Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:10
0:15
0:20
0:23
0:26
0:28
0:37
0:38
0:41
0:42
0:43
0:46
0:47
0:48
0:50
0:53
0:55
0:57
0:59
1:02
1:04
1:07
1:10
1:11
1:13
1:14
1:14
1:16
1:19
1:22
1:23
1:25
1:26
1:28
1:30
1:31
1:34
1:36
1:37
1:39
1:41
1:43
1:47
1:48
1:50
1:52
1:54
1:57
1:59
2:00
2:02
2:04
2:06
2:09
2:10
2:12
2:13
2:16
2:18
2:19
2:20
2:24
2:26
2:26
2:27
2:29
2:31
2:34
2:38
2:41
2:42
2:46
2:49
2:50
2:51
2:53
2:54
2:57
2:58
3:00
3:02
3:04
3:07
3:08
3:10
3:12
3:15
3:18
3:20
3:22
3:24
3:25
3:26
3:29
3:32
3:34
3:37
3:38
3:40
3:41
3:43
3:46
3:48
3:50
3:51
3:53
3:54
3:56
3:57
4:00
4:01
4:03
4:04
4:07
4:11
4:14
4:16
4:19
4:21
4:23
4:25
4:27
4:28
4:30
4:32
4:32
4:35
4:38
4:40
4:41
4:42
4:45
4:47
4:48
4:50
4:51
4:54
4:55
4:56
4:58
5:00
5:02
5:04
5:05
5:06
5:08
5:10
5:12
5:14
5:15
5:17
5:20
5:23
5:25
5:25
5:27
5:30
5:32
5:33
5:36
5:39
5:43
5:44
5:46
5:49
5:50
5:52
5:54
5:58
6:01
6:03
6:05
6:08
6:10
6:11
6:14
6:15
6:16
6:19
6:21
6:24
6:25
6:28
6:30
6:30
6:32
6:35
6:36
6:37
6:39
6:41
6:42
6:43
6:46
6:49
6:51
6:54
6:56
6:57
6:59
7:00
7:04
7:05
7:07
7:09
7:12
7:15
7:16
7:18
7:21
7:23
7:24
7:25
7:29
7:32
7:33
7:35
7:37
7:40
7:42
7:43
7:46
7:48
7:51
7:51
7:53
7:57
7:59
8:00
8:02
8:04
8:05
8:08
8:10
8:12
8:13
8:17
8:18
8:20
8:22
8:23
8:26
8:28
8:32
8:33
8:35
8:38
8:39
8:42
8:44
8:45
8:47
8:50
8:52
8:54
8:56
8:57
8:58
8:59
8:59
9:01
9:03
9:05
9:06
9:08
9:09
9:12
9:13
9:14
9:16
9:18
9:19
9:21
9:24
9:27
9:29
9:32
9:35
9:37
9:40
9:41
9:43
9:45
9:46
9:48
9:49
9:50
9:53
9:54
9:54
9:55
9:57
9:58
10:00
10:00
10:03
10:05
10:08
10:11
10:12
10:12
10:16
10:18
10:20
10:22
10:24
10:27
10:28
10:29
10:31
10:33
10:35
10:36
10:37
10:39
10:42
10:44
10:46
10:47
10:50
10:51
10:56
10:58
11:00
11:02
11:05
11:06
11:07
11:08
11:10
11:13
11:15
11:18
11:19
11:20
11:23
11:27
11:28
11:30
11:34
11:35
11:38
11:40
11:43
11:46
11:49
11:51
11:54
11:57
11:57
12:01
12:04
12:06
12:06
12:09
12:10
12:13
12:17
12:18
12:20
12:20
12:21
12:24
12:26
12:27
12:28
12:31
12:33
12:35
12:37
12:41
12:45
12:46
12:48
12:51
12:54
12:57
12:59
13:01
13:02
13:16
13:18
13:30
13:32
13:56
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas.
Pues hoy seguimos explorando el mundo de los
RAG, que la verdad es que da para
mucho.
