Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:09
0:15
0:20
0:23
0:26
0:28
0:36
0:40
0:41
0:44
0:46
0:48
0:49
0:52
0:53
0:56
0:59
1:02
1:04
1:04
1:05
1:07
1:10
1:13
1:13
1:14
1:16
1:19
1:22
1:23
1:24
1:27
1:30
1:33
1:37
1:40
1:41
1:44
1:46
1:48
1:49
1:50
1:52
1:55
1:57
1:58
2:01
2:03
2:06
2:08
2:10
2:11
2:14
2:16
2:19
2:22
2:25
2:26
2:27
2:31
2:34
2:36
2:36
2:40
2:43
2:44
2:48
2:51
2:54
2:56
2:58
3:00
3:01
3:02
3:05
3:08
3:11
3:14
3:17
3:18
3:20
3:21
3:24
3:26
3:29
3:33
3:35
3:36
3:39
3:43
3:44
3:46
3:47
3:49
3:53
3:55
3:58
3:58
4:01
4:05
4:06
4:08
4:10
4:11
4:14
4:16
4:19
4:21
4:23
4:25
4:25
4:28
4:30
4:32
4:35
4:37
4:39
4:40
4:43
4:46
4:48
4:49
4:52
4:52
4:55
4:58
5:02
5:05
5:07
5:10
5:13
5:13
5:14
5:16
5:18
5:19
5:21
5:22
5:25
5:27
5:30
5:33
5:36
5:38
5:38
5:40
5:40
5:42
5:45
5:46
5:50
5:53
5:54
5:56
5:59
6:00
6:03
6:04
6:07
6:10
6:11
6:13
6:13
6:16
6:19
6:22
6:23
6:25
6:26
6:28
6:28
6:31
6:34
6:37
6:39
6:39
6:42
6:43
6:44
6:44
6:47
6:48
6:50
6:51
6:54
6:56
6:58
7:01
7:02
7:04
7:05
7:08
7:09
7:11
7:13
7:14
7:17
7:20
7:22
7:24
7:27
7:27
7:29
7:30
7:33
7:35
7:36
7:37
7:39
7:41
7:42
7:44
7:45
7:47
7:49
7:52
7:55
7:56
7:58
8:00
8:01
8:04
8:07
8:11
8:14
8:17
8:17
8:21
8:23
8:25
8:26
8:29
8:31
8:31
8:34
8:36
8:37
8:40
8:43
8:45
8:49
8:52
8:53
8:56
8:59
9:01
9:02
9:04
9:05
9:06
9:07
9:07
9:10
9:11
9:13
9:16
9:19
9:21
9:23
9:26
9:28
9:30
9:32
9:34
9:34
9:37
9:40
9:42
9:45
9:47
9:50
9:52
9:54
9:54
9:55
9:59
10:03
10:06
10:07
10:09
10:10
10:14
10:15
10:19
10:21
10:22
10:25
10:29
10:31
10:32
10:34
10:37
10:40
10:42
10:46
10:47
10:50
10:52
10:53
10:54
10:56
10:58
11:00
11:01
11:03
11:06
11:07
11:10
11:11
11:13
11:15
11:19
11:21
11:22
11:23
11:26
11:29
11:31
11:33
11:35
11:39
11:43
11:46
11:49
11:52
11:55
11:58
12:01
12:01
12:04
12:05
12:07
12:10
12:12
12:15
12:17
12:18
12:19
12:21
12:25
12:29
12:31
12:31
12:34
12:36
12:38
12:39
12:40
12:41
12:44
12:46
12:49
12:51
12:54
12:57
12:59
13:02
13:04
13:05
13:08
13:11
13:14
13:14
13:17
13:19
13:22
13:24
13:24
13:28
13:29
13:32
13:33
13:36
13:40
13:41
13:42
13:45
13:47
13:49
13:52
13:55
13:58
13:59
14:02
14:05
14:08
14:10
14:13
14:14
14:14
14:15
14:18
14:21
14:22
14:23
14:26
14:28
14:32
14:35
14:36
14:37
14:38
14:40
14:43
14:46
14:48
14:49
14:52
14:54
14:56
14:59
15:01
15:02
15:04
15:08
15:10
15:14
15:17
15:20
15:21
15:23
15:25
15:27
15:28
15:31
15:34
15:36
15:38
15:41
15:43
15:46
15:48
15:50
15:53
15:56
15:57
15:58
16:01
16:06
16:07
16:11
16:16
16:18
16:20
16:22
16:24
16:26
16:29
16:33
16:35
16:36
16:39
16:41
16:44
16:45
16:47
16:50
16:53
16:56
16:59
17:01
17:03
17:04
17:07
17:08
17:12
17:15
17:16
17:17
17:20
17:22
17:25
17:27
17:29
17:32
17:44
17:47
17:58
18:00
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas, bienvenidas, bienvenidos a un nuevo episodio
de BIMPRAXIS.
