Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:09
0:15
0:20
0:23
0:26
0:28
0:29
0:40
0:41
0:45
0:48
0:50
0:51
0:53
0:55
0:58
1:01
1:02
1:03
1:05
1:06
1:08
1:09
1:11
1:12
1:15
1:17
1:18
1:20
1:22
1:24
1:26
1:29
1:32
1:33
1:36
1:38
1:40
1:41
1:42
1:47
1:50
1:53
1:53
1:56
1:59
2:02
2:05
2:06
2:06
2:09
2:11
2:15
2:15
2:15
2:19
2:23
2:25
2:29
2:32
2:33
2:34
2:34
2:37
2:40
2:41
2:43
2:47
2:49
2:51
2:52
2:54
2:57
2:58
2:59
3:00
3:01
3:03
3:05
3:07
3:10
3:11
3:15
3:17
3:19
3:21
3:24
3:26
3:28
3:30
3:32
3:33
3:36
3:38
3:41
3:42
3:45
3:48
3:54
3:56
3:59
4:02
4:03
4:05
4:06
4:08
4:09
4:11
4:13
4:15
4:16
4:17
4:20
4:22
4:26
4:26
4:29
4:30
4:32
4:33
4:34
4:35
4:38
4:39
4:42
4:43
4:45
4:50
4:52
4:53
4:56
4:59
5:01
5:04
5:06
5:07
5:09
5:09
5:11
5:14
5:15
5:18
5:19
5:21
5:24
5:24
5:27
5:28
5:30
5:31
5:32
5:34
5:35
5:36
5:39
5:41
5:42
5:44
5:45
5:47
5:49
5:52
5:54
5:57
5:58
6:01
6:03
6:06
6:07
6:09
6:12
6:15
6:17
6:18
6:19
6:20
6:21
6:23
6:26
6:29
6:30
6:30
6:33
6:35
6:35
6:36
6:38
6:39
6:41
6:42
6:45
6:45
6:47
6:51
6:53
6:54
6:57
6:59
7:02
7:03
7:04
7:05
7:09
7:11
7:12
7:13
7:16
7:19
7:21
7:23
7:24
7:26
7:28
7:29
7:33
7:34
7:34
7:37
7:37
7:39
7:41
7:44
7:45
7:47
7:50
7:51
7:55
7:58
8:00
8:02
8:03
8:05
8:08
8:10
8:13
8:16
8:18
8:20
8:21
8:24
8:28
8:29
8:32
8:34
8:37
8:38
8:39
8:41
8:43
8:45
8:48
8:50
8:52
8:55
8:56
8:57
9:00
9:04
9:05
9:09
9:11
9:15
9:18
9:20
9:21
9:21
9:24
9:25
9:29
9:29
9:33
9:35
9:37
9:41
9:42
9:45
9:46
9:47
9:48
9:49
9:52
9:55
9:56
9:57
9:59
10:02
10:06
10:09
10:11
10:13
10:15
10:16
10:17
10:20
10:21
10:25
10:25
10:27
10:28
10:31
10:32
10:34
10:37
10:38
10:40
10:41
10:44
10:45
10:46
10:48
10:51
10:51
10:52
10:55
10:58
11:00
11:02
11:05
11:05
11:07
11:09
11:10
11:13
11:14
11:17
11:17
11:19
11:21
11:24
11:26
11:28
11:32
11:34
11:35
11:37
11:38
11:41
11:43
11:45
11:45
11:48
11:49
11:51
11:55
11:57
11:57
12:01
12:03
12:05
12:07
12:08
12:10
12:11
12:13
12:15
12:16
12:19
12:21
12:24
12:25
12:27
12:29
12:31
12:34
12:35
12:39
12:42
12:43
12:46
12:48
12:50
12:52
12:55
12:57
12:59
13:04
13:05
13:07
13:09
13:11
13:13
13:15
13:16
13:18
13:21
13:21
13:23
13:26
13:28
13:31
13:33
13:35
13:37
13:38
13:41
13:41
13:42
13:45
13:48
13:53
13:55
13:57
14:01
14:03
14:04
14:04
14:06
14:06
14:08
14:11
14:12
14:14
14:17
14:20
14:23
14:25
14:26
14:28
14:31
14:33
14:34
14:35
14:37
14:39
14:41
14:42
14:45
14:46
14:48
14:51
14:52
14:54
14:55
14:57
14:59
15:02
15:05
15:07
15:09
15:10
15:13
15:17
15:18
15:19
15:20
15:22
15:25
15:30
15:30
15:31
15:33
15:33
15:36
15:39
15:41
15:42
15:43
15:45
15:49
15:51
15:53
15:54
15:57
15:59
16:00
16:02
16:05
16:06
16:09
16:12
16:14
16:15
16:18
16:20
16:24
16:27
16:32
16:33
16:35
16:37
16:40
16:43
16:46
16:48
16:51
16:54
16:58
17:01
17:03
17:06
17:07
17:08
17:11
17:12
17:13
17:15
17:17
17:17
17:20
17:22
17:23
17:25
17:26
17:29
17:32
17:34
17:38
17:40
17:44
17:48
17:50
17:52
17:52
17:55
17:57
17:59
18:03
18:03
18:05
18:06
18:07
18:10
18:12
18:16
