Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:10
0:15
0:20
0:23
0:26
0:28
0:37
0:38
0:40
0:41
0:43
0:46
0:47
0:49
0:50
0:52
0:53
0:56
0:58
1:00
1:04
1:07
1:09
1:11
1:14
1:16
1:19
1:21
1:24
1:28
1:30
1:31
1:34
1:37
1:40
1:43
1:46
1:48
1:51
1:55
1:57
2:00
2:02
2:03
2:06
2:09
2:10
2:13
2:16
2:20
2:22
2:23
2:25
2:27
2:29
2:31
2:32
2:33
2:36
2:36
2:39
2:41
2:43
2:46
2:48
2:49
2:52
2:55
2:57
2:58
3:00
3:03
3:06
3:08
3:11
3:14
3:15
3:16
3:20
3:23
3:25
3:27
3:28
3:30
3:33
3:35
3:37
3:40
3:44
3:46
3:49
3:51
3:51
3:55
3:56
3:59
4:01
4:04
4:07
4:09
4:12
4:14
4:16
4:17
4:20
4:22
4:25
4:26
4:28
4:29
4:31
4:34
4:37
4:39
4:41
4:44
4:45
4:47
4:52
4:53
4:56
4:56
4:58
5:00
5:01
5:03
5:06
5:07
5:11
5:13
5:15
5:17
5:20
5:23
5:25
5:27
5:29
5:31
5:33
5:35
5:37
5:38
5:40
5:42
5:44
5:47
5:50
5:52
5:54
5:57
5:59
6:01
6:02
6:05
6:08
6:10
6:12
6:13
6:15
6:16
6:19
6:21
6:23
6:25
6:27
6:28
6:30
6:31
6:34
6:36
6:39
6:40
6:42
6:44
6:46
6:48
6:50
6:52
6:54
6:57
6:59
7:00
7:00
7:03
7:05
7:08
7:10
7:12
7:14
7:17
7:17
7:20
7:22
7:24
7:27
7:30
7:33
7:34
7:35
7:37
7:41
7:42
7:44
7:46
7:47
7:48
7:50
7:52
7:55
7:58
8:00
8:02
8:04
8:06
8:07
8:09
8:10
8:11
8:13
8:16
8:18
8:20
8:23
8:25
8:28
8:31
8:33
8:36
8:39
8:42
8:44
8:46
8:48
8:51
8:54
8:57
8:59
9:00
9:03
9:07
9:10
9:11
9:13
9:16
9:19
9:20
9:23
9:25
9:26
9:30
9:33
9:34
9:36
9:39
9:40
9:40
9:43
9:46
9:49
9:51
9:53
9:55
9:56
9:59
9:59
10:00
10:02
10:04
10:06
10:08
10:10
10:12
10:14
10:15
10:16
10:19
10:20
10:22
10:24
10:26
10:27
10:29
10:33
10:35
10:36
10:37
10:39
10:43
10:45
10:47
10:50
10:50
10:53
10:54
10:58
11:00
11:01
11:05
11:06
11:06
11:09
11:11
11:14
11:18
11:20
11:22
11:24
11:27
11:29
11:31
11:32
11:35
11:38
11:40
11:42
11:45
11:47
11:48
11:50
11:53
11:55
11:58
12:00
12:03
12:06
12:08
12:08
12:10
12:12
12:14
12:17
12:19
12:21
12:23
12:24
12:27
12:29
12:31
12:34
12:35
12:39
12:43
12:45
12:47
12:49
12:52
12:55
12:56
12:56
12:57
12:58
13:02
13:05
13:08
13:10
13:10
13:13
13:15
13:17
13:19
13:22
13:23
13:24
13:27
13:30
13:33
13:36
13:37
13:40
13:43
13:45
13:49
13:51
13:53
13:55
13:58
14:02
14:06
14:10
14:11
14:13
14:15
14:19
14:22
14:26
14:26
14:27
14:30
14:32
14:34
14:36
14:37
14:41
14:42
14:45
14:46
14:47
14:49
14:50
14:51
14:54
14:56
14:58
14:59
15:01
15:03
15:05
15:09
15:12
15:15
15:18
15:19
15:22
15:25
15:27
15:29
15:31
15:34
15:35
15:38
15:40
15:42
15:44
15:47
15:48
15:51
15:52
15:56
15:58
16:01
16:02
16:05
16:08
16:10
16:12
16:14
16:14
16:16
16:18
16:20
16:24
16:26
16:28
16:29
16:32
16:36
16:39
16:42
16:44
16:47
16:49
16:52
16:54
16:57
16:59
17:02
17:05
17:08
17:10
17:13
17:14
17:17
17:20
17:23
17:26
17:38
17:40
17:54
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas.