Hoy os traemos la muerte del código repetitivo
al integrar inteligencia artificial.
Y ya era hora, la verdad.
Totalmente.
Pues, a ver, para arrancar, imaginemos el siguiente
escenario.
Existe la necesidad de auditar una noticia diplomática
internacional sobre las relaciones entre Canadá y el
Reino Unido, para verificar si es falsa.
Un caso de uso muy típico hoy en
día.
Exacto.
Y el objetivo es conectar el motor de
reconocimiento visual de Microsoft con la capacidad analítica
del modelo CloudSonnet de Anthropic.
Casi nada.
Claro.
O sea, lograr que esos dos sistemas… …
de empresas rivales se comuniquen, procesen la imagen,
detecten que es una noticia fabricada y devuelvan
el análisis completo a tu servidor.
Sí, sí.
Y la meta, ojo a esto, es hacer
todo esto en menos de cinco minutos, con
un coste operativo exacto de 0 ,002 dólares
y, lo más importante, sin escribir ni una
sola línea de código de infraestructura.
Madre mía.
A ver, hasta hace muy poco, si propones
esta arquitectura a un equipo de ingeniería… …
bueno, habría provocado unas cuantas risas en la
sala.
Ya te digo.
Habría provocado risas porque, claro, el coste en
horas de desarrollo para establecer esa pasarela de
comunicación habría sido astronómico.
Total.
Integrar sistemas heterogéneos siempre ha sido el gran
cuello de botella, ¿sabes?
Tradicionalmente, hablar de orquestar múltiples modelos implicaba construir
un andamiaje técnico masivo.
Sí, el temido boilerplane.
Eso es.
Cada proveedor tiene su propio esquema de autenticación,
su propio formato para los… … payloads de
datos, su forma de estructurar los Jasons.
Mapear todo eso a mano requiere meses de
trabajo tedioso que no aporta ningún valor directo
al usuario final.
Vale, vamos a desgranar esto.
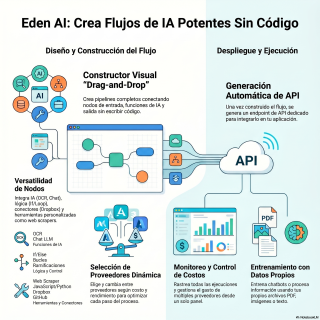
Hoy exploramos cómo la plataforma Eden AI está
transformando de raíz todo esto al eliminar ese
trabajo repetitivo.
Eso es.
Nuestra misión en este análisis es comprender cómo,
a partir del material y las demostraciones presentadas
por Taja, que es el CEO de la
compañía, cualquier persona puede combinar decenas de modelos
de IA, gestionar los costes y generar APIs
listas para producción sin tocar código base.
Y para entender por qué esto está ganando
tanta atracción, hay que observar el estado actual
del ecosistema de las APIs.
Claro, que es un caos ahora mismo.
