Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:09
0:15
0:20
0:23
0:26
0:28
0:36
0:40
0:41
0:44
0:46
0:48
0:49
0:51
0:54
0:54
0:57
1:00
1:02
1:05
1:06
1:11
1:14
1:15
1:16
1:18
1:20
1:22
1:23
1:26
1:30
1:34
1:35
1:36
1:38
1:39
1:41
1:42
1:44
1:46
1:48
1:50
1:50
1:53
1:55
1:57
1:58
2:00
2:01
2:03
2:04
2:06
2:08
2:09
2:11
2:13
2:15
2:16
2:18
2:20
2:22
2:22
2:25
2:28
2:31
2:33
2:33
2:34
2:37
2:39
2:42
2:44
2:45
2:46
2:50
2:53
2:54
2:55
2:56
2:59
3:02
3:03
3:06
3:07
3:08
3:11
3:13
3:15
3:16
3:18
3:19
3:22
3:25
3:29
3:30
3:31
3:34
3:38
3:41
3:42
3:43
3:46
3:48
3:49
3:51
3:51
3:54
3:55
3:57
3:58
3:59
4:01
4:06
4:07
4:10
4:11
4:12
4:15
4:18
4:20
4:21
4:24
4:25
4:27
4:30
4:31
4:32
4:34
4:37
4:39
4:42
4:44
4:46
4:47
4:49
4:51
4:52
4:54
4:56
4:58
4:59
5:01
5:04
5:07
5:08
5:11
5:12
5:13
5:17
5:20
5:22
5:23
5:25
5:27
5:29
5:32
5:35
5:39
5:39
5:43
5:43
5:45
5:48
5:48
5:51
5:51
5:52
5:54
5:57
5:58
6:01
6:02
6:05
6:05
6:07
6:10
6:12
6:12
6:12
6:13
6:14
6:17
6:19
6:22
6:23
6:24
6:26
6:29
6:30
6:32
6:33
6:36
6:39
6:39
6:42
6:46
6:47
6:50
6:51
6:54
6:54
6:57
6:59
7:02
7:05
7:07
7:09
7:10
7:13
7:13
7:15
7:18
7:22
7:23
7:25
7:27
7:29
7:32
7:33
7:35
7:36
7:40
7:40
7:41
7:42
7:44
7:46
7:49
7:50
7:52
7:52
7:56
7:58
8:00
8:00
8:03
8:05
8:08
8:09
8:10
8:13
8:17
8:18
8:20
8:22
8:24
8:26
8:30
8:30
8:32
8:34
8:35
8:39
8:42
8:45
8:47
8:50
8:51
8:53
8:56
8:58
8:59
9:01
9:01
9:05
9:07
9:09
9:12
9:17
9:19
9:21
9:22
9:24
9:24
9:27
9:29
9:32
9:33
9:35
9:37
9:37
9:39
9:41
9:43
9:45
9:48
9:48
9:51
9:53
9:56
9:57
10:00
10:03
10:06
10:07
10:10
10:13
10:15
10:18
10:19
10:22
10:24
10:26
10:29
10:31
10:34
10:34
10:35
10:37
10:39
10:41
10:42
10:42
10:46
10:50
10:53
10:55
10:56
10:58
10:58
11:01
11:04
11:06
11:07
11:10
11:11
11:14
11:18
11:21
11:21
11:24
11:24
11:26
11:28
11:31
11:33
11:36
11:36
11:39
11:40
11:43
11:45
11:46
11:47
11:49
11:52
11:53
11:54
11:56
11:58
11:58
12:01
12:03
12:03
12:05
12:08
12:11
12:13
12:14
12:15
12:16
12:18
12:21
12:24
12:25
12:27
12:28
12:30
12:32
12:35
12:36
12:38
12:39
12:41
12:44
12:44
12:47
12:50
12:53
12:53
12:56
13:00
13:02
13:04
13:06
13:07
13:10
13:14
13:15
13:16
13:17
13:20
13:22
13:24
13:26
13:28
13:29
13:31
13:34
13:36
13:38
13:39
13:41
13:43
13:45
13:49
13:51
13:54
13:56
13:59
14:00
14:01
14:03
14:05
14:07
14:08
14:09
14:10
14:12
14:16
14:18
14:19
14:21
14:24
14:26
14:27
14:29
14:32
14:33
14:36
14:36
14:38
14:41
14:44
14:46
14:47
14:49
14:51
14:54
14:56
14:57
14:58
15:00
15:01
15:05
15:07