Bienvenidas, bienvenidos a un nuevo episodio de Bean
Praxis.
Hoy os traemos el horizonte temporal de la
inteligencia artificial, midiendo las máquinas con el reloj
humano.
Y a ver, imaginemos este escenario por un
momento.
Acabamos de contratar a un desarrollador brillante para
nuestro equipo.
Sí, el típico perfil técnico perfecto.
Exacto, el de manual En la entrevista ha
demostrado conocer la sintaxis de todos los lenguajes
Domina las estructuras de datos más complejas Y
te responde a cualquier pregunta teórica en milisegundos
Vale, suena genial Pero llega el primer día
de trabajo Le pedimos que arregle un bug
rutinario en el código de la empresa Y
resulta que tarda 81 minutos en hacer exactamente
lo mismo Que un programador junior nuestro resuelve
en apenas 5 ¡Madre mía!
Claro, pues esa desconexión, esa brecha enorme entre
el conocimiento teórico y la ejecución práctica es
exactamente donde se encuentra la inteligencia artificial hoy
en día.
Y bueno, es una brecha que las métricas
tradicionales no consiguen explicar, la verdad.
Porque constantemente leemos titulares sobre modelos de lenguaje
que aprueban exámenes de abogacía con notas sobresalientes
o superan pruebas médicas complejísimas.
Sí, sí, parece que lo saben todo.
Claro, pero el problema es que esas pruebas
estandarizadas evalúan pura recuperación de información estática.
O sea, saber la respuesta a una pregunta
tipo test no equivale para nada a tener
la capacidad de navegar por un entorno de
trabajo real.
No es lo mismo que tomar decisiones secuenciales,
corregir errores o entregar un proyecto, claro.
Eso es.
Y por eso, la investigación que analizamos hoy,
que está publicada por METR, una organización sin
ánimo de lucro que evalúa sistemas avanzados, cambia
completamente el paradigma.
Han dejado de medir a la IA por
puntuaciones de exámenes.
Han ido a algo mucho más práctico.
Exactamente.
Han empezado a medirla usando una unidad que
todos entendemos.
¿El tiempo?
Lo que ellos llaman el horizonte temporal, ¿verdad?
Justo.
Se trata de medir la duración máxima de
una tarea que la IA puede completar de
forma totalmente autónoma.
Y para eso, utilizan como base el tiempo
que le tomaría a un profesional humano realizar
ese mismo trabajo.
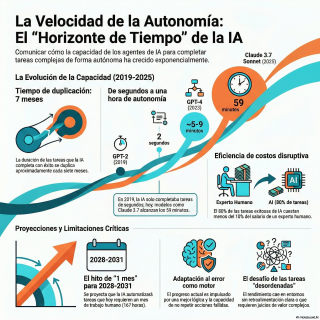
Y fíjate, el dato central que sacan de
esta investigación es rotundo, y es que la
capacidad temporal de las máquinas se está duplicando
cada siete meses.
¡Es una pasada de cifra!
