Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:09
0:15
0:20
0:23
0:26
0:28
0:36
0:39
0:40
0:43
0:45
0:46
0:48
0:51
0:53
0:56
0:59
1:00
1:01
1:03
1:05
1:06
1:06
1:08
1:10
1:14
1:16
1:16
1:19
1:21
1:22
1:24
1:26
1:28
1:29
1:32
1:33
1:35
1:35
1:37
1:39
1:42
1:44
1:46
1:49
1:52
1:55
1:56
1:58
2:00
2:01
2:04
2:07
2:08
2:09
2:11
2:12
2:13
2:15
2:17
2:18
2:20
2:24
2:27
2:29
2:32
2:33
2:35
2:37
2:40
2:41
2:44
2:45
2:46
2:48
2:51
2:53
2:56
2:57
2:57
3:01
3:02
3:05
3:07
3:08
3:11
3:14
3:18
3:20
3:22
3:25
3:26
3:26
3:29
3:33
3:35
3:36
3:39
3:41
3:42
3:43
3:45
3:46
3:48
3:50
3:51
3:53
3:57
3:59
4:03
4:05
4:06
4:10
4:11
4:14
4:16
4:18
4:20
4:21
4:24
4:26
4:28
4:30
4:32
4:33
4:35
4:37
4:39
4:40
4:42
4:45
4:45
4:47
4:50
4:53
4:54
4:55
4:58
5:00
5:02
5:04
5:07
5:08
5:09
5:12
5:13
5:16
5:18
5:20
5:21
5:21
5:24
5:27
5:28
5:31
5:34
5:35
5:38
5:41
5:42
5:46
5:49
5:50
5:53
5:54
5:55
5:57
5:57
6:00
6:03
6:05
6:08
6:09
6:12
6:12
6:13
6:14
6:17
6:19
6:20
6:23
6:24
6:26
6:28
6:31
6:34
6:36
6:37
6:38
6:41
6:44
6:47
6:49
6:51
6:53
6:53
6:55
6:56
6:57
7:00
7:01
7:04
7:06
7:08
7:10
7:12
7:16
7:17
7:20
7:23
7:26
7:28
7:29
7:31
7:34
7:36
7:39
7:41
7:41
7:44
7:46
7:49
7:52
7:54
7:56
8:00
8:01
8:02
8:04
8:06
8:06
8:10
8:12
8:16
8:17
8:20
8:21
8:24
8:27
8:29
8:31
8:33
8:34
8:35
8:37
8:40
8:41
8:42
8:43
8:46
8:49
8:51
8:53
8:55
8:56
8:58
9:01
9:03
9:05
9:07
9:11
9:12
9:12
9:13
9:16
9:17
9:18
9:21
9:23
9:25
9:28
9:29
9:33
9:34
9:38
9:39
9:41
9:42
9:45
9:47
9:48
9:51
9:53
9:54
9:57
9:58
10:01
10:04
10:08
10:10
10:13
10:18
10:20
10:23
10:24
10:26
10:27
10:29
10:32
10:34
10:35
10:37
10:40
10:42
10:44
10:45
10:47
10:48
10:51
10:53
10:54
10:55
10:56
10:58
11:01
11:02
11:05
11:06
11:08
11:11
11:13
11:16
11:18
11:21
11:23
11:24
11:25
11:25
11:27
11:30
11:32
11:34
11:34
11:37
11:40
11:43
11:45
11:46
11:46
11:50
11:53
11:56
11:57
12:00
12:02
12:05
12:05
12:08
12:09
12:10
12:12
12:16
12:19
12:22
12:24
12:25
12:26
12:29
12:31
12:32
12:34
12:34
12:36
12:39
12:42
12:44
12:47
12:51
12:53
12:55
12:57
13:01
13:04
13:07
13:09
13:12
13:14
13:15
13:18
13:20
13:23
13:26
13:30
13:33
13:35
13:37
13:39
13:40
13:42
13:45
13:45
13:48
13:49
13:52
13:54
13:55
13:58
14:01
14:02
14:05
14:08
14:10
14:10
14:13
14:15
14:17
14:19
14:23
14:25
14:27
14:28
14:31
14:33
14:35
14:38
14:40
14:41
14:44
14:47
14:48
14:51
14:53
14:56
14:59
15:11
15:13
15:24
15:27
15:28
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas, bienvenidas, bienvenidos a un nuevo episodio
de BIMPRAXIS.