15:09
15:10
15:11
15:15
15:18
15:19
15:23
15:26
15:29
15:31
15:32
15:35
15:36
15:38
15:40
15:42
15:42
15:44
15:48
15:51
15:51
15:54
15:54
15:56
15:58
16:01
16:01
16:05
16:05
16:07
16:10
16:13
16:16
16:18
16:21
16:21
16:22
16:23
16:26
16:28
16:31
16:32
16:33
16:35
16:38
16:42
16:44
16:45
16:46
16:48
16:49
16:52
16:55
16:56
16:58
17:00
17:04
17:07
17:08
17:11
17:13
17:15
17:17
17:19
17:20
17:23
17:24
17:26
17:28
17:30
17:33
17:34
17:38
17:41
17:42
17:45
17:48
17:51
17:52
17:54
17:56
17:58
18:01
18:03
18:05
18:05
18:08
18:09
18:12
18:13
18:16
18:18
18:19
18:20
18:23
18:25
18:29
18:30
18:32
18:33
18:35
18:37
18:38
18:41
18:44
18:47
18:48
18:51
18:51
18:55
18:55
18:58
19:01
19:03
19:05
19:06
19:08
19:11
19:14
19:15
19:16
19:18
19:19
19:24
19:27
19:29
19:31
19:34
19:36
19:37
19:39
19:43
19:44
19:46
19:48
19:51
19:53
19:54
19:56
19:59
20:01
20:03
20:04
20:07
20:09
20:10
20:12
20:14
20:17
20:19
20:20
20:21
20:24
20:26
20:26
20:30
20:32
20:33
20:34
20:38
20:39
20:42
20:44
20:45
20:48
20:51
20:54
20:56
20:57
20:58
21:01
21:03
21:04
21:07
21:08
21:10
21:12
21:13
21:15
21:16
21:18
21:20
21:20
21:22
21:23
21:25
21:27
21:29
21:32
21:34
21:38
21:39
21:41
21:45
21:47
21:49
21:49
21:53
21:57
22:00
22:01
22:02
22:05
22:08
22:10
22:12
22:15
22:17
22:19
22:22
22:25
22:26
22:30
22:32
22:32
22:36
22:38
22:41
22:44
22:46
22:49
22:51
23:04
23:15
23:18
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas, bienvenidas, bienvenidos a un nuevo episodio
de BIMPRAXIS.
Hoy os traemos la revolución del código abierto
para crear tu propio asistente de inteligencia artificial.
¡Sin volverte loco!
¡Ragflow!
Eso es, un análisis a fondo que, la
verdad, hace muchísima falta hoy en día.
Totalmente.
Porque, a ver, resulta muy familiar esa sensación
de frustración generalizada con las IAS genéricas, ¿verdad?
Uf, hombre, claro que sí.
Esa situación recurrente en la oficina donde, no
sé, alguien le pide a una de estas
inteligencias artificiales famosísimas que redacte un informe estratégico.
Sí, o que resuelva una duda hiperespecífica sobre
un proyecto interno.
¡Exacto!
Y la respuesta es, bueno, en fin, una
colección de generalidades absolutas.
Una parrafada que no dice nada, vaya.
Tal cual.
O sea, suenan estupendamente bien.
Están redactadas con una prosa envidiable, pero no
aportan absolutamente nada de valor real al problema
de esa empresa.
Cero valor, claro.
Pero, a ver, si se analiza con frialdad,
tiene toda la lógica del mundo.