Sí, ya llevamos unos cuantos programas y parece
que no se acaba el tema.
Para nada.
Y hoy traemos un caso de uso que
a mí me parece, bueno, espectacular.
La idea de montar tu propio Google Personal
para todos tus documentos.
Un buscador para tu caos digital.
Exacto, para ese cementerio de información que tenemos
todos en el ordenador.
Carpetas llenas de PDFs, de documentos de Word,
notas… Y que cuando buscas algo no encuentras
nada.
O bueno, encuentras el nombre del archivo y
poco más.
Justo.
Por eso nos vamos a sumergir en un
sistema que desglosa el desarrollador Colemedin y que
se apoya en una tecnología de IBM Research
que se llama DocLink.
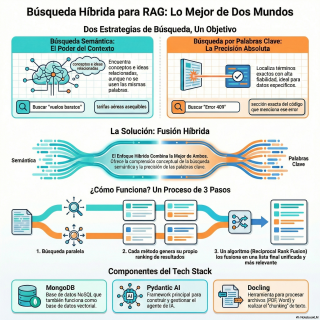
Y lo interesante es que el enfoque combina
dos mundos.
Por un lado, la búsqueda de toda la
vida, la de palabras clave.
La que ya conocemos.
Y por otro, la búsqueda semántica, que es
la que de verdad entiende el significado de
las cosas.
No solo encuentra el documento, sino que extrae
el conocimiento.
Vale, a ver, vamos a desgranar esto.
Búsqueda por palabras clave y búsqueda semántica.
A mí de primeras me suena un poco
a lo viejo contra lo nuevo.
Sí, parece eso.
Si la semántica es, se supone, mucho más
inteligente, ¿por qué nos molestamos en usar la
búsqueda de palabras de toda la vida?
¿No es un poco arcaico?
Es una pregunta muy lógica, porque la semántica
parece superior en todo.
Pero la búsqueda por palabras clave tiene una
superpotencia que es insustituible.
¿Cuál?
La precisión quirúrgica.
Hay momentos en los que no quieres que
el sistema interprete nada, quieres que encuentre una
cadena de texto exacta y punto.
Dame un ejemplo.
Pues piensa en algo legal.
Si buscas un estatuto, el artículo 15.3b, no
quieres que te dé el 15.3c porque se
parece.
Claro.
O un código de error, un 409.
O, como dice Cole Medín en el vídeo,
si buscas los ingresos de 2025, la búsqueda
semántica podría liarse y dártelos de 2024 o
2026, porque conceptualmente están cerca.
Ya entiendo.
Es la diferencia entre podrá y deberá.
Semánticamente se parecen, pero legalmente son la noche
y el día.
Exacto.
Ahí necesitas un bisturí, no una red de
pesca.
Y tiene otra pequeña ventaja, el fussy matching,
que te encuentra la palabra aunque haya un
pequeño error al teclear.
Vale, acepto la utilidad del bisturí.
Visto así, tiene todo el sentido.
Pero ahora háblame de la magia, de la
búsqueda semántica.
¿Qué es lo que la hace tan potente?
Pues aquí es donde damos el salto de
buscar palabras a buscar significados.
La búsqueda semántica o vectorial no se fija
en si las palabras coinciden, se fija en
si las ideas están relacionadas.
El ejemplo clásico de esto es el de
rey y reina, ¿no?
Ese es.
Buscas rey y te puede devolver documentos que
hablan de reina o de monarquía porque entiende
el concepto global de realeza.
¿Que eso ya es un salto cualitativo muy
importante?
Es un cambio de paradigma.
Otro ejemplo.
Buscas PC lento y el sistema te encuentra
un artículo que se titula ¿Cómo optimizar el
rendimiento de tu ordenador?
Aunque no ponga ni PC ni lento.
Exacto.
una búsqueda por palabra clave ahí se quedaría
en blanco.
En el vídeo de Medin pasa algo así,
de hecho.
Él pregunta por un cronograma o timeline del
lanzamiento de un producto.
