:11
10:13
10:15
10:17
10:20
10:20
10:22
10:25
10:26
10:28
10:28
10:30
10:32
10:35
10:37
10:39
10:40
10:41
10:43
10:46
10:49
10:51
10:52
10:53
10:55
10:58
11:00
11:01
11:04
11:05
11:06
11:06
11:09
11:11
11:14
11:17
11:19
11:22
11:24
11:27
11:28
11:28
11:32
11:35
11:38
11:39
11:40
11:42
11:45
11:47
11:49
11:49
11:52
11:55
11:57
12:00
12:03
12:05
12:08
12:11
12:13
12:14
12:17
12:22
12:25
12:28
12:29
12:32
12:34
12:35
12:37
12:40
12:44
12:45
12:46
12:48
12:50
12:52
12:55
12:57
13:00
13:02
13:02
13:05
13:08
13:12
13:15
13:16
13:19
13:19
13:20
13:22
13:25
13:27
13:30
13:30
13:32
13:32
13:35
13:37
13:39
13:41
13:44
13:45
13:48
13:48
13:50
13:53
13:55
13:56
13:59
14:02
14:03
14:04
14:06
14:09
14:12
14:14
14:16
14:19
14:19
14:20
14:23
14:25
14:29
14:32
14:32
14:34
14:35
14:36
14:38
14:39
14:41
14:43
14:45
14:48
14:49
14:51
14:54
14:54
14:57
14:59
15:00
15:02
15:04
15:05
15:06
15:09
15:12
15:14
15:17
15:17
15:20
15:22
15:25
15:28
15:31
15:34
15:34
15:39
15:42
15:44
15:47
15:50
15:52
15:52
15:56
15:59
16:01
16:05
16:06
16:08
16:12
16:15
16:17
16:19
16:22
16:25
16:26
16:30
16:31
16:33
16:34
16:36
16:38
16:39
16:42
16:46
16:49
16:51
16:52
16:54
16:55
16:57
17:00
17:02
17:03
17:05
17:07
17:09
17:11
17:13
17:16
17:17
17:20
17:21
17:24
17:27
17:29
17:31
17:34
17:37
17:40
17:42
17:44
17:47
17:49
17:51
17:54
17:56
17:58
18:00
18:01
18:02
18:05
18:09
18:11
18:14
18:17
18:19
18:20
18:22
18:26
18:26
18:29
18:30
18:32
18:35
18:38
18:41
18:43
18:44
18:46
18:47
18:50
18:53
18:56
18:59
19:01
19:03
19:04
19:06
19:09
19:11
19:15
19:18
19:22
19:24
19:27
19:29
19:30
19:33
19:35
19:38
19:41
19:45
19:47
19:48
19:51
19:52
19:55
19:58
20:00
20:03
20:05
20:08
20:11
20:14
20:16
20:20
20:21
20:24
20:26
20:30
20:32
20:35
20:36
20:37
20:40
20:43
20:45
20:48
20:50
20:50
20:54
20:58
21:01
21:04
21:04
21:08
21:11
21:14
21:17
21:20
21:22
21:25
21:28
21:30
21:30
21:33
21:36
21:37
21:37
21:39
21:41
21:43
21:47
21:50
21:53
21:54
21:57
21:58
21:58
22:01
22:04
22:06
22:09
22:12
22:15
22:19
22:22
22:23
22:25
22:28
22:29
22:31
22:35
22:37
22:40
22:40
22:43
22:45
22:48
22:50
22:51
22:52
22:55
22:57
22:58
23:01
23:03
23:06
23:08
23:10
23:11
23:12
23:15
23:17
23:20
23:23
23:25
23:28
23:29
23:32
23:33
23:35
23:38
23:40
23:42
23:56
23:57
24:08
24:10
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas, bienvenidas, bienvenidos a un nuevo episodio
de BIMPRAXIS.
Hoy os traemos el fin definitivo de la
pesadilla de la edición de imágenes por inteligencia
artificial, o cómo pasar de cruzar los dedos
a tener un bisturí de precisión.
Hola, ¿qué tal?
Sí, este es un tema que nos toca
de cierca a cualquiera que haya tocado una
herramienta de IA alguna vez.