18:17
18:20
18:21
18:22
18:24
18:28
18:30
18:31
18:32
18:35
18:38
18:38
18:40
18:42
18:45
18:47
18:50
18:50
18:53
18:56
18:56
18:59
19:00
19:01
19:04
19:05
19:08
19:09
19:12
19:12
19:14
19:14
19:16
19:18
19:20
19:21
19:24
19:26
19:30
19:31
19:33
19:33
19:36
19:39
19:39
19:40
19:43
19:45
19:46
19:48
19:51
19:51
19:53
19:57
20:00
20:02
20:04
20:07
20:09
20:10
20:11
20:12
20:14
20:16
20:19
20:19
20:20
20:22
20:22
20:25
20:28
20:29
20:32
20:35
20:36
20:37
20:38
20:41
20:44
20:46
20:48
20:50
20:52
20:55
20:56
20:57
20:59
21:02
21:04
21:06
21:08
21:09
21:12
21:14
21:15
21:17
21:19
21:20
21:22
21:23
21:27
21:29
21:31
21:32
21:34
21:36
21:39
21:42
21:43
21:43
21:45
21:47
21:48
21:51
21:51
21:52
21:53
21:56
21:57
22:00
22:01
22:03
22:06
22:08
22:09
22:11
22:13
22:16
22:16
22:17
22:20
22:21
22:21
22:24
22:26
22:28
22:28
22:29
22:31
22:34
22:38
22:41
22:43
22:44
22:47
22:47
22:48
22:51
22:51
22:51
22:52
22:53
22:54
22:57
22:58
22:59
23:01
23:02
23:03
23:06
23:08
23:11
23:12
23:14
23:16
23:19
23:21
23:23
23:26
23:29
23:30
23:31
23:31
23:36
23:40
23:40
23:43
23:46
23:49
23:50
23:50
23:51
23:54
23:56
23:58
23:59
24:00
24:03
24:05
24:08
24:11
24:13
24:16
24:18
24:20
24:20
24:22
24:23
24:25
24:28
24:33
24:35
24:39
24:40
24:40
24:43
24:47
24:48
24:50
24:50
24:53
24:56
24:57
24:58
25:01
25:02
25:05
25:06
25:09
25:11
25:14
25:17
25:20
25:23
25:25
25:26
25:29
25:32
25:36
25:38
25:41
25:42
25:45
25:47
25:50
25:50
25:53
25:55
25:56
25:58
25:59
26:02
26:04
26:07
26:09
26:10
26:12
26:15
26:18
26:20
26:21
26:24
26:26
26:30
26:33
26:37
26:40
26:41
26:41
26:45
26:49
26:51
26:54
26:57
27:01
27:03
27:06
27:08
27:10
27:14
27:18
27:18
27:22
27:24
27:26
27:29
27:31
27:34
27:36
27:38
27:42
27:54
27:56
28:07
28:09
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas, bienvenidas, bienvenidos a un nuevo episodio
de BIMPRAXIS.
Hoy os traemos cómo afinar tu propia inteligencia
artificial en casa con un Sloth Studio y
una tarjeta gráfica comercial.
Hola, ¿qué tal?
A ver, fíjate en esto.
Hasta hace nada, un par de años como
mucho, si alguien quería alterar el código fundamental
de una inteligencia artificial, la imagen mental era
inevitable, ¿no?
Totalmente.
Necesitabas, o sea, el presupuesto de un país
pequeño.
Sí, sí, y un centro de datos enorme
en Islandia o algo así.
Exacto, un centro de datos en Islandia.
Un centro de datos en Islandia refrigerado bajo
cero y un equipo de 50 ingenieros escribiendo
un código incomprensible.
Una locura, vamos.
Pero la realidad de hoy, y esto es
lo que vamos a desgranar en este análisis,
es otra completamente distinta.
Resulta que el ordenador que mucha gente tiene
en su salón, pues para jugar a videojuegos,
tiene ahora mismo la potencia suficiente para reescribir
la mente de un modelo de lenguaje.
Y ojo, en exactamente un minuto.
Eso es, en un minuto.
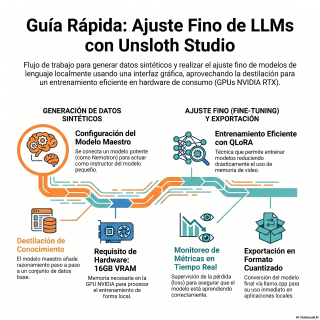
Por eso hoy tenemos sobre la mesa un
material súper interesante.