Es que piénsalo, si cruzamos esta línea de
tendencia hacia el futuro, la proyección sugiere que,
para finales de esta década, podríamos ver modelos
capaces de ejecutar proyectos autónomos que a un
humano le llevarían un mes entero de curro.
Tela.
Pero a ver, para entender cómo sostienen una
afirmación de este calibre, necesitamos desgranar cómo miden
exactamente ese tiempo humano.
Porque no están simplemente poniendo un cronómetro al
lado de un servidor para ver cuánto tarda
en generar texto.
No, claro, no tendría sentido.
¿Cómo es el diseño del experimento entonces?
Pues es mucho más sofisticado.
El equipo de Metat montó un entorno de
evaluación con unas 170 tareas diferentes.
Hay de ingeniería de software, de ciberseguridad, aprendizaje
automático, un poco de todo.
Y las dividieron en tres categorías basadas en
la duración humana.
Vale.
La primera es lo que llaman acciones atómicas
de software.
Son microtareas de menos de un minuto.
Por ejemplo, navegar por un directorio para ver
qué archivo de texto tiene una contraseña.
A un humano eso le lleva tres segundos.
De abrir archivos y escanear.
Tareas mecánicas, en plan, el tipo de acciones
que hacemos casi por inercia mientras trabajamos en
otra cosa.
Precisamente.
Luego está el segundo nivel, que llaman H-Cast,
que amplía el rango temporal.
Aquí vamos desde un minuto hasta las 30
horas de trabajo.
Eso ya son palabras mayores.
Ya te digo.
Un ejemplo clásico sería darle a la máquina
un conjunto de datos desordenado en un archivo
JSON y pedirle que deduzca las reglas lógicas
para transformarlo.
A un ingeniero de datos experto le tomaría
unos 56 minutos escribir y probar el script
en Python para hacer esto bien.
Claro, ya requiere pensar y estructurar.
Y finalmente diseñaron la categoría Revenge para las
tareas más exigentes.
Hablamos de proyectos que rondan las 8 horas
de trabajo continuo.
continuo.
Ocho horas la máquina sola.
Sí, sí.
Retos como optimizar un bloque de código en
CUDA para que una herramienta financiera vaya 30
veces más rápido.
Eso requiere investigación, prueba, error y un conocimiento
muy profundo del hardware.
A ver, al ver la estructura de estas
pruebas me surge una duda importante sobre cómo
deciden si la máquina aprueba o no, porque
el estudio establece este horizonte temporal basándose en
tareas que la IA completa con una tasa
de éxito del 50%.
Sí, así es.
Pero claro, si trasladamos esto al mundo real,
cuesta justificarlo.
Si yo contrato a alguien para optimizar mi
base de datos y resulta que la mitad
de las veces me borra las tablas por
error, pues ese empleado no dura ni dos
días en la oficina.
¿Por qué elegir el 50% como estándar?
Es una buena pregunta, pero es que la
elección del 50% no busca establecer un estándar
comercial para vender el producto.
Busca un umbral matemático preciso.
Meter usa la teoría de respuesta al ítem,
que viene de la psicometría, para diseñar exámenes
muy complejos.
Vale, entiendo.
Básicamente, si evaluamos tareas donde el modelo acierta
el 90%, la prueba es demasiado fácil y
no nos dice dónde están sus límites.
Y si acierta el 10%, es puro ruido
estadístico.
Claro, no sabe si ha acertado de casualidad.
Exacto.
Así que el 50% es matemáticamente el punto
donde sacas más información.
Es la frontera exacta donde el conocimiento del
modelo empieza a desmoronarse.
Define el borde absoluto de lo que puede
hacer.
Su límite técnico real, digamos.
Eso es.
Aunque, bueno, los investigadores saben que la gente
quiere fiabilidad.
Así que también calcularon el horizonte exigiendo un
éxito del 80%.
¿Y si miramos los datos con ese filtro
del 80% qué pasa?