Y el documento no tiene esa palabra.
No la tiene.
Pero tiene un plan de lanzamiento, un launch
plan, con fechas, y el sistema lo encuentra.
Esa conexión, esa es la verdadera inteligencia.
Ese es el núcleo de su poder.
Infiere tu intención y la conecta con el
significado del contenido.
Y por eso, la respuesta a tu pregunta
de antes de por qué no usar solo
la semántica, es que ninguna de las dos
es perfecta.
Claro, una se puede equivocar en los detalles
y la otra no entiende el contexto.
Justo.
Por eso la solución real, la que se
propone aquí, es un sistema híbrido.
Lanzas cada pregunta por las dos vías a
la vez.
Ah, claro.
Así tienes la precisión para los datos específicos
y la inteligencia para las ideas.
No se te escapa nada.
Consigues lo mejor de ambos mundos en cada
consulta.
Vale, la estrategia es brillante, lo veo.
Pero una cosa es la idea y otra
montarla.
¿Qué piezas hacen falta?
¿Cuál es el tech stack de todo esto?
Pues la base de todo es MongoDB.
Funciona como el gran almacén, pero no es
un almacén tonto, ¿eh?
¿En qué sentido?
En que está diseñado para hacer justo las
dos cosas que necesitamos.
Por un lado, es una base de datos
vectorial, que es el motor de la búsqueda
semántica.
Y por otro, tiene una búsqueda de texto
tradicional muy potente para las palabras clave.
O sea, es el contenedor que permite que
los dos mundos convivan.
Exacto.
Es como un bibliotecario que sabe organizar por
temas y a la vez encontrarte una frase
exacta en la página que le pidas.
Y luego está la otra pieza que me
llama mucho la atención, DocLink.
Que venga de IBM Research y esté en
la LFAI and Data Foundation, bueno, eso le
da mucho peso.
Totalmente.
Si MongoDB es el almacén, DocLink es el
equipo de catalogación.
Es el que coge nuestros documentos en bruto
y los convierte en algo inteligente.
¿Y te soluciona el problema del cajón desastre?
Sí, puedes echarle PDFs, facturas, actas en Word,
presentaciones… ¿Incluso audios?
Incluso audios.
Coge archivos WAV o MP3, aplica reconocimiento de
voz, extrae el texto y ya puedes buscar
en él.
Y con los PDFs hace virguerías.
No solo copia el texto.
¿Qué más hace?
Pues entiende la maquetación, el orden de lectura,
la estructura de las tablas, las fórmulas.
Extrae el conocimiento de forma estructurada.
Que eso es clave.
Cualquiera que haya intentado copiar una tabla de
un PDF sabe el desastre que puede ser.
Exacto.
Pero quizás su función más crítica para este
sistema, RAG, es el chunking.
El troceado de los documentos.
Eso es.
Los modelos de lenguaje no pueden leerse un
manual de 300 páginas de golpe.
Se ahogan en información.
Se pierden, claro.
Pues DocLink lo que hace es dividir esos
documentos en fragmentos, en chunks coherentes.
Y usa una estrategia híbrida muy buena para
que esos trozos tengan sentido por sí mismos.
Es como darle al modelo resúmenes de cada
capítulo.
Sin un buen chunking, el sistema se viene
abajo.
Vale, entonces tenemos Almacén, MongoDB, y el preparador,
DocLink.
Falta el cerebro que dirige todo.
Ahí entra Paidanti Keyai, ¿no?
Sí, Paidanti Keyai sería el director de orquesta.
Es un framework que simplifica mucho la construcción
de estos agentes.
Recibe tu pregunta y decide.
Vale, para esto lanzo una búsqueda semántica y
una por palabra clave a MongoDB.
Te da los bloques para que la gente
razone y actúe.
De acuerdo, el tech stack tiene sentido.
MongoDB almacela y busca, DocLink prepara y trocea
todo.
Pero ahora me surge una duda que me
parece fundamental.