Exacto.
En un entorno donde cada semana surge un
modelo nuevo con más contexto o un coste
más reducido, pues el peor enemigo de un
equipo de desarrollo es el vendor lock -in,
el famoso bloqueo del proveedor.
Totalmente.
Estás atado de pies y manos.
Así es.
La premisa base de Eden AI es actuar
como una capa de abstracción universal.
Ofrecen acceso directo a una variedad inmensa de
modelos listos para usar, permitiendo seleccionar la mejor
opción del mercado en cada momento.
Ajá.
Y bueno, para quienes buscan soluciones más acotadas,
también incluyen un constructor de chatbots personalizados que
ingiere documentos propios.
Como PDFs, que es un punto de entrada
excelente.
O sea, para que nos hagamos una idea,
la integración tradicional es como si para montar
un coche tuvieras que fabricar las piezas del
motor desde cero cada vez.
Literalmente.
Y mientras que Eden AI es como tener
un garaje infinito, donde simplemente encajas el motor
que mejor te convenga ese día.
Me gusta mucho esa analogía, sí.
Pero claro, yo soy un poco escéptica con
esto.
¿Qué pasa si ese motor maravilloso falla en
mi trabajo?
¿Qué pasa si mi plataforma de salud depende
de un servicio externo y los servidores de
ese proveedor sufren una caída?
Que devuelven un error 500, claro.
Exacto.
Si devuelven un error 500, el servicio en
cascada también se cae.
¿Cómo aborda esta herramienta el problema de la
tolerancia a fallos sin obligarnos a programar bucles
infinitos de reintentos?
Pues mira, esa es la preocupación arquitectónica número
uno.
Lo fascinante aquí es cómo resuelven la resiliencia
del sistema mediante los llamados proveedores de respaldo,
o fallback providers.
Ah, vale.
O sea, un plan B automatizado.
Eso es.
En código puro, interceptar un try -out y
enrutar la petición hacia otro modelo requiere gestionar
a sincronía, volver a formatear el payload, manejar
nuevos errores… Un dolor de cabeza, vamos.
Un dolor de cabeza que introduce mucha latencia.
Pero en el ecosistema de Eden AI… Esta
capa de redundancia se configura a nivel de
nodo.
Ya veo.
Se establece un proveedor principal.
Digamos, el modelo de Microsoft para la extracción
de texto.
Y se asigna a Amazon como respaldo.
Entiendo.
Entonces, la plataforma asume el rol de middleware.
Si el endpoint de Microsoft tarda más de
la cuenta, Eden AI intercepta ese fallo en
tiempo real, traduce internamente los parámetros al formato
de Amazon y ejecuta la llamada, sin que
la aplicación principal se entere.
Exactamente.
Y la latencia añadida a la aplicación es
la misma.
La durada por este cambio es de milisegundos.
Para el cliente final, el sistema simplemente sigue
funcionando.
Garantizas una alta disponibilidad empresarial sin mantener bloques
de código gigantescos dedicados a gestionar desastres.
¡Qué locura!
Ya que hemos tocado el tema de estandarizar
datos, creo que es el momento perfecto para
cuestionar el cómo.
A ver… Entiendo la teoría de la tolerancia
a fallos en el backend.
Pero el material hace mucho hincapié en que
toda esta orquestación se realiza visualmente.
Sí.
Mediante un constructor de flujos de trabajo.
Eso es.
Un lienzo con nodos de arrastrar y soltar.
Y quienes hemos trabajado con herramientas no -code,
sabemos que unir cajitas de colores suena muy
bien.
Hasta que los esquemas de datos chocan.
Claro, claro.
Los mapeos son el terror.
Exacto.
¿Cómo resuelve la interfaz visual el mapeo de
variables entre, por ejemplo, un sistema de reconocimiento
óptico y un gran modelo de lenguaje?
Esa es la clave del diseño de la
plataforma.