Un material que desglosa cómo una serie de
herramientas gratuitas están democratizando este proceso por completo.
Concretamente usando el proyecto de código abierto Ansloth
y, bueno, su nueva interfaz visual, el Ansloth
Studio.
Es que es un cambio de paradigma monumental.
O sea, si conectamos esto con la perspectiva
general, lo que este material nos está mostrando
no es sólo una nueva herramienta de software,
sin más.
Ya.
Es literalmente el colapso de la mayor barrera
de entrada que existía en el desarrollo.
La barrera del hardware y de la complejidad,
¿verdad?
Tal cual.
La complejidad técnica y el altísimo coste computacional.
Porque, históricamente, los usuarios de a pie éramos
meros consumidores.
Consumidores de modelos que empresas gigantes habían entrenado
por nosotros con esos presupuestos millonarios.
Te daban la caja negra y tú a
usarla.
Exactamente.
Pero lo que Ansloth plantea con este nuevo
flujo de trabajo es, fíjate, darnos las llaves
del taller.
Ya no ejecutamos modelos estáticos.
Ahora los modificamos y les enseñamos comportamientos nuevos
de forma local, en nuestra propia casa.
A ver, vamos a desgranar esto porque el
salto me parece enorme.
Para quienes ya siguen el tema, el proyecto
Ansloth ya era muy respetado en la comunidad
de código abierto, ¿no?
Sí, muchísimo.
Porque era súper eficiente a la hora de
procesar IA.
Pero la pieza clava que analizan las fuentes
de hoy es un Sloth Studio.
Eso es, la versión estudio.
Y la gran revolución, por lo que entiendo,
no es que añadan más algoritmos.
Matemáticos hipercomplejos y ocultos, sino que aporta una
capa visual, una interfaz gráfica.
Sí, es como si nos dijeran que ya
no hace falta alquilar un laboratorio corporativo para
experimentar, sino que podemos montar, no sé, un
reactor de IA en el ordenador que usamos
para jugar y encima sin tener que picar
líneas y líneas de código en una terminal
oscura, que es lo que echaba para atrás
a mucha gente.
Hombre, claro, es que la terminal impone y
lo más impactante de este análisis es que
exige unos requisitos de hardware que a ver.
Ya están en muchísimos ovares.
Sí, las famosas tarjetas gráficas comerciales.
Claro, se menciona que todo este flujo funciona
sobre tarjetas gráficas GeForce RTX de consumo.
El único requisito fuerte que señalan las fuentes
es tener al menos 16 GB de memoria
VRAM, memoria de vídeo, para afilar un modelo
pequeño.
Que a ver, 16 GB de VRAM es
una cifra crítica.
Sí, es la frontera.
Porque hacen no tanto tiempo hablar de esa
cantidad de memoria de vídeo determinada.
Lo que era dedicada era terreno exclusivo de
estaciones de trabajo profesionales.
De servidores, prácticamente.
Exacto.
Pero hoy en día es una especificación estándar
en la gama media -alta que usan diseñadores
gráficos, editores de vídeo o los aficionados al
gaming.
El hardware ya está distribuido, está en millones
de casas.
El cuello de botella era el conocimiento para
aprovechar ese hardware.
Tal cual.
Y eso es exactamente lo que viene a
resolver esta nueva generación de interfaces visuales como
Unslot Studio.
Pero claro, aquí es donde se pone realmente
interesante la cosa.
Una vez que tenemos la máquina y el
programa instalados, la pregunta es ¿qué construimos exactamente?
Porque el análisis de hoy nos propone un
objetivo súper concreto.
Tomar un modelo de lenguaje pequeñito, que por
defecto te da respuestas cortas, directas, un poco
telegráficas, y transformarlo en uno que posea un
razonamiento analítico profundo.
Que explique sus motivos paso a paso.
Exacto.
Y para lograr esto, el material de hoy
es un modelo de lenguaje pequeño.
Y detalla un concepto que me parece fascinante.
El flujo de trabajo de destilación, o Distillation
Workflow.
Ahí es que la destilación de conocimientos es
uno de los conceptos más elegantes que hay
en el aprendizaje automático actual.
A ver, explícanos cómo funciona esto de la
destilación.
Pues mira, en este escenario tenemos básicamente dos
entidades.
Por un lado, tenemos al modelo alumno.
El aprendiz.
Exacto.
Que en este caso práctico es el modelo
llamado Dos Instruct.
Vale.
Es un modelo ligero, rápido.
Ideal para ejecutarse en casa sin que el
ordenador salga ardiendo.
Pero como bien decías, es un modelo que
va directo al grano.
Te da la respuesta y ya está, sin
mostrar su proceso mental.
Y por otro lado, tenemos al modelo profesor.
Que este es el modelo gordo, ¿no?