Hoy os traemos OpenRouter frente a Requesti, la
gran batalla de los conectores de IA en
2026.
Y bueno, la verdad es que el material
que tenemos sobre la mesa hoy es tela.
O sea, procede de un análisis exhaustivo del
canal Toby Tiches y pone el foco en
algo que parece, no sé, puramente técnico, pero
que lo cambia todo.
Todo.
Es que cambia por completo las reglas del
juego en el desarrollo de software hoy en
día.
Exacto.
Y por eso, la promesa para quienes nos
escuchan es que, al terminar este análisis a
fondo, van a tener clarísimo qué infraestructura elegir.
Da igual si quieren montar un proyecto personal
el fin de semana.
O si lideran, yo que sé, una multinacional
con reglas de datos súper estrictas.
Eso es.
Y a ver, para entender bien la magnitud
de esto, imaginemos el escenario habitual de desarrollo
hasta cenada.
Alguien tiene una idea brutal para una app,
reúne a su equipo y se conectan, pues
digamos, a un modelo de OpenAI.
Claro, el camino clásico.
Sí, sí.
Pero luego llega el problema masivo.
Cada dos semanas el ecosistema cambia.
De repente Anthropic lanza un cloud nuevo que
es objetivamente mucho mejor para esa app.
Y claro, ¿eso qué implica?
Pues implica abrir otra cuenta corporativa, meter otra
tarjeta de crédito, generar claves nuevas y, lo
peor de todo, reescribir un montón de código.
Un cristo, vamos.
Un cristo importante.
Porque la forma en la que OpenAI recibe
los datos no tiene nada que ver con
cómo lo recibe Google con Gemini o Anthropic.
Unos usan JSON estructurado, otros separan el System
Prompt.
¿Pereza técnica?
¿La gente se quedaba anclada a un solo
proveedor?
Totalmente.
¿Te pardías los avances del mercado porque daba
mucha pereza?
Sí, sí, un clásico.
Y justo aquí es donde entran a resolver
el caos plataformas como OpenRouter y Requesty.
Actúan como una capa de abstracción, ofreciendo una
interroquerabilidad brutal.
Quien programa hace una sola integración y ¡boom!,
acceso a cientos de modelos.
A ver, vamos a desgranar esto.
Porque es casi como tener 20 mandos a
distancia distintos en la mesa del salón.
Que si el de la tele, el del
aire acondicionado, el del decodificador… Sí, sí, un
clásico.
Y de repente, pues te contamos… Compras un
mando universal, ¿no?
Pero, según los apuntes de Toby Tiches, no
es solo que este mando envíe la señal.
Es que actúa como un traductor simultáneo en
tiempo real.
Exacto.
Y lo fascinante aquí es precisamente ese matiz
de la traducción.
O sea, no es un simple redireccionamiento de
tráfico, sino que hay un procesamiento de la
sintaxis.
Si la aplicación envía una instrucción de temperatura
para controlar la creatividad, el conector la traduce
para que Gemini o Yamatress… la entiendan perfectamente.
Es que es una pasada.
Elimina por completo la necesidad de leerse la
documentación de cada maldita IA nueva que sale
al mercado.
Tal cual.
Y claro, una vez entendido que ambas plataformas
son este traductor mágico, la pregunta es obligada.
¿En qué se diferencian?
Pues sí, porque si las dos hacen de
puente, a priori daría igual cuál elegir, ¿verdad?
Claro, pero sabemos que no es así ni
de lejos.
Ni de lejos.
Así que vamos a sumergirnos en la primera
contendiente de esta batalla.
Que es Open Router.
Por lo que cuenta el análisis, su filosofía
es cristalina.
Es el modelo Buffet Libre.
Sí, un Buffet Libre con un minimalismo extremo.