Ya, no es culpa del modelo en sí.
Exacto, no lo es.
Al fin y al cabo, esa IA genérica,
por muy potente que sea, no tiene acceso
a los documentos internos de la organización.
Claro, ¿no se ha leído los manuales?
Eso es.
No conoce las intrincadas políticas de la empresa,
ni los historiales de incidentes de los clientes.
Hay que matizar que esa IA genérica es
brillante en su campo, ¿eh?
Sí, sí, te escribe un poema en cinco
segundos.
Hombre, sabe cómo escribir un soneto al estilo
de Cervantes, desde luego.
Pero en el contexto del día a día
corporativo, padece una amnesia total sobre lo que
realmente importa.
No tiene ni idea de cuál es el
protocolo de devoluciones, por ejemplo.
Ni idea, para nada.
Exactamente por eso.
La misión de nuestra exploración de hoy es
crucial para quien nos escucha.
Vamos a sumergirnos de lleno.
Así es.
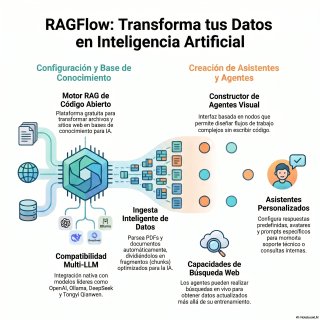
Vamos a analizar cómo RackFlow, que además es
una plataforma de código abierto y completamente gratuita,
ataca exactamente este cuello de botella.
Y lo hace operando como un motor Rack,
¿verdad?
Exacto.
Un motor de generación aumentada por recuperación.
El objetivo de este análisis a fondo es
destripar cómo esta herramienta consigue algo que, bueno,
parece magia pura.
Transforma la información estática.
Sí.
Transforma repositorios enteros de documentos, páginas web corporativas
y esos PDFs infumables que nadie lee.
Esos de 500 páginas.
Madre mía.
Esos mismos.
Los convierte en una base de conocimientos dinámica,
viva y perfectamente estructurada para alimentar a chatbots
interactivos.
O sea, la democratización definitiva de la IA
avanzada.
Eso es.
Poniéndola al alcance de cualquier entidad sin requerir
presupuestos astronómicos.
Bueno, vamos a desgranar esto porque...
La promesa es enorme.
Y hay que empezar por el principio.
Por los cimientos, claro.
Antes de que esa flamante inteligencia artificial pueda
ponerse a devorar manuales corporativos y a escupir
respuestas magistrales, hay un paso previo ineludible.
Saber dónde va a alojarse.
Exacto.
Decidir dónde va a vivir ese celebro digital.
Porque, tradicionalmente, levantar y mantener este tipo de
arquitecturas en servidores propios solía ser, bueno, una
pesadilla.
Un dolor de cabeza tremendo.
Era el equivalente tecnológico a intentar construir un
coche de Fórmula 1 desde cero en el
garaje de casa.
Ojo la analogía, que es muy buena.
Es que es así.
Se compran las piezas sueltas, se ensamblan y
se reza fuerte para que el motor no
explote en la primera curva.
Y muchas veces explota.
Totalmente.
Y a ver, Ragflow, al ser de código
abierto, permite precisamente esa vía del alojamiento propio,
lo que se llama self -hosted.
Para quien quiera aliarse la manta a la
cabeza y montarlo en su servidor.
Eso es.
Pero la realidad es que existe una alternativa
que altera por completo las reglas del juego.
Las plataformas en la nube.
Exacto.
Plataformas de despliegue gestionado, como por ejemplo el
Estio.
Siguiendo con la analogía del coche, recurrir a
esto sería como, digamos, hacer un renting.
Un renting integral, sí.
Claro.
El vehículo llega impecable y el contrato ya
incluye los mantenimientos preventivos, el seguro a todo
riesgo y los cambios de aceite.
Ojo, porque la analogía del renting es buenísima.