Claro, es un modelo mucho más complejo, grande
y capaz.
En el documento realizado mencionan el Nemotron 3
Nano de NVIDIA, que se caracteriza precisamente por
tener una gran capacidad de razonamiento lógico.
Vale, entiendo.
Entonces, el objetivo del proceso de destilación...
...de destilación es, en esencia, transferir esa metodología
de pensamiento rigurosa del profesor al alumno.
Y aquí, oye, me surge una duda absolutamente
pragmática.
Porque seguro que más de uno lo está
pensando.
A ver, dispara.
Si ya tenemos un modelo grande, este profesor
que comentas, que es buenísimo, que es súper
inteligente y que ya sabe razonar paso a
paso de forma natural.
Sí.
Pues, a ver, ¿por qué no usamos simplemente
ese modelo grande y nos ahorramos todo el
trabajo?
Claro.
O sea, ¿por qué tomarnos la tremenda molestia?
Desesperación.
Sentar a un modelo gigante a enseñarle trucos
a uno pequeño.
Parece que estamos dando un rodeo innecesario, la
verdad.
Es la pregunta fundamental del millón.
Y la respuesta, en una palabra, es eficiencia.
Eficiencia operativa.
Vale.
Un modelo grande, como nuestro profesor Nemotron, es
brillante, ¿de acuerdo?
Pero computacionalmente es obeso.
Obeso.
Me gusta la palabra.
Es que lo es.
Consume una cantidad masiva de recursos, de energía...
De energía y de memoria, simplemente para generar
una sola palabra.
Claro.
Si intentamos usar ese modelo gigantesco de forma
constante para las tareas cotidianas en un equipo
local, el sistema colapsaría.
O, en el mejor de los casos, sería
desesperantemente lento.
Te puedes ir a tomar un café entre
pregunta y pregunta.
Tal cual.
Sin embargo, si usamos ese modelo grande una
sola vez...
Solo una vez.
Para generar ejemplos perfectos de razonamiento.
Ah, vale, vale.
Y luego, destilarlo.
Si usamos ese estilo, esa forma de pensar
en el modelo pequeño, la ecuación cambia por
completo.
Porque obtenemos un alumno que imita esa calidad
de razonamiento, pero manteniendo su arquitectura súper ligera.
Exactamente.
Conseguimos respuestas profundas a una velocidad vertiginosa y
consumiendo poquísima energía en nuestro día a día.
Es una inversión inicial a cambio de un
rendimiento sostenido espectacular.
Vale.
Ahora entiendo el esquema perfectamente.
Básicamente, usamos al erudito para que escriba unos
apuntes perfectos.
Y luego, el estudiante avispado se aprende la
estructura de sus apuntes para poder aplicarla rapidísimo
en los exámenes, sin tener que cargar con
toda la enciclopedia en la mochila.
Esa analogía es perfecta.
Pero claro, para que el estudiante aprenda, necesitamos
fabricar ese libro de texto primero, esos apuntes.
Y el material nos lleva a una fase
que llaman creación de datos sintéticos, que es
donde se cocina todo esto.
La pestaña de recetas o recipes en Anxiloth
Studio.
Exacto.
Porque olvidándonos un poco de los botones y
los menús, lo que realmente se hace aquí
es diseñar una cadena de montaje de información.
Una tubería de datos, un pipeline.
Todo empieza con unos cimientos sólidos.
El usuario no parte de cero.
Menos mal, porque inventarse mil preguntas con sus
respuestas tiene tela.
Ya te digo.
El proceso parte de un conjunto de datos
que ya existe, llamado Anxiloth Alpaca Clean.
Alpaca Clean.
Sí, que es un estándar en la industria.
Está alojado en la plataforma Hugging Face y
contiene, pues, miles de ejemplos de instrucciones típicas
de usuarios y sus correspondientes respuestas.
El formato clásico de pregunta y respuesta de
toda la vida.
Eso es.
Pero claro, el análisis nos advierte de un
problema.
Esas respuestas del Alpaca Clean son cortas, son
directas.
Y nosotros, precisamente, queremos enseñar a argumentar.
Claro, no nos sirven tal cual.
Entonces, lo que nos explican es que se
coge ese conjunto de datos… …y se toma
una decisión bastante radical.
Se elimina por completo la columna de las
respuestas originales.
Se borran.
De cuajo.
Así, sin más.
Y en ese hueco que queda libre, conectan
al modelo profesor para que él redacte las
respuestas nuevas.
Exactamente.
Y para que esa conexión funcione y sea
automática, el flujo de trabajo utiliza lo que
se llaman plantillas Jinja, J -I -N -J
-A, que actúan como el tejido… …el tejido
conectivo de todo este tinglado.
A ver, explícanos un poco qué es esto
de Jinja, porque suena a magia negra de
programación.
Qué va, qué va.
Las plantillas Jinja son cruciales aquí, pero no
son ninguna caja negra.