Para ilustrarlo, la demo desgrana ese caso de
uso de la noticia de la BBC que
decías antes.
Sí.
La arquitectura requiere tres eslabones.
Primero, el nodo de entrada.
Aquí defines el esquema de datos que el
flujo va a recibir.
En este caso, configuran un archivo de imagen
y una consulta de texto dinámica.
Vale, ese sería el punto de ingesta.
Y de ahí pasamos al procesamiento.
Correcto.
Ahí entra el segundo nodo, que es el
OCR multipágina.
Configuran a Microsoft como principal y Amazon de
respaldo.
El reto aquí no es invocar al OCR,
sino cómo pasarle la imagen.
Claro, el formato.
Pues en la interfaz visual, en lugar de
escribir código para parsear el archivo, simplemente vinculas
el campo de entrada del OCR a la
variable de imagen del primer nodo.
La plataforma serializa los datos por debajo.
Vale.
Aquí es donde la cosa se pone muy
interesante.
Porque el texto extraído por ese OCR de
Microsoft no es el resultado final, ¿verdad?
No, qué va.
Es sólo el contexto.
Es el combustible.
En el tercer nodo añaden a Cloud Sonnet
de Anthropic.
Y el mecanismo para conectar estos dos mundos
es brillante.
Sí, es súper ágil.
En lugar de tener que limpiar el JSON
de Microsoft, simplemente seleccionas el texto en bruto
del OCR y lo inyectas dinámicamente en el
LLM.
Es como tener a un intérprete simultáneo de
la ONU integrado en el lienzo.
Totalmente.
Microsoft habla en su propio dialecto visual.
Pero el motor de Eden AI traduce instantáneamente
ese resultado al formato de texto.
Esa metáfora del intérprete es muy precisa.
La plataforma abstrae por completo la transformación de
datos.
Tú diseñas la orquestación semántica, es decir, qué
hace la información, mientras que el motor subyacente
maneja la sintaxis técnica.
Qué pasada.
Y a esto le suman el System Prompt
y la consulta del usuario, ¿no?
Exacto.
Y por eso cuando ejecutan la prueba con
la captura de la BBC, opera de manera
súper fluida.
El OCR extrae los caracteres, los transfiere al
LLM, el modelo evalúa la consulta y alerta
sobre la falsedad de la noticia.
Una colaboración perfecta por 0 ,002 dólares.
Es que democratiza por completo la experimentación arquitectónica.
Sin duda.
Perfiles no tan técnicos pueden visualizar y diseñar
el flujo exacto de la información sin depender
de un equipo de ingeniería durante tres semanas.
Eso es.
Pero claro, esto me lleva a la pregunta
inevitable.
¿El entorno de pruebas?
Sí.
El sandbox.
Siempre funciona de maravilla en las demos.
Siempre sí.
La gran barrera suele ser el despliegue.
Yo monto este lienzo y está muy guay.
Pero, ¿cómo lo saco de ahí, para integrarlo
en una base de código real que atienda
miles de peticiones?
¿Simplemente conecto esto a mi aplicación y ya
ejecuta toda la cadena por sí solo?
Pues sí, porque el puente hacia producción es
la generación automatizada de APIs.
¿Te genera la API directamente?
Sí.
Una vez que el flujo está testeado, la
plataforma compila esa lógica y levanta endpoints dedicados
exclusivamente a ese flujo.
No exportas código, expones la máquina a través
de peticiones HTTP estándar.
Entonces, a ojos de cualquier aplicación externa, el
flujo entero se convierte en una única caja
negra a la que llamas a través de
una API.
Exactamente.
Tienen ejemplos listos para integrar en Python con
Django o FastAPI y en NodeJS para JavaScript.
El sistema expone dos puntos de conexión principales.
Vale.
El primero es un endpoint post para lanzar
la ejecución.
Ahí es donde envías el payload inicial, la
imagen y la pregunta.