¿Se rompe la tendencia de mejora al exigir
los que sean más consistentes?
Pues lo más revelador de todo el estudio
es que la arquitectura matemática del crecimiento no
cambia absolutamente nada.
La pendiente de mejora es idéntica tanto si
exigimos un 50 como un 80.
¿En serio?
Sí, sí.
Lo único que pasa al pedir más fiabilidad
es que la curva entera baja un poco
en el eje del tiempo absoluto.
O sea, el tamaño de las tareas fiables
es menor, pero la velocidad a la que
aprenden a hacer tareas cada vez más largas
sigue duplicándose al mismo ritmo exacto.
¡Qué barbaridad!
Y si mapeamos esa frontera a lo largo
de los últimos años, las cifras muestran un
salto técnico increíble.
Porque en 2019 GPT-2 tenía un horizonte temporal
estimado de apenas dos segundos.
Su autonomía daba para autocompletar una frase lógica
y un poco más.
Literalmente.
Y hoy el modelo CLOUD de 3.7 SONNET
tiene un horizonte de 59 minutos al 50%
de éxito.
Y si le pedimos esa alta fiabilidad del
80%, se queda en 15 minutos.
Que no es poco.
Para nada.
Pasar de 2 segundos a 15 minutos de
trabajo intelectual complejo y autónomo en solo 5
años es una aceleración brutal.
Y esa aceleración obedece a esa constante matemática
que decíamos.
El tiempo de resolución se duplica exactamente cada
212 días.
Y ojo, no es que generen texto más
rápido.
Procesar texto a toda pastilla no te resuelve
un problema de una hora.
Claro.
El verdadero cuello de botella en las tareas
largas es que el razonamiento se degrada, ¿no?
Exactamente.
Cuanto más larga es la tarea, más fácil
es tomar una mala decisión a la mitad
que te descarrile todo el proyecto.
Pero fíjate, revisando la gráfica desde finales de
2023 hasta ahora, hay un detalle interesante.
Y es que la línea de tendencia no
solo se mantiene, sino que modelos recientes como
O1, que llega a 39 minutos, o Clot
3.7 están por encima de la proyección histórica.
Sí, están rompiendo un poco la escala.
Parece que hay un cambio cualitativo en cómo
abordan los problemas largos, ¿verdad?
Y ese cambio cualitativo es vital para entender
lo que está pasando bajo el capó.
MET hizo un análisis forense de los fracasos
de estos modelos para ver por qué se
colapsaban.
Compararon GPT-4 con el modelo O1.
Y vieron que de 31 fallos de GPT-4,
más de un tercio eran por repetición de
acciones fallidas.
Básicamente el modelo metía un comando en la
terminal, le daba error y volvía a meter
el mismo comando exacto una y otra vez.
Entraba en un bucle infinito.
Buf, como alguien empujando obstinadamente una puerta que
dice tirar hasta que se rinde.
Tal cual.
Pues en contraste analizaron 32 fallos de O1
y solo encontraron dos casos de este comportamiento
cíclico.
O sea, han dejado de darse cabezazos contra
el muro por fuerza bruta y ahora replantean
la estrategia.
Eso es.
Los modelos nuevos leen el error, ven que
la herramienta está dando problemas, borran el archivo
dañado y deciden reescribir todo desde cero con
otro script.
Esa resiliencia ante el error imprevisto es lo
que está estirando el horizonte temporal.
¡Qué pasada!
Aunque me imagino que seguirán teniendo nuevas carencias,
¿no?
Por supuesto.
Siguen fallando en cosas graves, sobre todo en
la planificación proactiva.
Los modelos tienden a creer que su conocimiento
interno es absoluto.
Si les pides que usen una API nueva,
se ponen a escribir código de memoria.
En vez de leerse las instrucciones.
Exacto.
Solo cuando el sistema les arroja un error
crítico es cuando dicen, ah, voy a consultar
el manual que tengo aquí.