Son simplemente un motor de plantillas de texto.
¿Vale?
O sea, rellenar huecos.
Exacto.
Lo que hacen es tomar variables dinámicas de
una base de datos.
Por ejemplo, en nuestro caso, la pregunta original
del usuario que sacamos del conjunto Alpaca.
Sí.
Y la inserta… …están dentro de una estructura
de texto predefinida.
Un prompt gigante que se envía automáticamente al
modelo profesor.
Ah, vale.
O sea que el sistema no tiene que
estar escribiendo manualmente las mil consultas una por
una.
Claro que no.
Las genera programáticamente gracias a la plantilla.
Profesor, para que rellene los huecos, hay un
detalle técnico en las fuentes que me parece
la clave de bóveda de todo este asunto.
El modo pensamiento.
Exacto.
El Thinking Mode.
No le piden simplemente al profesor que responda
a la pregunta.
Van a la configuración y le activan este
parámetro específico.
Y le dan muchísimo margen, sí.
Sí.
Le dan un límite de más de 2
.000 tokens, que es un montón de texto,
para que tenga espacio para explayarse a gusto.
Es que ese modo pensamiento es el núcleo
absoluto de la destilación.
Al activarlo, estamos forzando al modelo profesor a
que, por favor, no entregue la solución de
forma inmediata.
¿Le cortamos el atajo?
Le obligas a generar lo que en el
mundillo se conoce como una traza de razonamiento,
o Reasoning Trace.
Que es como pensar en voz alta.
Exacto.
El modelo tiene que imprimir en texto todo
su proceso deductivo.
O sea, qué variables está considerando en el
problema, qué posibles soluciones existen… ¿Por qué descarta
una opción y se queda con otra?
Eso es.
Esa disección paso a paso es el verdadero
conocimiento de oro puro que queremos que el
modelo alumno absorba.
Pero, a ver… Espera un momento.
Dime.
Tengo que hacer un poco de abogado del
diablo en este punto.
Porque al leer las fuentes, esto me plantea
una paradoja tremenda.
A ver, ¿de ese te ha ocurrido?
Estamos usando una inteligencia artificial para que se
invente el material de estudio que luego va
a utilizar otra inteligencia artificial para aprender.
Sí, datos sintéticos.
¿Pero no corremos el riesgo de crear una
cámara de eco absoluta?
O sea, si el modelo profesor alucina un
dato o tiene una lógica defectuosa en algún
tema concreto… Ajá.
…el modelo alumno… …va a asimilar ese error
como una verdad absoluta y lo va a
replicar.
No estamos retroalimentando los fallos del propio sistema
y haciéndolos más grandes.
A ver, es una objeción súper válida, ¿eh?
De hecho, es un debate central ahora mismo
en toda la investigación sobre datos sintéticos.
Es que suena un poco a teléfonos cacharrado.
Lo sé, pero hay que entender con muchísima
precisión qué estamos extrayendo exactamente del modelo profesor,
en este flujo en concreto.
Vale.
Fíjate que no le estamos pidiendo que invente
hechos históricos ni que descubra nuevas leyes de
la física partiendo de cero, ¿eh?
Ya, le damos la pregunta a nosotros.
Exacto.
Estamos usando un conjunto de datos base, el
alpaca clean, que ya contiene la premisa inicial
real.
Lo que le pedimos al modelo profesor no
es que invente datos… Sino que… …mino hacia
una respuesta fundamentada.
O sea, estamos destilando la estructura del pensamiento
analítico, la sintaxis de la lógica.
No estamos inventando verdades nuevas.
Ah, vale.
O sea, ¿le estamos enseñando a justificar?
¿No le estamos dando una enciclopedia nueva?
Tal cual.
Piénsalo así.
Si tuviéramos que parar a expertos humanos para
que redactaran a mano mil trazas de razonamiento
superdetalladas, paso por paso… Madre mía, tardaríamos meses.
Meses, y costaría una fortuna.
Pero el modelo grande lo hace en minutos,
estructurando la lógica de una forma superconsistente.
Visto así, la verdad es que tiene todo
el sentido del mundo.
Bien.
Pues una vez que el sistema termina de
procesar la lógica de una forma superconsistente… …y
comenzamos a procesar todo esto en la pestaña
de recetas, nos encontramos con mil ejemplos sintéticos
perfectos.
Mil pares de instrucción y razonamiento.
Mil problemas donde se muestra la pregunta, todo
el razonamiento interno entre unas etiquetas especiales de
pensamiento y la conclusión final.
Ya tenemos los apuntes listos.
Tenemos los apuntes.
Pero ahora viene el reto físico.
¿Cómo embutimos toda esta información gigantesca en el
cerebro de un modelo de lenguaje que ya
de por sí pesa gigabytes?
Ajá.
¿Y todo esto utilizando únicamente la memoria de
la tarjeta gráfica del ordenador de casa que
decíamos que eran 16 gigas?