Totalmente, porque, a ver, hay una situación recurrente
en la generación de imágenes que es universalmente
frustrante.
Imaginemos tener la imagen perfecta en la pantalla.
La típica que sale a la primera y
dices ¡guau!
Eso es, la luz de la ventana cae
justo sobre una mesa de roble, la atmósfera
es impecable, o sea, la composición parece sacada
de una galería de arte.
Ajá.
Pero hay un detalle, un vaso de plástico
horrendo en una esquina que arruina toda la
escena.
¿Y ya sabes lo que pasa después?
Claro, le pides a la IA que quite
sólo ese vaso y, de repente, el desastre.
La luz cambia, la mesa desaparece, el estilo
se esfuma y, bueno, esa magia inicial se
pierde para siempre.
Es la gran pesadilla, sí.
Es el problema endémico de lo que llamamos
la caja negra en la inteligencia artificial.
A ver, explícanos un poco eso de la
caja negra.
Pues, históricamente, el paradigma ha consistido en lanzar
una instrucción, cruzar los dedos y aceptar lo
que el modelo decida escupir.
Tal cual.
Si buscas modificar algo a posteriori, la arquitectura
de la mayoría de los modelos no está
diseñada para editar en el sentido tradicional.
Ya, no es como usar el tampón de
clonar en un programa clásico.
Exacto, lo que hacen es volver a generar
la imagen desde cero.
Utilizan la nueva instrucción.
La nueva instrucción como semilla principal y es
por eso que la consistencia matemática y visual
de la primera imagen se desintegra.
Vale, vamos a desgranar esto.
Porque el objetivo de este análisis a fondo
es precisamente explorar una solución que elimina de
un plumazo esa dinámica de cruzar los dedos.
Y es una solución brillante, la verdad.
Vamos a sumergirnos en un tutorial fascinante del
canal de YouTube de Hong Seo.
Este creador ha documentado una técnica que otorga
un control absoluto, pero absoluto y milimétrico sobre
las imágenes.
Utilizando los modelos de Google, ¿verdad?
Sí, específicamente usando los modelos Gemini, Nano, Banana
2 y su hermano mayor, el Nano, Banana
Pro.
Hmm, interesante.
La promesa aquí es pasar de esa frustración
a una precisión quirúrgica, algo vital para la
audiencia que nos escucha, ya sean profesionales de
la creación de contenido o simplemente mentes curiosas.
Es que el salto cualitativo que plantea esta
técnica reside en cómo reconfigura la relación entre
el ser humano y el modelo generativo.
Cambia las reglas del juego.
Para evitarse a dar órdenes vagas desde la
barrera y esperar que la máquina te entienda,
este flujo de trabajo permite acceder directamente a
los engranajes de la imagen.
A las tripas, digamos.
Exacto.
Controlas cada variable de forma explícita.
Convierte lo que era un proceso aleatorio en
un ejercicio de ingeniería inversa visual.
Y todo este proceso de ingeniería inversa comienza
con lo que el creador del vídeo denomina
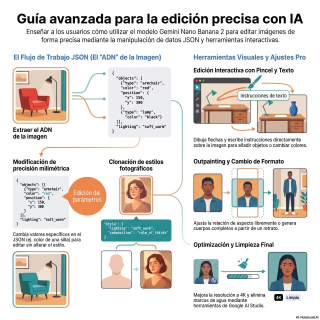
extraer el ADN de la imagen.
Me encanta ese concepto.
Es genial.
Quien vea el tutorial notará que el ADN
de la imagen es el mismo que el
de la imagen.
Así que no se empieza usando una herramienta
mágica de selección, ni un pincel.
El primer paso es subir la imagen a
Gemini y utilizar un comando de texto súper
específico.
¿Cuál es el prompt, exactamente?
Le dice, extrae toda la información de esta
imagen y conviértela en JSON estructurado.
Guau.
Vale.
Claro.
La audiencia más técnica sabe qué es un
archivo JSON y cómo estructura los datos, pero
aplicarlo a un puñado de píxeles es desconcertante.
¿Qué ocurre en la red neuronal cuando le
pides que convierta una imagen?
Pues lo que ocurre es un proceso de
traducción de, digamos, espacio latente a espacio semántico.
