Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:10
0:15
0:20
0:23
0:26
0:28
0:37
0:39
0:41
0:44
0:46
0:50
0:51
0:52
0:55
0:58
1:02
1:04
1:08
1:10
1:12
1:13
1:15
1:18
1:19
1:21
1:22
1:25
1:27
1:29
1:29
1:32
1:35
1:37
1:38
1:39
1:42
1:44
1:47
1:49
1:51
1:54
1:55
1:55
1:58
2:00
2:01
2:02
2:04
2:06
2:07
2:08
2:10
2:11
2:13
2:14
2:15
2:16
2:19
2:20
2:23
2:25
2:27
2:30
2:30
2:32
2:34
2:36
2:40
2:43
2:46
2:49
2:51
2:52
2:54
2:56
3:00
3:01
3:02
3:05
3:08
3:08
3:11
3:14
3:17
3:19
3:21
3:21
3:23
3:25
3:28
3:31
3:32
3:34
3:36
3:36
3:38
3:40
3:42
3:44
3:46
3:47
3:49
3:51
3:52
3:54
3:56
3:57
4:00
4:02
4:04
4:07
4:08
4:12
4:14
4:18
4:20
4:22
4:23
4:24
4:27
4:29
4:32
4:33
4:36
4:39
4:41
4:42
4:45
4:46
4:48
4:50
4:52
4:53
4:57
4:58
5:01
5:02
5:05
5:05
5:07
5:09
5:10
5:13
5:15
5:18
5:20
5:22
5:22
5:24
5:27
5:27
5:28
5:30
5:31
5:33
5:36
5:38
5:40
5:41
5:41
5:44
5:47
5:51
5:54
5:56
5:59
6:01
6:05
6:06
6:10
6:12
6:15
6:17
6:20
6:21
6:24
6:25
6:26
6:29
6:32
6:35
6:36
6:40
6:42
6:45
6:46
6:49
6:50
6:52
6:54
6:57
7:00
7:01
7:04
7:05
7:07
7:10
7:13
7:14
7:17
7:18
7:19
7:20
7:22
7:23
7:24
7:28
7:29
7:31
7:35
7:36
7:38
7:40
7:42
7:44
7:46
7:48
7:50
7:52
7:53
7:54
7:57
8:00
8:03
8:06
8:08
8:11
8:15
8:17
8:19
8:21
8:22
8:24
8:26
8:28
8:30
8:32
8:34
8:35
8:36
8:38
8:39
8:42
8:44
8:45
8:48
8:49
8:50
8:51
8:53
8:55
8:56
8:57
8:59
9:01
9:03
9:05
9:07
9:08
9:09
9:11
9:14
9:18
9:20
9:22
9:22
9:24
9:27
9:29
9:34
9:35
9:37
9:39
9:40
9:41
9:43
9:44
9:49
9:51
9:53
9:55
9:57
9:59
10:02
10:03
10:06
10:10
10:12
10:13
10:15
10:17
10:19
10:20
10:23
10:24
10:27
10:27
10:31
10:35
10:37
10:38
10:40
10:41
10:44
10:45
10:47
10:50
10:51
10:54
10:56
10:58
11:01
11:02
11:05
11:07
11:08
11:09
11:12
11:14
11:16
11:18
11:20
11:21
11:23
11:24
11:26
11:28
11:31
11:33
11:34
11:36
11:38
11:40
11:41
11:44
11:46
11:49
11:52
11:53
11:56
11:59
12:01
12:03
12:04
12:07
12:08
12:10
12:13
12:15
12:17
12:20
12:22
12:23
12:26
12:27
12:28
12:31
12:32
12:33
12:35
12:36
12:38
12:40
12:43
12:46
12:48
12:49
12:53
12:55
12:56
12:59
13:02
13:05
13:08
13:09
13:12
13:13
13:16
13:19
13:20
13:24
13:26
13:28
13:32
13:35
13:37
13:39
13:43
13:46
13:48
13:50
13:51
13:55
13:58
14:01
14:02
14:03
14:05
14:08
14:09
14:13
14:15
14:17
14:19
14:22
14:23
14:26
14:28
14:29
14:31
14:34
14:37
14:39
14:41
14:41
14:44
14:45
14:47
14:49
14:49
14:51
14:54
14:56
14:57
14:59
15:01
15:04
15:06
15:08
15:09
15:12
15:14
15:14
15:17
15:19
15:21
15:23
15:26
15:29
15:31
15:33
15:35
15:37
15:40
15:41
15:45
15:48
15:51
16:05
16:08
16:21
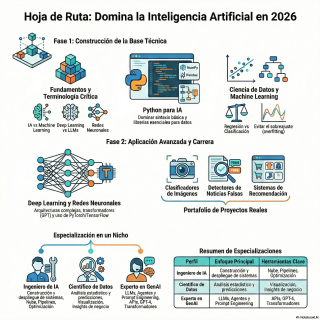
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas y bienvenidos.