O sea, estamos hablando de acceso masivo a
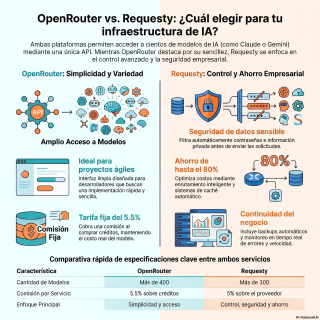
más de 400 modelos de IA diferentes.
400 se dice pronto, ¿eh?
Es una barbaridad.
Cubren desde los gigantes comerciales hasta modelos experimentales
en Hugging Face.
Pero fíjate que su verdadera identidad no es
solo el volumen, sino que han eliminado cualquier
fricción de entrada.
Ya, o sea que te registras y listo.
Exacto.
Te registras, generas tu clave API y en
dos minutos estás mandando peticiones.
Cero burocracia, cero configuraciones raras.
Oye, y hay un detalle en la estructura
de costes que me ha llamado muchísimo la
atención.
Porque rompe un poco con lo que solemos
ver en el software, ¿no?
Sí, lo del markup transaccional.
Eso es.
Te cobran una comisión del 5 ,5%.
Pero solo al recargar el saldo con la
tarjeta.
Luego, cuando ya tienes el dinero en la
cuenta, el coste por token, o sea, cada
palabra generada, es exactamente el mismo que si
fueras directo al proveedor.
Claro.
Te pasan la factura limpia, sin márgenes ocultos
por el uso continuo.
Y eso refleja al 100 % su mentalidad.
No quieren ser tu socio estratégico.
Quieren ser una tubería, súper rápida y sin
estorbos.
Una tubería directa, sí.
Y por eso gustan tanto a desarrolladores independientes,
startups.
Cuando tu objetivo es iterar rápido o probar
20 modelos en una tarde para ver cuál
funciona, no quieres capas de software molestando en
medio.
Claro.
Pero, a ver, entonces, ¿qué significa todo esto?
Si es tan simple y transparente, ¿no corremos
el riesgo de ir a pelo y sin
red de seguridad si el proyecto crece?
Bueno, es que ese es exactamente el punto.
Porque imagínate que la app se hace viral
de golpe, o que un banco decide usarla.
Si van directos, ¿qué pasa con los límites
de uso o la privacidad?
Pues pasa que esa falta de red de
seguridad es una característica de diseño de open
router, no un fallo.
O sea, la responsabilidad recae íntegramente en quien
desarrolla.
Ostras, claro.
Te lo tienes que montar tú.
Exacto.
Si necesitas limitar peticiones para no arruinarte o
filtrar contraseñas, tu equipo tiene que programar todo
eso desde cero en sus propios servidores.
Ya, y claro, aquí es donde la cosa
se pone muy interesante.
Porque a medida que un proyecto escala, la
velocidad de la red de seguridad se desvanece.
La red de seguridad pura ya no es
lo único que importa.
Entran los de legal, los de finanzas… Y
te cambian la conversación entera, claro.
Por completo.
Ya no se habla de probar modelos, sino
de mitigar riesgos.
Y esto nos lleva de lleno al enfoque
radicalmente opuesto de Requesty.
O sea, si open router es un coche
de carrera súper ligero, Requesty sería como contratar
a un asesor financiero y un guardaespaldas a
la vez.
Sí, sí.
Si conectamos esto con el panorama general, la
comparación del blindaje… Es buenísima.
Requesty sacrifica un poco esa ligereza para añadir
características de grado empresarial.
Puras y duras.
Que a nivel de catálogo tampoco andan cojos,
¿eh?
Que tienen más de 300 modelos.
Cierto.
Es una oferta inmensa.
Pero su obsesión es el control del flujo
de datos.
De hecho, el material de Tobitiches destaca muchísimo
sus guardias de seguridad integrados.
Y esto me flipa arquitectónicamente.
Dicen que son filtros activos.
A ver, imagínate una app de atención, y
un usuario despistado pone Hola, mi tarjeta es
esta, cobradme.
Un clásico que da terror a cualquier empresa.
Claro, porque si vas con conexión directa, ese
número de tarjeta viaja por Internet, entra en
un servidor de terceros y se queda en
sus logs.
Una pesadilla para la protección de datos.