Claro, pero al lanzar ese post, nos enfrentamos
a la asincronía de la IA.
Ese es el gran tema.
Si enviamos un documento de 50 páginas para
un OCR y luego un LLM, esa operación
no se va a resolver en 200 milisegundos.
Para nada.
Puede tardar segundos o minutos.
Entonces, si mi aplicación usa un método GET
estándar para ver si ya está el resultado,
tengo que implementar una técnica de polling.
Estar preguntando constantemente al servidor si ha terminado.
Uf, no.
El polling constante es una práctica arquitectónica terrible
para la escalabilidad.
Ya, saturas el ancho de banda a lo
tonto.
Mantienes conexiones abiertas.
Consumes recursos en cliente y servidor.
Es un desastre.
Por eso usan webhooks.
Ah, vale.
Lo cual cambia el paradigma por completo.
Totalmente.
En la petición post inicial, incluyes la URL
de un webhook tuyo.
Y te desentiendes.
El flujo procesa los nodos a su ritmo.
Y cuando termina, la plataforma hace una petición
activa contra ese webhook, entregando los datos.
¿Te avisan ellos a ti?
Exacto.
Madre mía, si conectamos esto con el panorama
general, el impacto masivo que tiene esto radica
en la brutal contracción de los ciclos.
Es brutal, sí.
Lo que antes te llevaba semanas de escribir
código de infraestructura, gestionar colas de mensajes, programar
reintentos, todo ese trabajo oscuro, queda delegado.
El salto desde un lienzo visual hasta una
API asíncrona, robusta, ocurre en segundos.
Es una reasignación de los recursos de ingeniería.
Los equipos técnicos pueden dejar de mantener conexiones
y empezar a optimizar el producto.
Ahora bien, para que este análisis sea riguroso,
tenemos que hacer un análisis.
Tenemos que escalar un poco la complejidad.
Venga.
Porque hasta ahora, esto es una tubería lineal.
Entra imagen, va al OCR, luego al LLM
y sale el resultado.
Pero las aplicaciones reales no son líneas rectas.
No, rara vez lo son.
O sea, esto ya no es solo una
cadena de montaje básica.
Es una fábrica inteligente.
Las cintas transportadoras necesitan reaccionar a los datos,
ramificarse, tomar decisiones y conectarse con bases de
datos externas que no tienen nada que ver
con la IA.
Si la plataforma visual no permite ramificar, se
convierte en un juguete.
Esa es una crítica muy habitual hacia las
plataformas no -code.
Y está muy justificada.
Claro.
Pero para evitar ese techo de cristal, incorporan
nodos lógicos y de integración.
El material detalla el uso de nodos IF,
declaraciones condicionales… Vale.
Te permiten inspeccionar el payload en cualquier punto
y bifurcar el flujo en distintos hilos.
O sea, ¿enrutamiento dinámico?
Por ejemplo, imaginemos un sistema de soporte técnico.
Entra un texto y un modelo rápido lo
categoriza.
Si el nodo IF detecta que el ticket
requiere un análisis legal, enruta la información por
una rama distinta hacia un modelo más pesado
y costoso.
Ese es exactamente el propósito.
Y también tienen nodos de bucle, los famosos
loops, para iterar sobre listas de datos como
correos electrónicos.
Ajá.
Y para potenciar aún más esto, incluyen conectores
externos integrados.
Mencionan integraciones directas con repositorios, ¿verdad?
Así es.
Puedes configurar un nodo que interactúe con Supabase
para registrar resultados o descargar archivos de Dropbox
o conectarte con GitHub.
¡Guau!
Incluso tienen web scrapers para extraer texto de
una URL en medio del flujo.
Vale, entiendo el atractivo.
Pero cualquiera que haya programado sabe que siempre
te encuentras con un requerimiento de negocio tan
específico que ningún nodo prefabricado te sirve.
Siempre pasa.