Pues aquí es donde la ingeniería de software
brilla con luz propia, de verdad.
¿Por qué no explota la tarjeta?
No, no explota gracias a una técnica de
entrenamiento maravillosa llamada Q -Lora.
Q -Lora.
Con Q y luego Lora.
Eso es.
A ver, si tuviéramos que reescribir todos los
pesos neuronales del modelo base, o sea, los
miles de millones de parámetros matemáticos que lo
componen, para enseñarle esto nuevo… …necesitaríamos… …necesitaríamos el
centro de datos de Islandia que decíamos al
principio.
Exactamente.
Necesitaríamos granjas enteras de servidores.
Pero Q -Lora evita esto por completo.
¿Cómo lo hace?
Las fuentes lo explican muy bien.
Sí.
La parte Lora, que son unas siglas en
inglés para adaptación de bajo rango… Sí.
…consiste básicamente en congelar el cerebro original del
modelo.
No lo tocamos.
Se queda de solo lectura.
Eso es.
Y en su lugar, le añadimos unas pequeñas
matrices matemáticas externas.
Oye, me encantó la analogía que hacían al
explicar esto.
Es como si en lugar de tener que
reimprimir un libro entero en la imprenta para
corregir un concepto o añadir un capítulo… Exacto.
…simplemente cogemos el libro original y le vamos
pegando unas notas adhesivas en los márgenes con
la información nueva.
Es la mejor analogía posible.
Las notas adhesivas son el Lora.
Pero espera.
La letra Q de Q -Lora.
Añade otra capa más a este asunto, ¿verdad?
Sí.
Añade la capa de la compresión extrema.
Porque no solo estamos usando esas notas adhesivas
para no estropear el libro original.
Claro.
La Q representa la cuantización.
Siguiendo con tu analogía del libro.
No solo usamos notas adhesivas para ahorrar papel
y tinta, sino que además, en esas notas,
escribimos utilizando una taquigrafía matemática ultracomprimida.
Ah, vale.
O sea, letra súper pequeñita.
Matemáticamente hablando, sí.
Reducimos la precisión numérica de la información.
Pasamos de usar números grandísimos de coma flotante
de 16 bits a formatos mucho más pequeños,
como de 4 bits.
Y eso reduce drásticamente el espacio que ocupan.
Reduce muchísimo la memoria VRAM necesaria.
Esta combinación de no tocar el modelo original
y, encima, comprimir a lo bestia las actualizaciones,
es lo que permite que todo el proceso
encaje mágicamente en esos 16 gigas de una
gráfica doméstica.
Es flipante.
Y esto nos lleva directamente a la pestaña
donde ocurre la magia.
La pestaña estudio.
Y a la configuración del entrenamiento en sí.
Los famosos hiperparámetros.
Sí.
El documento detalla unos valores muy específicos que
en la interfaz visual son botoncitos, pero que
si no se explican, la verdad es que
suenan a jerga incomprensible.
Totalmente.
Por ejemplo, configuran un parámetro que se llama
LoRaAlpha, y le ponen un valor de 32.
A ver, entendiendo que LoRa son esas notas
adhesivas de aprendizaje que decíamos, ¿qué función cumple
exactamente ese valor alfa de 32?
Pues mira, el parámetro LoRaAlpha actúa en términos
prácticos como un control de volumen, o un
factor de escala para el conocimiento nuevo.
Un control de volumen.
Sí.
A ver, si tú le pones un alfa
muy bajito, el modelo le va a hacer
muy poco caso a las notas adhesivas.
Va a seguir comportándose mayoritariamente como lo hacía
antes.
Como si la nota estuviera escrita muy flojito
y casi no la lee.
Exacto.
Pero al establecerlo en 32, que suele ser
el doble del rango habitual que se configura
en estas matrices matemáticas, Le estamos gritando, básicamente.
le estamos diciendo al modelo que le dé
una importancia supersignificativa a este nuevo estilo de
razonamiento.
Ah, claro.
Estamos forzando que la nueva estructura lógica tenga
un peso dominante sobre sus respuestas impulsivas originales,
para que no vaya directo al grano, que
es su instinto.
Entendido.
Y luego hay otro parámetro superclásico, la famosa
tasa de aprendizaje, el learning rate.
Sí.
Que lo configuran en 1 elevado a menos
4, el 1e4.
Esto, si lo bajamos a tierra para visualizarlo,
es básicamente la longitud de la zancada que
da el modelo mientras busca la respuesta correcta
en el entrenamiento.
Tal cual, la longitud del paso.
Durante el entrenamiento, el modelo hace predicciones y
se equivoca.
Se equivoca mucho al principio respecto a los
ejemplos perfectos que le hemos dado.
Lógico.
Pues la tasa de aprendizaje define con qué
agresividad corrige esos errores.