Hoy nos vamos a sumergir en algo que
yo creo muchos tienen en mente.
¿Cómo se aprende de verdad sobre inteligencia artificial
en, bueno, ya en 2024?
Es la pregunta del millón.
Totalmente.
Tenemos sobre la mesa una hoja de ruta,
un plan muy completo de siete pasos, que
promete, oye, guiar a cualquiera desde cero hasta,
quién sabe, una especialización.
Nuestra misión hoy es desgranarlo, analizarlo a fondo
y ver si de verdad es un mapa
útil o si, bueno, se queda en una
lista de buenas intenciones.
Porque, a ver, en un campo que cambia
cada semana, ¿de verdad puede existir una guía
definitiva?
Es que esa es la cuestión clave, sin
duda.
Porque meterse en IA ahora mismo es como
intentar beber de una boca de incendios.
Vaya imagen.
Es que es así.
Hay un tsunami de información, de cursos, de
herramientas, de acrónimos.
Es facilísimo sentirse abrumado y no saber por
dónde empezar.
Ya, por eso.
Lo que me parece interesante de la filosofía
de este plan es que no te lanza
a lo último, a lo más brillante.
Insiste en algo casi olvidado.
Construir unos cimientos sólidos.
Empezar la casa por los conocimientos, no por
el tejado.
Exacto.
Es una idea que veremos repetirse y yo
creo que es el único antídoto real contra
la frustración.
Vale, me gusta esa idea.
Y el plan arranca, como es lógico, con
el paso uno, entender lo básico.
Claro.
El argumento es ese.
Hay que familiarizarse con el vocabulario.
¿Qué es IA?
¿Qué es Machine Learning?
Redes neuronales.
IA generativa.
Agéntica I.
Bueno, los omnipresentes LLMs.
Y lo bueno es que lo hace con
ejemplos muy aterrizados, que se agradece.
En lugar de soltarte una definición de libro,
te dice, a ver, la IA general es
como enseñar a un niño a reconocer animales.
Vale.
Y el machine learning en concreto es como
aprender a montar en bici.
O sea, no te estudias las leyes de
la física, simplemente practicas, te caes, te ajustas
y tu cerebro aprende de la experiencia.
Claro, separa el concepto de la técnica y
una vez entiendes los términos, de repente empiezas
a verlos por todas partes.
Totalmente.
El plan insiste mucho en eso, en conectar
la teoría con el día a día, el
desbloqueo facial del móvil, las recomendaciones de Spotify,
Google Translate.
Exacto.
De repente, esa capa de magia se disueve
un poco y entiendes mejor el mundo en
el que vives.
Y lo fascinante aquí no es sólo acumular
definiciones, es dejar de ser esa persona que
suelta red neuronal en una conversación para parecer
interesante.
Pero que luego no sabe explicarlo.
Justo.
Y se queda en blanco si le piden
que lo explique, aunque sea por encima.
Comprender estos fundamentos te da un mapa mental.
Te permite situar cada noticia, cada herramienta, en
su sitio.
El mundo no sólo cobra más sentido, sino
que se vuelve menos intimidante.
Vale.
Tenemos el mapa mental.
El plan nos lleva al Paso 2.
Aprender a programar con Python.
Lo llama el pinzal del pintor de la
IA.
Pero lanza un mensaje que me parece crucial,
muy tranquilizador.
No hace falta ser un genio de la
programación.
Basta con dominar lo fundamental.
Variables, bucles, funciones.
Es que la idea es esa.