Un algoritmo matemático súper tuyo o limpiar una
cadena con expresiones regulares muy complejas.
Cuando llegas a ese muro en una herramienta
visual, el proyecto se cae.
¿Hay alguna vía de escape para inyectar lógica
pura?
Absolutamente.
Y es vital.
Disponen de un nodo de código personalizado.
Es un entorno seguro donde puedes inyectar código
JavaScript puro.
¡Ah, qué bueno!
En la demo muestran un ejemplo sencillo.
Una función en JavaScript que recibe un nombre,
digamos taja, y devuelve un saludo dinámico estructurado.
Un ejemplo básico, pero demuestra que no es
una jaula de oro.
Exacto.
Es una válvula de escape.
Si no hay un bloque para tu transformación
rara de datos, abres el nodo de código,
programas en JavaScript y ese nodo se integra
en la cadena visual sin romper la arquitectura.
Eso es.
Y si la cosa se pone extrema, recomiendan
apoyarse en su comunidad de Discord, que es
un centro neurálgico para resolver dudas.
Y a ver, esto plantea una pregunta importante
sobre la evolución de la ingeniería de software.
¿Te escucho?
La integración de nodos, condicionales y vías de
escape de código representa un cambio de paradigma.
Históricamente, el valor de un desarrollador era dominar
la sintaxis, gestionar memoria, protocolos HTTP… Sí.
Pero cuando las plataformas asumen toda esa fricción,
el talento técnico evoluciona hacia la macroorquestación de
sistemas.
O sea, el valor ya no es saber
programar la pasarela.
El valor está en el pensamiento sistémico.
Exactamente.
Está en poseer la visión para decidir qué
combinación de modelos, qué lógica de ramificación y
qué conectores van a resolver el problema de
negocio de forma más barata y eficiente.
Es un desplazamiento total hacia el diseño puro
de la lógica de producto.
Prototipas, pruebas con modelos reales y despliegas en
preproducción en la misma tarde.
Entonces, ¿qué significa todo esto?
Si recopilamos lo que hemos analizado, resulta evidente
que EDEN .AI es mucho más que un
directorio de modelos.
Mucho más.
Se posiciona como una capa de infraestructura crítica
que transforma meses de programación en un diseño
visual ágil.
Tolerancia a fallos automática, traducción de formatos, webhooks,
código personalizado… Eliminan la inmensa fricción entre la
teoría y el despliegue en producción.
Es un habilitador tecnológico símbolo.
Sin precedentes para las empresas, desde luego.
Y esto nos lleva a una reflexión profunda
para quienes nos escuchan hoy.
Hemos visto cómo ahora se pueden estructurar arquitecturas
complejas y manejar errores de servidor en minutos
sin infraestructura propia.
Así es.
Ante este panorama, cabe plantearse, ¿qué va a
ocurrir con la barrera de entrada para crear
software complejo en los próximos cinco años?
Es una gran pregunta.
Si la gestión de infraestructura deja de ser
un requisito, es posible que el próximo gigante
tecnológico mundial sea construido por alguien brillante que
simplemente arrastró y soltó los nodos correctos sin
escribir jamás la infraestructura subyacente de su imperio.
Uf, es un escenario fascinante sobre el que
merece la pena meditar, sin duda.
Totalmente.
Ha sido un verdadero privilegio explorar la arquitectura
detrás de este cambio de paradigma hoy.
Un placer profundizar en estos mecanismos arquitectóricos.
Sigan analizando y cuestionando los cimientos de la
tecnología que nos rodea.
Hasta la próxima.
Antes de despedirnos hasta el próximo programa, os
informamos de que las voces que oyes han
sido generadas por la IA de Notebook LM
y que dirigiendo el podcast se encuentra Julio
Pablo Vázquez, un humano que te envía saludos.
En caso de error, probablemente sean errores humanos.
¡Nos escuchamos!
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIM Praxis.
Nos escuchamos en el próximo episodio.