Si das un paso demasiado grande… Tropieza.
Bueno, sobrecorrige.
Se vuelve inestable y nunca consolida lo que
aprende.
Se pasa de frenada.
Ya.
¿Y si el paso es muy pequeñito?
Pues que el entrenamiento podría tardar semanas en
converger, porque va a pasito de tortuga.
Claro.
Entonces, el valor de 1e4 es un estándar.
Es un valor muy sólido.
Comprobado ya, empíricamente, para métodos como este, como
Qlorra.
Es el punto dulce.
Eso es.
Asegura que el modelo alumno asimile las trazas
de razonamiento de forma estable y a un
buen ritmo.
Vale.
Y para rematar esta receta de configuración, establecen
un temaño de lote, el batch size, de
10.
Y configuran 100 pasos de entrenamiento.
Que las matemáticas cuadran solas ahí.
Claro.
Hacemos la cuenta matemática básica de primaria.
10 ejemplos por lote, multiplicados por 100 pasos,
nos da exactamente los 1000 ejemplos sintéticos que
habíamos generado en la receta al principio.
Es decir, que el modelo se lee el
libro de texto completo una sola vez.
Es lo que en el mundillo se conoce
como hacer una época.
Una época entera.
Vale.
Y mientras esto ocurre, lo bueno de la
interfaz visual es que el usuario no está
mirando una terminal con letras verdes pasando a
toda velocidad.
No.
¿Tienes una gráfica visual?
Sí.
El sistema te dibuja una curva de pérdida,
el training loss, que según cuentan las fuentes,
va cayendo en picado.
Es que esa curva descendente es la confirmación
visual de que la transferencia de conocimiento está
funcionando.
Que está aprendiendo, vamos.
Claro.
La pérdida representa la diferencia entre lo que
el modelo predice y la respuesta perfecta de
nuestro conjunto de datos.
Ver cómo esa línea baja de forma constante
te está indicando que el alumno está comprendiendo
e interiorizando la estructura lógica.
Se está convirtiendo en un pensador analítico delante
de tus ojos.
Exacto.
Pero a ver, el hito más importante de
todo este proceso, lo que de verdad, de
verdad cambia las reglas del juego, es el
tiempo que tarda en dibujarse esa curva.
Ay, es que esa es la cifra que
deja a cualquiera sin palabras.
En el hardware que utilizan para esta demostración
de un Sloth Studio, todo esto dura un
minuto.
60 segundos de reloj.
Me estás diciendo que tardas más en ir
a la cocina a hacerte un café que
en cambiarle el cerebro a una inteligencia artificial.
Es que es literal.
El impacto que tiene esta cifra, este minuto,
en la forma en que trabajamos y desarrollamos
tecnología, es absolutamente colosal.
Es que lo cambia todo.
No es solo una cuestión de, ay, somos
muy impacientes y queremos las cosas ya.
Es que si tardas un minuto en entrenar
un modelo, el coste del error prácticamente desaparece
de la ecuación.
Totalmente.
Tú puedes plantear una hipótesis.
Preparas los datos visualmente.
Entrenas en un minuto.
Pruebas y, oye, que sale mal, que alucina
o lo que sea.
Pues no pasa nada.
Pues no pasa nada.
Cambias dos parámetros y lo vuelves a intentar
cinco minutos después.
Esta velocidad de iteración transforma por completo el
ciclo de investigación.
Has dado en la diana.
La reducción del tiempo de iteración es el
verdadero motor de cualquier innovación tecnológica.
Ajá.
Piensa que cuando entrenar un modelo requería alquilar
instancias en la nube que te costaban miles
de dólares… Y esperar semanas para ver si
funcionaba.
Claro.
El margen para la experimentación era nulo.
Te la jugabas a una carga.
Cierta.
Solo las grandes corporaciones con unos presupuestos ilimitados
podían permitirse fracasar.
Y tirar a la basura todo ese dinero
y tiempo.
Eso es.
Al comprimir ese ciclo a un minuto, en
un entorno local, en tu casa, y gratuito,
estamos permitiendo que desarrolladores independientes, estudiantes de universidad
o pequeñas startups… Prueben 50 ideas diferentes en
una sola tarde de domingo.
Exactamente.
La fricción para innovar se ha reducido literalmente
a cero.
Es flipante.
Y bueno, toda esta fricción reducida culmina en
el momento en el que la innovación se
vuelve más fácil.
Y es que el momento de la verdad
en Unslot Studio.
La evaluación empírica.
Porque, oye, la teoría matemática es impecable.
Nos ha quedado clarísimo.
Sí.
Sobre el papel, todo funciona.
Pero hay que ver cómo se comporta el
modelo en la práctica.
En el proceso descrito, una vez finalizado ese
minuto glorioso de entrenamiento, se van a la
pestaña de chat… Sí, cargan a este nuevo
alumno ya graduado.