Totalmente ilegal en muchos contextos, además.
Pero Requesty intercepta el mensaje.
La duda que me surge es ¿cómo hacen
esto en tiempo real sin añadir un lag
espantoso?
Porque, si la IA tarda 10 segundos por
culpa del filtro, el usuario se marcha.
Bueno, la clave está en el Let's Computing
y en expresiones regulares muy, muy optimizadas.
O sea, no mandan el texto a otra
IA gigantesca para que lo lea, sino que
usan patrones de reconocimiento ultra rápidos para cazar
cosas sensibles.
Ah, vale.
O sea, buscan la forma de una tarjeta,
un email, ese tipo de patrones.
Exacto.
Al detectar esa información personal identificable, la bloqueen
o la enmascaran en milisegundos.
Para empresas sujetas al RGPD en Europa, esto
te ahorra meses de auditorías.
Ya lo tienes en la infraestructura.
Madre mía, es que eso vale oro.
Y luego está la seguridad operativa, lo de
los failovers o copias de seguridad automáticas.
Uy, sí, eso es vital en producción.
A ver si lo he entendido bien.
Estás usando GPT -4.
OpenAI se cae a nivel mundial.
¿Qué pasa?
Y Requesty detecta el error 500 y te
manda la petición a Cloud automáticamente para que
tu app no muera.
Eso es.
¿Te salva la vida?
Pero espérate, porque aquí veo un problema.
Si pasas de OpenAI a Cloud en milisegundos,
la IA cambia de personalidad, ¿no?
De repente el usuario nota que el tono
es distinto o el formato cambia.
¿No es un riesgo enorme?
Oye, pues es una deducción buenísima.
Y sí, es un riesgo, especialmente si dependes
de salidas JSON super estrictas.
Pero seamos realistas.
En operaciones a gran escala, entregar una respuesta
un poco diferente es infinitamente mejor que sacar
una pantalla de un dispositivo.
Y no es una idea de error durante
dos horas.
Ya, visto así, la pantalla en blanco es
el mayor de los males.
Claro.
Y además, los desarrolladores pueden configurar esos failovers
para saltar a modelos de la misma familia.
Por ejemplo, de un modelo grande a uno
más pequeño del mismo creador para minimizar ese
choque de personalidad.
Te garantizan el uptime del 99 ,9%.
Vale, vale, me convence.
Pero claro, todo esto suena a magia corporativa.
Y la magia hay que pagarla.
Y aquí es donde quiero apretar un poco.
Venga.
Vale, dicen que ahorras un 80%, pero de
entrada te están cobrando un 5 % extra
por cada uso.
O sea, un peaje continuo.
¿Realmente compensa este peaje si no eres una
megacorporación?
Pues mira, esta aparente contradicción es lo mejor
de Requesty.
Y para entenderlo, hay que saber cómo se
quema realmente el dinero en la IA generativa.
Si Requesty fuera solo un tubo pasivo, ese
5 % extra sería una ruina.
Claro, estaría esperando perdiendo dinero a expuertas.
Exacto, pero lo compensan con inteligencia financiera automatizada.
Concretamente, con dos cosas.
El enrutamiento inteligente y el almacenamiento en caché
semántica.
A ver, pausa aquí.
Lo de la caché.
En software normal, si un millón de personas
piden la misma foto, el servidor la guarda
y la enseña sin volver a calcularla, ¿no?
Exacto.
Sí, una caché de libro.
Pero en inteligencia artificial se supone que cada
pregunta es única.
Si yo digo, ¿cómo devuelvo estos zapatos que
me aprietan?
Y otro dice, ¿cuál es la política de
devoluciones?
Las frases son súper distintas.
¿Cómo demonios cacheas algo que no es texto
idéntico?
¡Ostras!
Es que ese es el gran cambio de
paradigma del que estamos hablando.
Pasamos de IA generativa a casi, no sé,
IA reciclada.
Requesty usa una caché semántica, no de texto
exacto.
Vale, ¿y eso cómo se come?
Pues cogen modelos muy pequeños que convierten la
pregunta en vectores matemáticos.
Básicamente extraen la intención.