Vale.
Tradúceme eso a mí.
A ver.
Gemini es un modelo multimodal nativo.
Esto significa que no procesa la imagen simplemente
identificando contornos.
O sea, no ve solo manchas de color.
No.
Comprende la escena.
Así que, al pedirle que estructure esa comprensión
en JSON, la IA desglosa la imagen en
categorías lógicas.
Para métricas.
¿Y qué incluye exactamente?
Pues traduce el estilo general, la paleta de
colores, la iluminación, la disposición espacial y las
propiedades de cada objeto a pares de claves
y valores.
Madre mía.
Literalmente coge una matriz de millones de píxeles
y la reduce a su código fuente semántico.
Describe qué hay, cómo está iluminado y en
qué coordenadas exactas del espacio imaginario se encuentra.
O sea, es como si tuviéramos un bizcocho
ya horneado.
Sí.
Piensa que, en la edición tradicional de IA,
intentar cambiar algo sería como intentar inyectar sabor
a chocolate en un bizcocho de vainilla que
ya está hecho.
El resultado es un desastre estructural.
Claro, se te rompe todo.
Pero al extraer este JSON, lo que obtenemos
no es el bizcocho, sino el acceso directo
a la receta exacta, con las proporciones precisas
de cada ingrediente.
La analogía funciona perfecto, porque subraya la diferencia
entre manipular el resultado final y manipular el
origen.
Eso es.
Teniendo la receta codificada, o sea, el cómo
se construyó esa realidad visual, pues se vuelve
posible alterar una variable aislada sin detonar una
reacción en cadena.
Sin que explote la cocina.
Exacto.
Sin alterar la estructura molecular del resto de
los ingredientes.
Pero espera, aquí hay algo que requiere más
profundidad.
Entiendo la teoría, pero ¿cómo se ve esto
en la práctica?
A ver.
Imagina que en esa receta JSON busco un
mueble.
Pongamos una silla negra.
Y cambio la propiedad de texto de negro
a rojo.
Le digo a la IA que modifique el
ingrediente.
Ajá, le cambias la variable del color.
Sí.
Pero ¿cómo gestiona la IA la física de
la luz ante ese cambio?
Porque si yo cojo un bote de pintura
roja en un software tradicional como Photoshop y
relleno una silla negra, el resultado es plano.
Claro, parece una pegatina.
Copalmente.
Se pierden las sombras sutiles, los reflejos del
entorno se ven artificiales, la iluminación global se
rompe.
¿Cómo evita la IA que ese simple cambio
de texto no se traduzca en un parche
visual barato?
Esa es precisamente la magia de no estar
editando píxeles, sino conceptos.
Lo fascinante aquí es que Gemini no aplica
un filtro de color.
Ah, vale.
Al recibir el JSON modificado, el modelo utiliza
esos datos estructurados como la verdad absoluta para
un nuevo renderizado generativo.
Entiendes semánticamente qué es una silla.
Qué implica que sea roja y, crucialmente, cómo
un material rojo interactúa con la iluminación global.
Porque la iluminación también está en ese JSON.
Exacto, todo está ahí.
Entonces recalcula el rebote de la luz, las
sombras proyectadas y los reflejos basándose en las
leyes de la física óptica que ha aprendido
durante su entrenamiento.
O sea que la integración es perfecta.
Absolutamente.
Elimina la caja negra, pero mantiene el motor
de renderizado avanzado intacto.
Pone el control algorítmico directamente en manos de
quien edita.
Y aquí es donde se pone realmente interesante.
Porque una cosa es alterar el color de
un objeto físico y tangible que al final
no deja de ser un cambio de variable
sencilla.
Sí, es cambiar una palabra por otra.
Pero otra muy distinta es adentrarse en lo
abstracto.
Hablamos de capturar el alma de una fotografía,
lo que en el vídeo se demuestra como
la técnica de robar estilos.
El concepto de extraer la esencia artística de
una imagen.
Efectivamente.
El nivel de abstracción sube considerablemente aquí.
En el tutorial, el creador toma un retrato
con un estilo fotográfico muy particular, muy cinematográfico
y atmosférico.