Pero se queda corta si no miramos el
coste de oportunidad real para una empresa.
¿En qué sentido?
Pues que no se trata solo de la
comodidad de que te den el coche listo
para conducir, ¿no?
Se trata de la eliminación casi total de
la barrera técnica.
Esa barrera que frena todo.
Claro.
Es que esa barrera bloquea el 90 %
de los proyectos de innovación hoy en día.
Históricamente, el gran muro de contención no era
el precio del software.
Era el miedo a romper algo, estoy segura.
Más bien el terror del departamento.
El terror del departamento de infraestructura.
Levantar un sistema complejo implica lidiar con dependencias,
contenedores, actualizaciones constantes.
Y el pánico absoluto a perder los datos.
Exacto.
Pero al utilizar una solución gestionada como el
Estio, el proceso se vuelve invisible.
Te quitas ese peso de encima.
La plataforma subyacente asume el verdadero trabajo sucio.
Hablamos de la gestión de copias de seguridad
automatizadas, la monitorización, los parches críticos de seguridad.
Claro.
Y desde una perspectiva puramente estratégica, esto es
oro.
Permite que los equipos se enfoquen en lo
que aporta valor, que es el conocimiento en
sí.
En vez de pelearse con la terminal de
comandos.
Eso es.
De hecho, el despliegue es tan fluido que
la principal preocupación pasa a ser puramente de
arquitectura.
Quien lidera el proyecto simplemente toma decisiones de
alto nivel.
Decisiones como la ubicación de los servidores.
Exactamente.
Elegir el proveedor en la nube más adecuado
o decidir la región geográfica.
Que a ver, este último detalle no es
baladero.
No es baladí, ¿eh?
En absoluto.
Hombre, para nada.
En un entorno corporativo, decidir si los datos
se alojan en Europa o en Estados Unidos
lo cambia todo, a nivel de cumplimiento normativo
y privacidad.
Totalmente.
La soberanía de los datos es un tema
hipercrítico cuando hablamos de subir el know -how
interno de una empresa a una IA.
No se puede subir a cualquier sitio.
Claro que no.
Y otra decisión fundamental en esa fase es
el nivel de soporte técnico que respalda la
infraestructura.
¿Y una vez definido todo eso?
Una vez definidas esas variables estratégicas, el despliegue
se ejecuta en segundo plano.
Es la magia del código abierto combinado con
el cloud gestionado.
En cuestión de minutos lo tienes.
Literalmente.
Se pasa de no tener nada a disponer
de un panel de control completo, con módulos
de chat, agentes, bases de conocimiento.
Todo listo para operar de forma privada.
Vale, o sea, ya tenemos la casa construida,
el servidor está blindado y tenemos las llaves
en la mano.
Ahora toca traer al inquilino.
Exacto.
Traer al inquilino inteligente.
Hay que conectar el modelo de lenguaje, el
LLM, y proporcionarle una biblioteca en condiciones.
Eso es.
Por defecto, Rackflow arranca con un modelo llamado
Tongji Qiangwen.
Pero, a ver, la verdadera potencia de una
arquitectura abierta reside en su flexibilidad.
Desde luego.
Obligar a usar un único modelo sería un
error garrafal.
La plataforma brilla precisamente porque permite interconectar los
motores de control.
Pero, ¿qué pasa con los motores más potentes
del mercado?
La interoperabilidad es la palabra clave aquí.
Aunque este modelo predeterminado tiene su utilidad para
empezar, la arquitectura permite enchufar modelos de la
talla de OpenEI.
O incluso cosas más privadas, ¿no?
Sí, sí.
Instancias locales y 100 % privadas, utilizando Oyama
o las últimas versiones de DeepSeq.
¿Y es muy complicado conectarlos?
Qué va.
La conexión suele requerir únicamente la clave de
la interfaz, la famosa API key.
Se pega ahí y Rackflow empieza a comunicarse
con el modelo al instante.
Perfecto.
Entonces, el cerebro ya está conectado y latiendo.