Si los vectores de los zapatos que aprietan
y la política general de devoluciones son idénticos
en significado, el sistema sabe que la respuesta
es la misma.
¡Ostras!
Claro.
Así que en lugar de despertar al modele
principal, que te cuesta pasta por palabra, requesty
saca la respuesta guardada y te la da
gratis y al instante.
¡Guau!
Visto así, claro, los números cambian por completo.
Si el 40 % de tus usuarios hacen
variaciones de las mismas 5 preguntas, casi la
mitad de tus peticiones te salen a coste
cero.
Literalmente.
Dejas de quemar billetes repitiendo procesos cognitivos que
la IA ya solucionó ayer por la tarde.
El sobrecoste del 5 % se amortiza rapidísimo.
Es alucinante.
Y mencionabas también el enrutamiento inteligente.
Sí, ese es el segundo mecanismo.
Puedes poner reglas de negocio complejas sin tocar
tu código.
Imagina que tienes un presupuesto cerrado para un
modelo superprimium.
Vale.
Si llegas al 90 % del presupuesto, a
mediados de mes, Requesty automáticamente manda las consultas
fáciles a un modelo de código abierto baratísimo
y reserva el premium solo para tareas supercomplejas.
Madre mía, claro.
Es que cambia la perspectiva.
Ya no es un peaje.
Es como tener suprotratado a un departamento entero
de finanzas y seguridad por una miseria.
Tal cual.
¿Te optimizan todos sin que tú tengas que
hacer nada?
Pues creo que con este nivel de detalle
la radiografía está clarísima.
Tenemos los dos conectores diseccionados.
Así que, para quien nos esté escuchando y
mañana tenga que decidir la arquitectura de su
próximo sistema, ¿cómo resumirías el veredicto definitivo?
Pues mira, ciñéndonos al análisis.
Todo se reduce a la tolerancia al riesgo
frente a la necesidad de control.
Si lo que priorizas es la simplicidad radical,
explorar cientos de modelos sin estorbos y construir
rápido, OpenRouter es tu ganador indiscutible.
Es el lienzo en blanco perfecto.
La filosofía del circuito cerrado, no.
Pura velocidad y cero peso extra.
Exacto.
Pero, si el entorno te exige garantías, si
no te puedes permitir caídas de servidores, si
tienes obligación legal de bloquear fuga de datos
y si tu volumen pide automatizar ahorros con
cachers semánticas, entonces requesties la opción imperativa.
Lo ideal, como siempre recomiendan, es hacerse cuentas
de prueba y cacharrear con las dos.
Me parece una conclusión súper práctica.
El que quiera el viento en la cara
probando cosas, tiene una.
Y el que necesite cruzar un campo de
minos corporativos sin gastar de más, tiene la
otra.
El análisis lo deja súper claro.
Pero, ¿sabes?
Esto plantea una pregunta importante.
Una reflexión de fondo para la audiencia.
A ver, dispara.
Hemos visto que cambiar de GPT a Cloud
o Gemini es ahora tan trivial como enchufar
un cable USB.
Y si el acceso es tan intercambiable, nos
estamos acercando al punto en el que el
modelo de IA en sí se vuelve un
producto generalizado.
O sea, una simple commodity.
Qué buena pregunta.
Claro, y si el verdadero valor en el
futuro no es la IA que uses, sino
la infraestructura inteligente, el enrutamiento y la seguridad
que envuelven a esos modelos.
Uf, es un planteamiento que le da la
vuelta a todo a la verdad.
Llevamos años obsesionados con la marca del agua
que sale por el grifo, debatiendo si esta
es mejor que la otra, y resulta que
la verdadera revolución está en las tuberías inteligentes
que deciden por dónde y a qué precio
fluye esa agua.
Menuda idea monumental para dejarla macerando.
Antes de despedirnos hasta el próximo programa, os
informamos de que las voces que oyes han
sido generadas por la IA de Notebook LM
y que dirigiendo el podcast se encuentra Julio
Pablo Vázquez, un humano que te envía saludos.
En caso de error, probablemente sean errores humanos.
Nos escuchamos.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIM Praxis.
Nos escuchamos.
En el próximo episodio.