Y en vez de pedirle a la IA
que describa qué ropa lleva el sujeto o
qué muebles hay, la Instrucciones describe las técnicas
fotográficas de esta imagen en formato JSON.
Un enfoque totalmente distinto.
Y el resultado no es un simple foto
oscura y dramática.
En absoluto.
Gemini parametriza el arte de la fotografía.
¿A qué nivel de detalle llega?
Pues el código JSON que devuelve descompone el
estema de iluminación.
Indica si hay luz clave, luz de relleno
o recortes lumínicos traseros.
¡Guau!
Especifica el rango dinámico, la temperatura de color,
la gradación tonal.
Incluso simula las propiedades del equipo óptico que
se habría utilizado en el mundo real.
¿Te saca hasta la lente?
Sí.
Define la distancia focal, la profundidad de campo
y el nivel de aberración cromática.
Es, a todos los efectos, la disección de
cada decisión técnica y artística que un director
de fotografía tomaría en un plató.
Que esa técnica fotográfica se convierte en texto
puro, en datos que guardas en el portapapeles,
Elvidia muestra el siguiente paso lógico.
¿Qué hace con todo eso?
Pues sube dos o tres fotografías ordinarias desde
distintos ángulos para que la IA registre los
rasgos faciales de un sujeto concreto.
Vale.
¿Entrena al modelo con una cara?
Exacto.
Y a continuación, lanza la Instrucciones.
Genera una foto de esta persona basada en
el siguiente archivo JSON y pega todo ese
desglose de técnicas cinematográficas.
¡Madre mía!
El resultado es la recreación exacta de ese
sujeto bajo esa misma iluminación compleja, la misma
óptica y el mismo etalonaje de color.
O sea, ha logrado separar completamente la técnica
fotográfica de los objetos físicos.
Convierte el estilo en un activo portátil que
puedes aplicar a cualquier sujeto nuevo.
Es alucinante.
Y manteniendo una fidelidad visual asombrosa.
Todo gracias a esa coherencia del espacio latente.
Pero pongámonos en el caso de querer llevar
esa edición un paso más allá.
Imaginemos que, además de aplicar ese estilo al
rostro, se quiere cambiar trásticamente el vestuario.
Vale.
Añadir, por ejemplo, un traje formal de tres
piezas y una camisa roja donde antes sólo
había una camiseta básica.
Ahí la cosa se complica.
Claro.
Ahí veo un obstáculo enorme.
Si alterar un color era cambiar una palabra,
añadir un traje completo implica modificar el estilo.
Modificar la geometría del cuerpo, las arrugas de
la tela, el volumen que ocupa en el
espacio.
Totalmente.
Modificar el JSON manualmente para inyectar todas esas
nuevas coordenadas espaciales parece una tarea imposible.
O sea, si no tienes conocimientos avanzados de
programación, no es un riesgo enorme de corromper
la imagen.
Es un riesgo altísimo, sí.
Si se hiciera de forma manual.
Pero la solución que plantea la fuente es
de una elegancia técnica brillante.
¿Cómo lo resuelve?
Consiste en utilizar a la propia IA como
editora de su propio software.
¡Ostras!
Sí.
El usuario no necesita tocar ni un solo
corchete del archivo JSON.
El proceso pasa por instruir a Gemini con
lenguaje natural diciendo, añade un traje y una
camisa roja a esta persona en el prompt
JSON, y adjuntas el código original debajo.
O sea, ¿delegamos en el modelo la tarea
de reescribir su propia receta para acomodar esa
nueva geometría?
Exactamente.
La red neuronal analiza el JSON subyacente, comprende
la petición abstracta de añadir un traje, y
calcula todas las nuevas variables espaciales y semánticas.
Lo integra todo él solo.
Todo.
Sin romper el esquema general.
Reescribe las líneas de código pertinentes y genera
un nuevo JSON actualizado.
Y con eso ya renderizas.
Eso es.
Se utiliza ese nuevo código para generar la
imagen y en cuestión de segundos el sujeto
viste un traje perfectamente integrado.
La consistencia del rostro, el fondo y ese
estilo lumínico tan complejo permanecen inmutables.
Es magia pura.