El siguiente paso lógico es construir esa biblioteca
de la que hablábamos.
Crear la base de conocimientos pura y dura.
Eso es.
Imaginemos un caso práctico para la audiencia.
Se crea un espacio de trabajo.
Se le asigna un logotipo corporativo para que
quede bonito.
Se selecciona el idioma.
Y se establecen los permisos de acceso.
Muy importante, sí.
Para determinar qué departamentos pueden consultar qué información.
Pero, a ver, aquí es donde la curva
de aprendizaje suele ponerse empinada.
Ah, ya sé por dónde vas.
Nos topamos con la jerga pura y dura
del sector.
Empezamos a oír hablar de los infames embeddings
y de los métodos de chunking.
Sí, la matemática oculta.
Y a ver, voy a hacer de abogada
del diablo un momento, ¿vale?
Adelante.
Es absolutamente vital entender toda esta matemática de
vectores, embeddings y chunks.
Es una pregunta súper lícita.
Es que suena a una cantidad de terminología
técnica completamente innecesaria para alguien que, francamente, lo
único que desea es que un bot responda
a dudas de un PDF.
Ya, da la sensación de que hay que
hacerle el trabajo a la máquina.
Claro.
Parece que hay que masticarle la comida a
la IA para que su cerebro la digiera.
Y el resultado visual, cuando ves esos chunks,
parece un caos total.
Es una excelente objeción, la verdad.
Pero hay que aclarar que no es sólo
masticar la comida.
Es cambiar el idioma en el que está
escrita la realidad para la máquina.
A ver, explícame eso.
Lo fascinante aquí es entender la mecánica oculta.
Porque sin ella, todo el concepto de rack
se desmorona.
Un modelo de embedding no hace otra cosa
que traducir el texto a coordenadas.
Coordenadas hiperdimensionales, he leído por ahí.
Exacto.
Imaginemos una biblioteca gigantesca.
Pero en lugar de ordenar los libros alfabéticamente
por el autor, se ordenan físicamente por el
sabor o la esencia de sus contenidos.
Vale, me gusta la idea.
En esta biblioteca abstracta, un libro sobre manzanas
se coloca muy cerca de un libro sobre
peras porque comparten la coordenada de fruta.
Tiene sentido.
Pero ambos están a kilómetros de distancia de
un manual sobre, no sé, bujías de coche.
Eso es un vector.
Convierte conceptos abstractos en distancias matemáticas.
Y así la IA busca más rápido.
Claro, calcula similitudes a la velocidad de la
luz.
Vale.
La analogía de la biblioteca aclara bastante.
El tema de los embeddings.
Pero, ¿qué ocurre con el chunking?
La fragmentación.
Sí.
¿Por qué existe esa necesidad imperiosa de despedazar
un documento que está perfectamente maquetado y estructurado?
Porque los modelos de lenguaje, por muy avanzados
que sean hoy, tienen una ventana de atención
limitada.
O sea que se pierden.
Exacto.
Si se introduce un manual técnico de 500
páginas de golpe, la IA pierde el hilo.
Olvida lo que le dio en la página
2 al llegar a las 300.
Como nos pasa a los humanos, vaya.
Tal cual.
El chunking soluciona esto troceando el documento en
fragmentos manejables, con un ligero solapamiento entre ellos
para no perder el contexto de las frases.
Ya entiendo.
¿Y sobre lo que comentaba antes del caos
visual?
Es muy pertinente.
Cuando el sistema procesa el documento y muestra
esos chunks resultantes en la pantalla, el texto
aparece deslavazado.
Lleno de etiquetas y metadatos rarísimos.
Sí.
No se ve nada bonito ni es fácilmente
elegible para un ojo humano.
Pero hay que asimilar que ese formato fragmentado
no está diseñado para nosotros.
Está hecho para la máquina.
Exacto.
Es la estructura más eficiente para que la
máquina indexe y recupere el conocimiento con precisión
quirúrgica.
Vale.