O sea, se lanzan a correr por el
bosque sin mapa y solo miran la brújula
cuando ya están perdidos.
Me encanta esa analogía.
Y es por cómo están diseñados de base.
Son modelos de lenguaje autoregresivos, optimizados para escupir
el siguiente token lo más rápido posible.
Claro, la inmediatez.
Eso es.
Trazar un plan requiere pararse a pensar en
frío, destinar recursos a deliberar antes de actuar.
Y aunque intentan forzar este tiempo de reflexión
en los modelos nuevos, ese sesgo hacia la
acción inmediata les penaliza mucho en tareas de
más de una hora.
Ya a ver, ¿puedo este análisis ocurre en
un laboratorio?
Con instrucciones claras, objetivos súper concretos.
Pero en el mundo real, el trabajo intelectual
es un caos.
Faltan datos, hay prioridades que cambian… Herramientas sin
documentar.
Justo.
¿Cómo responde esta métrica cuando metes las variables
impredecibles de la vida real?
Pues MET midió este factor de caos, el
MESSINES, con 16 variables diferentes.
Y como era de esperar, el rendimiento absoluto
de todos los modelos se desploma cuando la
tarea es caótica.
La ambigüedad sigue siendo su kriptonita.
Pero aquí viene el dato contraintuitivo del estudio,
que me parece fascinante.
Y es que, a pesar de que fallan
más en entornos ambiguos, la tasa de mejora
a lo largo del tiempo es matemáticamente idéntica.
Es alucinante, sí.
Uno pensaría que se estancarían frente al caos
del mundo real, que chocarían contra un muro,
pero la curva de progreso no se aplana
para nada.
¿Por qué mejoran igual de rápido en el
caos que en el laboratorio?
Porque el motor que están mejorando de fondo
es el razonamiento abstracto general.
Si consigues que un modelo mejore un 10%
su capacidad lógica básica, su habilidad para conectar
causa y efecto, esa mejora es como una
marea que levanta todos los barcos a la
vez.
Claro, de sirve para todo.
Exacto.
Eleva su capacidad para resolver un problema matemático
limpio, pero también su habilidad para navegar por
código desordenado.
La brecha entre lo estructurado y lo caótico
sigue ahí, pero todo avanza hacia adelante en
paralelo.
Pues mira, para aterrizar esto, el equipo hizo
un experimento con pull requests reales de sus
propios repositorios de código.
Problemas auténticos, nada de simulaciones.
Sí, la prueba de fuego.
Frentando a tres perfiles, la IA, desarrolladores humanos
subcontratados que eran expertos, y los ingenieros internos
de la propia empresa.
Y los resultados son la mejor radiografía del
sector ahora mismo.
Los ingenieros internos, que conocen toda la arquitectura
del software de memoria, tardaron cinco minutos en
arreglar los bugs.
¿Normal?
¿Tienen todo el contexto?
Claro.
Los desarrolladores expertos subcontratados, que dominan la programación
pero no conocen el proyecto, necesitaron una media
de 81 minutos para entenderlo todo y dar
la misma solución.
¿Y la IA?
¿Sus tiempos se alinearon casi a la perfección
con los humanos subcontratados?
O sea, 81 minutos, lo que decíamos al
principio del episodio.
La IA de hoy equivale funcionalmente al contratista
experto sin contexto.
Exactamente.
Tiene la sintaxis, pero invierte el 90% del
tiempo en entender por qué una variable se
llama así, o cómo interactúan los sistemas viejos.
El cuello de botella no es la inteligencia,
es asimilar el contexto de la empresa.
Y esto nos obliga a mirar al futuro.
Porque, si la barrera es asimilar el contexto
y resulta que la capacidad de operar de
forma autónoma se duplica cada siete meses, el
escenario que plantea METRE es sísmico.
Sí, definen el umbral de lo que llaman
la IA de un mes.