Si conectamos esto con el panorama general, lo
que estamos observando es una disrupción profunda en
la economía de la creación visual.
Totalmente.
El nivel de control direccional que antes exigía
alquilar un estudio, configurar iluminación física, contratar estilistas
y pasar horas en postproducción, ahora se ha
comprimido en un flujo de operaciones estructuradas mediante
texto.
Es una democratización sin precedentes.
El impacto en los tiempos de producción y
en la accesibilidad de sistemas, es innegable.
Sin embargo, hay un punto en el que
interactuar exclusivamente a través de bloques de código
estructurado, bueno, resulta poco intuitivo para disciplinas eminentemente
visuales.
Es verdad.
Por mucho que la IA lo gestione, ver
tanto código asusta un poco.
Y aquí es donde la técnica del vídeo
da un giro interesante, porque demuestra que todo
este andamiaje de JSON se puede controlar a
través de una interfaz puramente interactiva.
Escribir código no es la única vía.
Claro.
La transición de la manipulación textual a la
interacción espacial es clave para la usabilidad.
El tutorial muestra cómo Gemini integra herramientas visuales
que actúan como un intermediario o un frontend
muy amigable.
Ocultando la complejidad del JSON que corre por
debajo.
Exacto.
Es un proceso visual muy directo.
Se hace clic sobre la imagen generada, se
selecciona una herramienta de pincel integrada y se
dibuja, literalmente, una flecha que apunta a un
sofá.
Ajá, súper intuitivo.
Sí.
En la misma interfaz aparece una herramienta de
texto y se escribe encima de la imagen,
vuelve el sofá rojo.
Acto seguido, dibujas otra flecha apuntando a una
silla vacía y escribes, pon un oso de
peluche en la silla.
Como dar instrucciones en una pizarra.
Exactamente.
No hay que bucear en líneas de código.
El gesto de apuntar y escribir traduce la
intención del usuario a las coordenadas espaciales que
la IA necesita.
Y esa traducción funciona de manera tan fluida
porque el modelo mantiene una comprensión segura.
¿Tiene algún tipo de semántica constante de la
escena?
Claro, sabe dónde está cada cosa.
Cuando se dibuja la flecha, el sistema localiza
ese vector en su mapa Json, interno, y
aplica la modificación solicitada.
Ahora bien, el tutorial sí que destaca un
efecto secundario temporal de este método.
Interactivo.
¿Cuál es?
Las propias palabras escritas sobre la imagen.
A veces, al procesar este tipo de prompts
visuales, la IA puede dejar un residuo de
ese texto instructivo rojo, impreso en el resultado
final.
Ah, se cree que el texto rojo es
parte de la foto.
Exacto.
Lo trata por error como parte del contenido
gráfico.
Lo cual arruinaría la imagen, claro.
Si no fuera porque la solución es casi
absurdamente sencilla.
Basta con lanzar otra petición en texto indicando,
elimina el texto rojo.
Y la IA limpia la imagen al momento.
Empiende el contexto del error perfectamente.
Sí.
Además, el entorno cuenta con un historial de
deshacer y rehacer, lo que elimina el miedo
a experimentar.
Si un cambio estropea la composición, se vuelve
al estado anterior del JSON con un solo
clic.
Eso da muchísima tranquilidad.
Pero llegados a este punto, habiendo dominado la
alteración de objetos y estilos dentro del encuadre
original, el análisis entra en el terreno de
las capacidades del modelo superior, el Nano Banana
Pro.
Y me refiero a la manipulación del propio
encuadre, la relación de aspecto.
El cambio de proporciones es una de las
demostraciones técnicas más robustas del tutorial.
Se empieza con un retrato en formato panorámico
estándar, el clásico 16 novenos.
Sí.
Y al introducir el comando aspect -ratio 916,
la IA reconfigura instantáneamente el lienzo para adaptarlo
a un formato vertical de móvil.
Pasa por el formato cuadrado, llega incluso a
un formato ultra gran angular de 21 novenos.
Y esto es solo en la versión Pro,
¿no?
Bueno, cabe mencionar que, aunque se muestra en
el entorno Pro, la fuente original ya documentó
en videos anteriores que los usuarios de versiones
gratuitas también disponen de metodologías para lograr redimensionados
similares.