No necesitas saber fabricar un pincel desde cero,
ni entender la química de los pigmentos.
Solo saber sujetarlo.
Solo saber cómo sujetarlo y cómo mezclar los
colores básicos.
Y para eso el plan menciona las librerías
que son como superpoderes.
NumPy para matemáticas y Pandas, que describe genialmente
como Excel con esteroides.
Excel con esteroides, me la quedo.
Es buenísima.
Es que es eso.
Para manipular y analizar datos a lo bestia.
Pero la clave, según el plan, no es
la intensidad, es la constancia.
Cito.
Programar cada día, aunque solo sean 30 minutos.
Y eso conecta con algo fundamental, la mentalidad
de un profesional.
El plan lo dice claro.
Los desarrolladores de verdad buscan cosas en Google
todo el tiempo.
Nadie lo sabe todo de memoria.
O sea que lo importante es entender la
lógica y saber qué es posible.
Exacto.
No memorizar, sino saber qué herramienta usar para
cada tarea.
Y eso nos lleva directos al paso 3,
Machine Learning.
Aquí es donde, según esto, la cosa se
pone seria.
Ahora sí.
Dejamos de ser espectadores y empezamos a ser
creadores.
Se introducen los dos grandes paradigmas.
El supervisado, que es como ser un profesor
con datos etiquetados, y el no supervisado, donde
dejas que el modelo explore por su cuenta
para encontrar patrones.
Justo.
Y los ejemplos son muy claros, ¿no?
Regresión lineal para predecir el precio de una
casa.
Supervisado.
Clasificación para saber si un correo es spam.
También supervisado.
Y luego el clustering, que es lo que
hace Netflix para agruparnos por gustos sin saber
de antemano qué tribus de cinéfilos hay.
Que eso es no supervisado.
Perfecto.
Vale.
Entiendo la idea de aprender con ejemplos.
Pero suena casi demasiado fácil.
¿Qué impide que el modelo simplemente se memorice
las respuestas como un mal estudiante y luego
no sepa qué hacer con una pregunta nueva?
Acabas de poner el dedo en la llaga.
Has tocado uno de los mayores desafíos del
machine learning, el overfitting o sobreajuste.
Ahí está el lío.
Aquí es donde se pone de verdad interesante.
El plan lo explica con esa misma analogía.
El estudiante que se memoriza el libro.
Saca un 10 y las preguntas son idénticas.
Pero si le cambias una coma, se desmorona.
Se desmorona.
Pues un modelo sobreajustado es igual.
Funciona perfecto con los datos que ya ha
visto.
pero fracasa estrepitosamente con datos nuevos del mundo
real, que es para lo que lo queremos.
Entonces, ¿cómo evitas que el modelo haga trampas?
¿Cuál es la solución?
Pues la principal estrategia es dividir los datos.
O sea, le escondes una parte, el conjunto
de prueba, y no se la enseñas mientras
entrena.
Como guardar preguntas secretas para el examen final.
Exacto.
Y solo cuando el modelo está entrenado, le
pasas esa prueba, para ver si de verdad
ha aprendido o si solo ha memorizado.
Además, el plan insiste en no fiarse de
una sola métrica.
El ejemplo del detector de spam es brillante.
A ver.
Un modelo que clasifica el 100% de los
correos como no spam tendría una precisión altísima,
del 99%, si solo el 1% del correo
es malo.
Pero sería completamente inútil.
Claro, porque no detectaría ninguno de los que
importan.
Exacto.
Hay que usar métricas que entiendan el contexto
del problema.
Entendido.
Así que el Machine Learning tradicional es enseñar
con ejemplos claros.
Pero, ¿qué pasa cuando los problemas son tan
complejos como reconocer una cara o entender el
sarcasmo?
Que ni un humano podría escribir las reglas.
Ahí necesitamos algo más potente, ¿no?
Y eso nos lleva al Deep Learning.
Exactamente.
El paso 4, Deep Learning y redes neuronales.
Es la evolución natural.
La analogía del plan es pasar de la
aritmética básica al cálculo.
Vaya salto.
Es que lo es.
Son arquitecturas de modelos inspiradas muy libremente en
el cerebro, con muchísimas capas que permiten aprender
patrones increíblemente complejos.