Entonces, ¿quien gestiona esto no tiene que ser
un experto en álgebra vectorial?
Para nada.
La plataforma ya proporciona parámetros por defecto que
asumen todo este trabajo pesado.
Menos mal.
Porque a la hora de alimentar al sistema,
el enfoque… resulta súper práctico.
Imaginemos que el equipo de soporte guarda una
web de preguntas frecuentes en PDF y las
sube.
La arrastra al panel y listo.
Eso es.
El motor aplica esa magia de los embeddings,
trocea el texto y lo indexa solo.
Y de cara a escenarios empresariales, resulta interesantísimo
ver hacia dónde va esto.
¿Hacia la automatización total?
Exacto.
La sincronización automatizada.
En lugar de arrastrar archivos manualmente, el sistema
permite conectar repositorios masivos en la nube, como
Amazon S3.
O sea que la base se actualiza sola.
Literalmente.
En cuanto alguien sube un documento nuevo al
servidor interno de la empresa, la IA se
lo aprende.
Y esa automatización de la ingesta de datos
es lo que transforma un simple experimento curioso
en una herramienta seria, de grado impresarial.
Totalmente.
Pero, claro, una vez que ese PDF está
digerido y convertido en coordenadas matemáticas, surge un
reto de confianza monumental.
El gran elefante en la habitación.
Cómo se audita una caja negra.
Esa es una pregunta clave.
Claro, trocear el documento y pasarlo a vectores
suena super eficiente en teoría, pero el miedo
siempre es el mismo.
¿Nos podemos fiar?
Exacto.
El miedo en cualquier consejo de administración es,
¿cómo nos fiamos de que la máquina realmente
se ha enterado de algo antes de poner
a este bot a hablar con clientes?
¿No se puede simplemente cruzar los dedos?
Desde luego que no.
Y por eso no se cruzan.
Se implementan pruebas de recuperación.
El famoso Retrieval Testing.
Las pruebas de fuego.
Eso es.
Antes de que el modelo formule una frase
completa, hay que verificar que el motor de
búsqueda interno funciona.
Se introducen términos críticos, como tiempos de respuesta.
Para ver si pesca el dato correcto.
Para observar exactamente qué fragmentos rescata la base
de datos de entre sus miles de vectores.
Pero no basta con encontrar coincidencias sueltas.
Claro, habrá mucho ruido.
Muchísimo.
Aquí entra en juego un concepto vital.
El modelo de reclasificación.
O re -rank.
Un momento.
Reclasificación.
Sí, sí.
Si el sistema ya ha buscado los vectores
más cercanos en nuestra famosa biblioteca de sabores,
¿para qué necesita volver a clasificar nada?
Parece redundante.
Podría parecerlo, pero es un doble filtro de
calidad imprescindible, te lo aseguro.
La primera búsqueda vectorial es muy rápida, pero
muy amplia.
O sea, trae de todo un poco.
Puede rescatar 50 fragmentos que hablan vagamente de
reembolsos, por ejemplo.
Pero muchos podrían estar fuera de contexto.
Vale.
El modelo de re -rank es un modelo
más lento y analítico, que toma esos 50
resultados y los somete a un escrutinio profundo
contra la pregunta original.
O sea, ¿hace una criba?
Descarta el ruido y ordena los tres o
cuatro fragmentos verdaderamente cruciales.
Y sólo esa información hiperrefinada es la que
se le entrega a la IA para redactar
la respuesta.
Es brillante.
Y aquí es donde se pone verdaderamente interesante
la aplicación práctica.
Una vez verificado que los engranajes funcionan gracias
a ese doble filtro, se crea el asistente.
El chatbot final con el que interactúa el
usuario.
Exacto.
Se define su personalidad, el tono, si tiene
un avatar… Pero hay una configuración concreta que
me parece un salvavidas absoluto.
La respuesta de vacío o empty response.
Uff, esa función es clave.
Permite programar con exactitud qué debe articular la
IA cuando busca en los vectores y descubre
que no tiene respuesta.