Ah, estupendo.
Pero la verdadera innovación aquí no es recortar
la imagen, sino el proceso de outpainting, la
expansión del lienzo.
Ese concepto merece que nos detengamos un momento.
El video muestra una fotografía de medio cuerpo
y el usuario introduce la instrucción, genera una
imagen de cuerpo entero de esta persona.
Llevando vaqueros y sosteniendo un maletín en proporción
9 -16.
Y fíjate que el modelo no estira los
píxeles hacia abajo.
No, no.
Inventa una realidad que nunca estuvo en el
archivo original.
Es un proceso de alucinación controlada sumamente complejo.
Para ejecutar esa expansión, la IA debe extrapolar
el contexto a partir de los datos existentes,
analiza la anatomía visible y deduce la postura
de las piernas.
O sea, calcula dónde estarían.
Claro.
Evalúa la caída de la luz en la
mitad superior y calcula cómo deberían comportarse las
sombras sobre unos vaqueros en la mitad inferior
inexistente.
Es que es increíble.
Introduce el maletín en la mano respetando la
perspectiva y genera la textura del suelo para
anclar al sujeto en el espacio.
No está ampliando un lienzo, está simulando el
resto del mundo físico basándose en las restricciones
del JSON original.
Pero a ver, esta simulación plantea un problema
físico ineludible.
Cuando fuerzas a una red neuronal a inventar
tanta información, nueva desde cero, o cuando cambias
ropa y objetos varias veces, la integridad de
los píxeles empieza a desmoronarse.
Sí, empiezan a aparecer cosas raras.
Suelen aparecer artefactos visuales, pérdida de nitidez en
los bordes, zonas borrosas, y ese clásico ruido
digital que te grita, esto es una imagen
generada por IA forzada al límite.
¿Cómo maneja el ecosistema de Gemini esta degradación
de la calidad?
Aborda la degradación a través de un proceso
de reconstrucción, que la fuente denomina Axe Scale,
o mejora de calidad.
Y lo hace sin depender de software de
terceros, que es lo importante.
Todo dentro de Gemini.
Todo.
Cuando la imagen evidencia pérdida de nitidez tras
expansiones agresivas, el usuario simplemente introduce el comando
Escala esta imagen a 4K.
Pero, ¿cómo funciona exactamente ese escalado?
Porque si simplemente multiplicamos los píxeles, tendríamos una
imagen más grande, pero igual de borrosa.
Exacto.
No es un escalado matemático tradicional.
Es un escalado generativo basado en modelos de
difusión.
Al pedir el salto a 4K, la IA
no estira la imagen.
¿Qué hace entonces?
Inyecta un nivel de ruido de alta frecuencia
en los píxeles degradados y utiliza su comprensión
semántica para resolver ese ruido en detalle puro.
O sea, ¿redibuja los detalles?
Eso es.
Sabe que una zona borrosa corresponde a la
tela de unos vaqueros.
Así que el proceso alucina la trama exacta
de ese tejido a resolución 4K.
Reconstruye poros en la piel, texturas en la
madera, nitidez en contornos, todo basándose en el
contexto global de la esquena.
¿Y sin tocar deslizadores de enfoque ni nada?
Nada.
Es una regeneración algorítmica completa.
Ven, recapitulemos el proceso un momento.
Se ha extraído el cóligo base, modificado el
color de los muebles, asimilado un estilo fotográfico,
cambiado el vestuario reescribiendo el código, operado visualmente
dibujando flechas, expandido el lienzo deduciendo las piernas
y el suelo, y finalmente escalado todo a
4K resolviendo cualquier imperfección.
Dicho así, suena a ciencia ficción.
Totalmente.
La imagen parece lista para producción, pero el
tutorial revera un último obstáculo, el enemigo número
uno de cualquier flujo de trabajo visual, las
marcas de agua incrustadas por la propia herramienta.
Sí, un elemento restrictivo que muchas plataformas implementan
por defecto para rastrear de dónde viene el
contenido.
Y la imagen final de esta demostración efectivamente
carga con una de estas herramientas.