Y le lanzan una consulta de lógica.
Es que el cambio de comportamiento ahí es
el test definitivo del éxito de la destilación.
Qué hacía antes y qué hace ahora.
Mira, antes del entrenamiento, si tú le hacías
una pregunta compleja de varios pasos, al modelo
base intentaba escupir la respuesta final casi de
forma instintiva.
Como un loro.
Sí.
Y a menudo equivocándose estrepitosamente en la lógica.
Pero tras aplicar nuestra receta de mil ejemplos…
¿Qué pasa?
El comportamiento se transforma radicalmente.
El modelo hace una pausa conceptual.
Empieza a escupir texto con etiquetas de pensamiento,
¿no?
Exacto.
Detalles.
Vaya explícitamente su tren de pensamiento.
Evalúa las premisas de la pregunta.
Descarta opciones que no tienen sentido.
Razona.
Razona.
Y sólo al final de esa larguísima cadena
deductiva proporciona la respuesta correcta.
Ha asimilado por completo la metodología del profesor.
Es la cristalización de todo el esfuerzo.
Y lo mejor de todo, y esto es
clave, es que este nuevo modelo supercapaz que
nos hemos fabricado no se queda secuestrado dentro
del programa de Unsloth.
No, no.
Tú eres dueño del archivo.
Claro.
El flujo de trabajo finaliza en la pestaña
Export, explicando cómo se exporta al mundo real.
Utilizan un estándar fantástico del código abierto llamado
llama .cpp.
L -L -A -M -A punto C -P
-P.
Sí.
Que sirve para empaquetar el modelo, manteniendo además
esa cuantización, esa compresión de las notas adhesivas
de la que hablábamos.
O sea, te genera un archivo comprimido listo
para usar.
La exportación es, de hecho, lo que convierte
un simple experimento de laboratorio en una herramienta
de producción real.
Claro.
Al empaquetarlo, en ese formato, ese modelo ya
es completamente autónomo.
Es un archivito que puedes integrar en una
aplicación propia.
Lo puedes subir a un servidor interno de
tu empresa para que lo usen tus empleados,
o simplemente compartirlo con la comunidad en Internet.
Demuestra que el objetivo de estas herramientas visuales
no es sólo hacer, digamos, investigación académica aburridas.
Sino la creación de utilidades prácticas y aplicables
en el mundo real, hechas por cualquiera.
Desde casa.
Es el empoderamiento absoluto del usuario frente a
la famosa caja negra de las grandes tecnológicas.
Herramientas visuales superintuitivas combinadas con métodos de compresión
matemáticos brillantes bajo el capó.
Nos han puesto directamente a los mandos.
Ya no somos pasajeros.
Ya no somos pasajeros esperando a ver que
IA decide lanzar la gran corporación de turno
el mes que viene, pagando una suscripción.
Ahora sí.
Ahora somos nosotros los ingenieros capaces de fabricar
la herramienta exacta que necesitamos.
Y gratis.
En nuestra propia casa, a coste cero y
en un tiempo récord.
Y fíjate, eso, si nos paramos a pensar
un segundo en las implicaciones a largo plazo
de este empoderamiento, nos deja ante un escenario
fascinante para cerrar.
A ver, cuéntame.
Hoy hemos analizado cómo un usuario enseñaba a
un modelo a mejorar su lógica básica utilizando
mil ejemplos genéricos de preguntas y respuestas.
Sí, una prueba de concepto, digamos.
Exacto.
Pero la verdadera explosión de valor llegará pronto
con la hiperespecialización.
Si una simple tarjeta gráfica comercial puede reconfigurar
el razonamiento lógico de una IA en un
minuto, imaginemos lo que ocurrirá cuando comunidades enteras
empiecen a crear sus propias recetas de datos
sintéticos.
Ostras, claro.
Imaginemos a colectivos de médicos afinando sus propios
modelos locales con miles de diagnósticos diferenciales complejísimos.
O a bufetes de abogados.
Totalmente, destilando IA para que argumente basándose en
jurisprudencia local muy específica de su comunidad autónoma.
O ingenieros civiles creando asistentes expertos en normativas
de construcción superáridas.
Es que la democratización técnica de estas herramientas
significa que el futuro de la inteligencia artificial
igual no va a ser un único modelo
gigante y omnisciente controlado por una corporación.
Sino millones de pequeños modelos ultraespecializados.
Exacto.
Forjados por expertos de cada sector, desde los
escritorios de sus propias casas.
Me parece una reflexión final espectacular.
Antes de despedirnos, hasta el próximo programa, os
informamos de que las voces que oyes han
sido generadas por la IA de Notebook LM.
Y que dirigiendo al podcast se encuentra Julio
Pablo Vázquez, un humano que te envía saludos.
En caso de error, probablemente sean errores humanos.
Nos escuchamos.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMpraxis.
Nos escuchamos en el próximo episodio.