Que son 167 horas laborables.
Imagínate, un sistema capaz de operar solo durante
un mes de jornada completa, absorbiendo la cultura
interna, planificando y ejecutando desarrollos enteros de forma
autónoma.
Es que cruzar ese umbral ya no es
ser un asistente, es ser un agente integral.
Y según la matemática de su gráfica, calculan
que veremos sistemas cruzando este horizonte de un
mes entre finales de 2028 y principios de
2031.
1031.
Es una ventana de tiempo increíblemente estrecha para
un cambio tan masivo, ¿no crees?
Sí, la verdad es que sí.
Pero bueno, aquí me toca hacer de abogado
del diablo.
Porque extrapolar exponenciales en tecnología siempre es peligroso.
Es como la broma de que si extrapolas
el crecimiento de un bebé, a los 30
años mediría 15 metros.
Totalmente.
Hay topes físicos.
Claro.
Llegar a ese horizonte exige una cantidad de
procesamiento y energía que ya roza los límites
de nuestra infraestructura.
Los centros de datos ya no dan abasto
con la red eléctrica.
Igual nos quedamos sin potencia para sostener esa
duplicación de siete meses.
Es el gran límite físico, y los propios
autores lo reconocen como un freno probable.
Pero, y aquí está el giro argumental, hay
un mecanismo interno que podría actuar como acelerador.
La automatización del I más D en IA.
A ver, explícame esto.
A medida que los modelos alcanzan horizontes temporales
de varios días, se vuelven capaces de asumir
el trabajo de los ingenieros que investigan la
propia inteligencia artificial.
Ah, o sea, usar los modelos actuales para
optimizar y crear la siguiente generación.
Eso es.
Un humano tarda meses en diseñar una técnica
para que el entrenamiento gaste un 20% menos
de energía.
Una IA con un horizonte de varios días
podría diseñar y evaluar miles de arquitecturas experimentales
en paralelo.
Encontrar atajos matemáticos que a los humanos se
nos escapan.
Justo, sortéanle el límite físico de la energía,
optimizando al máximo el software.
Se convierten en la herramienta principal para expandir
sus propios cuellos de botella.
Pues si esa retroalimentación ocurre de verdad, la
barrera energética podría ser solo un bache temporal.
Lo que me deja con una reflexión final,
muy provocadora, para que los que nos escuchan
se la lleven a la almohada.
A ver.
Hoy hemos visto que la única ventaja del
ingeniero veterano que resuelve el problema en 5
minutos, frente a la IA que tarda 81
minutos, es el contexto acumulado de la empresa.
La experiencia humana es retener la historia de
cómo funcionan las cosas ahí.
Sí, es lo que nos salva ahora mismo.
Pero, si llegamos a un punto donde una
máquina puede procesar todos los manuales, repositorios y
correos de una década en su ventana de
contexto inicial, en cuestión de segundos, ¿cómo redefiniremos
el valor de la experiencia?
Si el proceso de onboarding de un año
se reduce a tres segundos para la máquina,
la experiencia histórica dejará de ser una ventaja.
Es un cambio tectónico.
Nuestro valor probablemente tendrá que pasar de acumular
contexto a saber qué problemas merecen la pena
ser resueltos, más que cómo resolverlos.
Pero bueno, gracias a este reloj del horizonte
temporal, sabemos cuánto tiempo nos queda para adaptarnos.
Pues ahí queda esa reflexión.
Antes de despedirnos hasta el próximo programa, os
informamos de que las voces que oyes han
sido generadas por la IA de Notebook LM
y que dirigiendo el podcast se encuentra Julio
Pablo Vázquez, un humano que te envía saludos.
En caso de error probablemente sean errores humanos.
Nos escuchamos.
Y hasta aquí el episodio de hoy Muchas
gracias por tu atención Esto es BIMPRAXIS Nos
escuchamos en el próximo episodio ¡Suscríbete al canal!