Algo simple como, no lo sé, preguntaré a
soporte.
Hay que detenerse en este punto, porque supone
un cambio cultural inmenso.
¿En nuestra relación con la IA?
Sí.
El gran problema de la IA generativa actual,
su talón de Aquiles, son las alucinaciones.
Esa tendencia casi patológica a inventarse respuestas y
fechas.
Con una seguridad pasmosa, además.
Exacto.
Cuando se encuentra en un callejón sin salida,
se lo inventa.
En el entorno corporativo se penaliza mucho decir,
no lo sé.
Pero hablando de algoritmos, la honestidad algorítmica vale
oro.
Es infinitamente preferible, claro.
Es preferible un asistente que admita sus limitaciones
y detenga el proceso, antes que un bot
que decida inventarse, no sé, una promoción del
50 % de descuento.
Que provoca una crisis de relaciones públicas en
segundos.
Tal cual.
Totalmente de acuerdo.
Es honestidad por diseño.
Y esto enlaza con el otro pilar de
la confianza, para quien nos escucha, la trazabilidad.
Ah, las citas.
Exacto.
Cuando el asistente entra en acción y se
le hace una pregunta compleja, devuelve una respuesta
maravillosamente estructurada con sus negritas y viñetas.
Nada que ver con los chunks feos de
antes.
Para nada.
Pero la joya de la corona aparece al
final.
El sistema incluye una cita precisa indicando de
qué PDF e incluso de qué párrafo exacto
ha extraído el dato.
Es vital para auditar.
Es como tener a un analista junior que…
No sólo entrega un resumen impecable, sino que…
Coloca el manual abierto por la página exacta
de la evidencia.
Esa es la gran diferencia entre un generador
de texto al uso y un sistema de
gestión del conocimiento real.
Si hay dudas, se revisa la cita.
La fuente siempre es auditable.
Transparencia total.
Y además, la arquitectura permite pivotar sobre la
marcha.
Si se percibe que el modelo es demasiado
lento razonando, se cambia el motor por otro
más ágil, como un modelo mini.
Sin reconstruir toda la base de datos.
¡Qué pasada!
Todo esto dibuja un ecosistema fantástico y ultraseguro.
Pero… presenta un límite claro.
A ver.
Hasta aquí hemos analizado un cerebro brillante encerrado
en una habitación llena de archivadores estáticos.
Pero, ¿qué ocurre cuando la realidad supera esos
documentos?
El mundo exterior, claro.
Las normativas de la empresa pueden ser fijas,
pero el mundo cambia cada segundo.
¿Qué pasa si la respuesta depende de conocer
una noticia publicada hace tres horas?
O el estado de la bolsa.
Exacto.
Datos que simplemente nunca se incluyeron en los
PDFs de la empresa.
Ahí es donde la tecnología RAC tradicional choca
contra un muro.
Un modelo entrenado hace un año, con PDFs
de hace un mes, no puede responder a
una crisis de hoy.
Lógico.
Para romper ese aislamiento, se requiere una capa
superior de autonomía, la orquestación de agentes.
Esto transforma un sistema pasivo en un investigador
activo que sale a Internet.
Y el método para construir estos agentes es
fascinante.
Quien espere ver pantallas negras llenas de código
se llevará una sorpresa masiva.
Súper accesible.
La interfaz se basa en nodos visuales.
Para conceptualizarlo, es muy parecido a plataformas como
N8N o incluso a jugar con piezas de
LEGO lógicas.
Arrastrar y soltar cajitas, básicamente.
Eso es.
Permite diseñar flujos complejos arrastrando cajas y conectándolas
con fuentes.
Y un detalle brillante es que cada caja
viene con comentarios didácticos explicando su función.
Y ojo, que el diseño basado en nodos
no es un simple lavado de cara estético.
No.
Es una abstracción conceptual poderosísima.
Permite que mentes no técnicas, pero que conocen
bien el negocio, puedan diseñar la lógica.