Es la tecnología detrás del reconocimiento facial, la
traducción, los coches autónomos.
Aquí es donde aparecen nombres como CNN para
imágenes y los Transformers para el lenguaje, que
son la arquitectura de ChatGPT.
Esos mismos.
Espera, lo de los Transformers siempre me ha
fascinado.
El plan pone una frase de ejemplo.
El animal no cruzó la calle porque estaba
demasiado cansado.
Y dice que un Transformer sabe que estaba,
se refiere al animal, y no a la
calle.
Ajá.
Esto me acaba de hacer clic.
O sea, no es que la IA entienda
como nosotros.
Es que es increíblemente buena calculando las probabilidades
de qué palabra se relaciona con cuál.
Has dado en el clavo.
Es pura estadística imitando la intuición.
Fascinante.
Y un poco inquietante, ¿no?
Un poco.
Y el metanismo por el que prenden se
llama back propagation.
La analogía que usan es la de un
arquero.
La red hace una predicción, ve lo lejos
que ha quedado de la diana, y usa
ese error para ajustar un poquito todos sus
parámetros hacia atrás, capa por capa.
Para que la siguiente flecha vaya un poco
mejor.
Justo.
Ahora imagina repetir eso millones de veces.
Y para no volvernos locos, el plan menciona
herramientas como PyTorch y TensorFlow, que son como
kits de construcción de Lego.
Te dan los bloques ya hechos.
Exacto.
Para que tú te centres en diseñar el
castillo, no en fabricar cada ladrillo.
Bien, ya tenemos la base teórica.
Conceptos, Python, ML, DL… Pero la fuente insiste
en algo que es de sentido común, pero
que a menudo se olvida.
Toda la teoría no sirve de nada si
no construyes algo real.
Amén.
Y con esto entramos en la segunda mitad
del viaje que va de la teoría a
la práctica, empezando con el paso 5, proyectos.
Este paso es para mí el más importante.
Es la diferencia entre saberse los acordes y
poder tocar una canción delante de gente.
Es donde se solidifica todo.
Totalmente.
Y el plan sugiere empezar con proyectos clásicos,
pero que enseñan mucho.
Un clasificador de perros y gatos, un analizador
de sentimiento, un detector de noticias falsas.
Suena asequible, pero te obliga a ensuciarte las
manos.
Y ahí está la clave.
Lo que te enseñan los proyectos es lo
que no te enseñan los cursos.
Te lo digo por experiencia.
Mi primer proyecto fue un clasificador de sentimiento.
Y los datos.
Los datos del mundo real eran un desastre.
¿Ah, sí?
Abreviaturas, sarcasmo, erratas, emojis.
Pasé el 80% del tiempo limpiando datos.
Es la parte menos glamurosa y sin duda
la más importante.
Ningún curso te prepara para ese caos.
Claro.
Aprendes a depurar, a ser paciente y a
persistir.
Por eso el consejo del plan es oro.
Documenta todo en un portafolio, en GitHub o
en un blog.
Es tu prueba de que sabes hacer cosas,
no solo de que sabes teoría.
Y de construir tus cosas, pasamos a usar
las herramientas más potentes del momento.
Paso 6.
Herramientas de IA generativa y LLMs.
La vanguardia.
Aquí nos metemos ya en lo que está
en boca de todos.
Chat GPT, mi journey runway.
Y se enfoca en dos conceptos clave, embeddings
y prompt engineering.
Los embeddings son, en esencia, la forma que
tiene la IA de convertir el significado en
matemáticas.
Cada concepto es un vector, una lista de
números.
Y lo alucinante es que conceptos cercanos tienen
vectores matemáticamente cercanos.
Es lo que permite entender que rey es
a reina, lo que hombre es a.
A mujer.
Es pura matemática relacional.
Y el prompt engineering es lo que el
plan llama el arte de hablar con la
IA.
Y el ejemplo que da es buenísimo.
No es lo mismo pedir, háblame de historia,
que explica la caída del imperio romano para
un niño de 10 años, centrándote en los
factores económicos.
Claro, es que la diferencia es abismal.
La especificidad, el contexto, el rol que le
pides que asuma.
todo eso cambia radicalmente la calidad de la
respuesta.
Se convierte en una habilidad en sí misma.