Y es precisamente en este punto donde la
comunidad de desarrolladores brilla, ofreciendo una solución que
no requiere exportar el trabajo a programas de
retoque costosos ni andar clonando a mano.
¿Qué solución proponen?
El propio creador del tutorial proporciona acceso a
una herramienta gratuita, enlazada en la descripción, diseñada
específicamente para eliminar estas marcas de agua.
Lo destacable es que esta utilidad fue construida
previamente por él mismo utilizando Google AI Studio.
Qué inteligente.
El flujo de trabajo para eliminar la marca,
además, es extremadamente minimalista.
Subes el renderizado final a esta herramienta dedicada,
usas una brocha digital para enmascarar la zona
del logotipo y ejecutas la acción, eliminar lo
seleccionado.
Así de fácil.
Sí, la herramienta analiza los píxeles circundantes y
genera un relleno contextual perfecto.
Te descargas un archivo prístino.
Esto plantea una pregunta importante sobre la actual
autonomía del ecosistema técnico.
A ver.
Tradicionalmente, superar barreras como la eliminación de marcas
de agua o la edición compleja exigía dominar
plataformas basadas en capas, máscaras de recorte, modos
de fusión… Horas de tutoriales, vamos.
Claro.
Hoy, esos problemas se resuelven mediante instrucciones en
lenguaje natural y con microherramientas que los propios
creadores están ensamblando utilizando modelos de lenguaje.
La inteligencia artificial no solo genera el arte.
Está facilitando la creación de los propios andamios
técnicos necesarios para refinarlo.
Entonces, ¿qué significa todo esto a nivel fundamental?
Si contemplamos el arco completo de estas técnicas,
queda claro que se ha producido una transición
radical.
Hemos abandonado el enfoque de la máquina tragaperras
donde metías palabras esperando un golpe de suerte
estético.
Totalmente.
Y hemos adoptado el uso de un bisturí
de precisión paramétrica.
Comprender que cualquier imagen puede reducirse a un
archivo JSON manipulable permite desde alterar objetos individuales,
manteniendo la luz, hasta aplicar etalonajes cinematográficos a
sujetos nuevos, expandir universos y perfeccionar la resolución
al milímetro.
Todo gobernado dentro de Gemini Nano, Banana 2
y Pro.
Sí.
Es que la precisión técnica ha dejado de
ser una limitación para la IA generativa y
se ha convertido en su principal motor.
Y esto conduce a una reflexión profunda.
Si es posible extraer conceptos tan abstractos como
la atmósfera o la técnica fotográfica, convertirlos en
datos y reescribirlos, el concepto clásico de la
fotografía como captura irrefutable de la realidad entra
en crisis.
Es un cambio filosófico, casi.
Históricamente, la imagen congelaba un instante inmutable en
el tiempo.
Sin embargo, cuando la realidad visual de una
escena puede alterarse drásticamente cambiando la palabra camiseta
por traje en una línea de código, sin
dejar rastro de manipulación, ya no te puedes
fiar.
la imagen abandona su condición de documento estático.
Se transforma en un borrador infinito.
Un estado líquido donde la realidad representada es
perpetuamente maleable.
Borrador infinito.
Wow.
Es un concepto fascinante que altera por completo
la percepción de lo que consideramos una imagen
terminada.
Saber que cualquier renderizado es en el fondo
una matriz de datos susceptible de ser reescrita
desde sus cimientos desafía nuestra concepción del arte
digital.
Muchísimas gracias por acompañarnos en esta inmersión a
fondo.
Es un momento ideal para que la audiencia
busque imágenes propias, intente extraer sus datos y
ponga a prueba estas técnicas.
Quien se anime se dará cuenta rápidamente de
que el control absoluto sobre el lienzo digital
ya no es una promesa futura, sino una
realidad accesible hoy mismo.
Exacto.
Antes de despedirnos hasta el próximo programa, os
informamos de que las voces que oyes han
sido generadas por la IA de Notebook LM
y que dirigiendo al podcast se encuentra Julio
Pablo Vázquez, un humano que te envía saludos.
En caso de error, probablemente sean errores humanos.
¡Nos escuchamos!
El episodio de hoy.
Muchas gracias por tu atención.
Esto es BIM Praxis.
Nos escuchamos en el próximo episodio.