Diseñar sin picar código.
Exacto.
Una fente de búsqueda web no es más
que una secuencia.
Recibir pregunta, extraer palabras clave, buscar en Internet,
leer resultados, combinar con datos internos y responder.
Pero claro, la teoría es preciosa hasta que
el código choca con la realidad.
Imaginemos que ensamblamos esas piezas de LEGO para
preguntar la fecha de nacimiento de Napoleón.
Un ejemplo clásico.
Se le da el botón de ejecutar y…
el sistema colapsa en vivo.
Lanza un error.
Pasa en las mejores familias.
Pero lejos de ser un drama, estos fallos
resultan ser la mejor clase magistral.
El fallo no ocurre porque la IA sea
tonta.
Suele ser un tema de configuración.
En ese cirujo específico, el sistema estaba configurado
para llamar a un modelo de deep -seq
que no tenía los permisos habilitados en ese
momento.
Y la resolución de ese incidente ilustra el
verdadero cambio de paradigma en el mantenimiento del
software.
Es facilísimo de arreglar.
Hace unos años, solucionar un error de llamadas
a una API requería bucear entre cientos de
líneas de código, leer logs crípticos y cruzar
los dedos.
Una tortura.
En este entorno visual, el error se ilumina.
Se ilumina directamente en las cajitas afectadas, en
rojo.
La solución pasa únicamente por identificar esos nodos.
El de refinar la pregunta y el de
generar la respuesta, por ejemplo.
Exacto.
Abrirlos y, con un menú desplegable, reemplazar el
motor ausente por uno activo.
Como la versión mini de GPT -4.
Y a correr.
Efectivamente.
Se aplican los cambios, se vuelve a ejecutar
y esta vez el flujo es hipnótico.
Se puede ver cómo la información viaja por
las flechas, cómo busca la fecha.
El 15 de agosto, claro.
Eso es.
Y cómo entrega la respuesta final añadiendo el
enlace a Wikipedia como prueba de su investigación
en tiempo real.
Esto pantea una cuestión que trasciende la simple
automatización de tareas.
Dotar a un modelo de lenguaje de la
capacidad de orquestar búsquedas web.
Lo cambia todo.
Destruye para siempre la barrera del corte de
conocimiento.
La IA ya no está limitada por los
datos con los que fue entrenada en el
pasado.
Es la fusión definitiva.
Totalmente.
Por un lado, se dispone del conocimiento privado
de la empresa y, por otro, de la
inmensidad de datos de Internet.
Y el puente es un sistema visual para
que cualquiera construya empleados digitales.
Se democratiza el rol de ingeniero de automatización,
desde luego.
Y para terminar de consolidar todas las piezas
de este rompecabezas, resulta interesante plantear una reflexión.
A ver, cuéntanos.
Una reflexión de cara al futuro a corto
plazo.
Hemos diseccionado cómo ecosistemas gratuitos de código abierto
eliminan la fricción para crear sistemas hipercomplejos.
Sistemas con memoria y trazabilidad.
Exacto.
Y con honestidad algorítmica.
Si la barrera técnica y financiera ha quedado
reducida a cenizas, ¿cómo va a cambiar esto
la arquitectura de los departamentos corporativos?
Uf, es una gran pregunta.
¿Cómo evolucionará el estudio académico y la síntesis
de información masiva en la próxima década?
Va a ser un salto tremendo.
Resulta evidente que el límite ya no reside
en los presupuestos de servidores, ni en la
complejidad del código.
La última frontera es nuestra propia imaginación para
diseñar los flujos de trabajo de la próxima
era.
Antes de despedirnos hasta el próximo programa, os
informamos de que las voces que oyes han
sido generadas por la IAE de Notebook LM,
y que dirigiendo el podcast se encuentra Julio
Pablo Vázquez, un humano que te envía saludos.
En caso de error, probablemente sean errores humanos.
¿Nos escuchamos?
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMpraxis.
Nos escuchamos en el próximo episodio.