¿Totalmente?
Y lo bueno es que cualquiera puede integrar
esto en sus propias apps con las APIs.
Pero la lección más profunda de este paso
es que no basta con ser un usuario.
Para sacarles partido de verdad, tienes que entender,
aunque sea a nivel conceptual, qué hacen por
debajo.
Y con todo este bagaje, llegamos al final
del camino.
Paso 7.
Especialización y portafolio.
Aquí el plan suelta una verdad un poco
dura.
Ser un aprendiz de todo te convierte en
un maestro de nada.
Es que el campo es demasiado vasto.
Es imposible abarcarlo todo.
Por eso sugiere tres grandes trayectorias.
La primera, ingeniero de IAML.
El perfil que construye y mantiene los sistemas
en producción.
Su obsesión es la escalabilidad, la fiabilidad.
Son los arquitectos de las tuberías por las
que fluyen los datos.
Luego está el científico de datos, este perfil
está más cerca del negocio, ¿no?
Sí, combina análisis con lo cimiento del sector
y machine learning para extraer insights para responder
preguntas.
Son los traductores entre los datos y las
decisiones estratégicas.
Y la tercera, la más nueva, es el
experto en IA generativa.
Ese es quien trabaja en la cresta de
la ola con LLMs, modelos de difusión, agentes,
construyendo lo último.
Pero, ojo, no son cajas cerradas.
Claro, un buen ingeniero necesita entender los datos.
Y un científico de datos se beneficia de
saber poner un modelo en producción.
La diferencia está en el enfoque.
Disfrutas más construyendo la infraestructura o extrayendo la
historia que cuentan los datos.
Entonces, la gran pregunta.
¿Cómo elegir un camino?
¿Qué consejo da el plan?
El consejo es simple y, creo, muy profundo.
Sigue tu curiosidad genuina.
La IA evoluciona a una velocidad de vértigo.
Si no te apasiona tu pequeña parcela, te
vas a quemar.
En cambio, si te fascina la generación de
imágenes, aprender sobre nuevas arquitecturas no te parecerá
trabajo, te parecerá un juego.
Y una vez eliges, tu portafolio debe reflejarlo.
Debe ser el reflejo de esa especialización.
Si quieres ser un experto en procesamiento del
lenguaje natural, tu GitHub debe estar lleno de
proyectos de chatbots, análisis de sentimiento.
Tu portafolio es tu credibilidad.
Entonces, si miramos atrás, hemos recorrido un viaje
completo.
Empezamos con los conceptos.
Aprendimos el lenguaje con Python.
Nos adentramos en Machine Learning y Deep Learning.
Y luego pasamos a la acción con proyectos,
para finalmente encontrar nuestro sitio.
El mapa va desde un simple ¿qué es
la IA?
hasta un contundente este es mi portafolio como
especialista.
Y el plan concluye con unas reflexiones muy
honestas, muy necesarias.
Sí.
Primero, que esto no es un sprint de
30 días, es una maratón que requiere constancia.
Segundo, que sentirse abrumado es la norma.
Nadie lo sabe todo.
Eso libera mucha presión.
Y tercero, y para mí esta es la
idea más potente de todas, no necesitas saberlo
todo para empezar a crear valor.
Solo necesitas saber lo suficiente para resolver el
problema que tienes delante.
El aprendizaje real viene de ahí, de resolver
problemas concretos.
Exacto.
Es un mensaje muy poderoso, la verdad, y
ver a esa presión de tener que ser
un experto antes de empezar.
El plan termina con la predicción de que,
en pocos años, la alfabetización en IA será
tan fundamental como lo es hoy la informática.
Lo cual nos deja con una última reflexión
para quien nos escucha.
Teniendo esta hoja de ruta, que parece bastante
coherente y accionable, cuál podría ser el primero
y más pequeño paso a dar hoy mismo
para empezar este viaje.
Y quizás más importante, qué proyecto personal, por
muy simple que sea, analizar tus gastos, crear
un recomendador de libros, generar imágenes, despertaría esa
curiosidad inicial para ponerse en marcha.
Y hasta aquí el episodio de hoy Muchas
gracias por tu atención Esto es BIMPRAXIS Nos
escuchamos en el próximo episodio ¡Suscríbete al canal!