Si lanzamos dos búsquedas a la vez, sacamos
dos listas de resultados.
¿Cómo las juntamos?
¿Cómo sabes qué resultado es más importante?
Es el problema del millón, sí.
Y es que no puedes simplemente mezclarlos.
¿Por qué no?
Porque cada búsqueda mide la calidad de sus
resultados con una vara de medir completamente distinta.
La búsqueda semántica te da una puntuación, digamos,
entre 0 y 1.
Te dice, esto se parece a tu pregunta,
en un 0.85.
¿Y la de palabra clave te da?
Otro número, sí, pero basado en otras cosas,
como la frecuencia de la palabra.
Podría ser un 15 un 32.
No tienen relación.
Comparar un 0,85 con un 15 es comparar
peras con manzanas.
Imposible saber qué es mejor.
Si los intentas mezclar a la fuerza, el
resultado es malísimo.
Entonces, ¿cómo se soluciona este lío?
Con un algoritmo muy, muy elegante que se
llama Reciprocal Rank Fusion o RRF.
A ver.
La idea es brillante porque ignora por completo
esas puntuaciones que no podemos comparar.
En su lugar se fija en algo que
sí es comparable, la posición en el ranking
de cada resultado.
Explícame eso un poco mejor.
Imagina que buscas un restaurante.
Una app de reseñas, la semántica, te da
1 con 4,8 estrellas.
Otra app de popularidad, la de palabra clave,
te dice que es el número 15 más
visitado.
¿Qué es mejor?
Ni idea.
Exacto.
Pero si las dos apps lo ponen en
su top 3, entonces sabes que es una
apuesta segura.
RRF hace eso.
Confía en el consenso.
Le da más peso a los resultados que
aparecen arriba en ambas listas sin importar sus
puntuaciones raras.
Ah, qué bueno.
O sea, que se fía de los resultados
en los que los dos métodos están de
acuerdo.
Es una forma de encontrar un consenso entre
dos expertos que hablan idiomas distintos.
Es una solución súper robusta.
Fíjate si es efectiva, que el propio Cole
Medin menciona que MongoDB está trabajando para integrar
RRF directamente en su plataforma.
Eso te da una idea de su importancia.
Vale, creo que ya tengo todas las piezas.
Pongámoslo todo junto.
Vamos a seguir el viaje de una pregunta
desde que la hago hasta que me llega
la respuesta.
¿Qué pasa por detrás?
Perfecto.
Empezamos con tu pregunta.
¿Cuál es el cronograma para el lanzamiento del
nuevo producto?
Hecho.
Pregunta lanzada.
En ese mismo instante, el agente entra en
acción.
Lanza la consulta por dos caminos a la
vez.
Dos tuberías en paralelo hacia MongoDB.
Una semántica y otra de palabra clave.
Y cada tubería me devolverá una lista de
chunks, de trocitos de texto, ordenada según su
propio criterio.
Correcto.
Pero antes de fusionarlas, pasa algo crucial.
El enriquecimiento.
El sistema no solo recupera los fragmentos, sino
que va al documento original y les añade
los metadatos.
El nombre del archivo, la fecha, el autor...
El número de página.
Todo.
Y por eso es posible hacer la pregunta
de seguimiento del vídeo.
Cuando el usuario pregunta ¿de dónde has sacado
esa información?
Claro.
Y el sistema responde de las notas de
la reunión del 8 de enero, página 3.
Eso es gracias a los metadatos.
Sin ellos estaría perdido.
Exacto.
Solo tendrías texto anónimo, sin fuente ni contexto.
Y una vez que tienes las dos listas
enriquecidas y ordenadas, llega la fusión con RRF.
El algoritmo mira los rankings.
Y crea una única lista final, unificada y
ordenada por la relevancia combinada.
Y esa lista final ya depurada es el
material de primera que se le entrega al
modelo de lenguaje.
Justo.
Se le pasa esa lista de los fragmentos
más pertinentes y se le dice, con esto
y solo con esto genera una respuesta coherente
y el modelo redacta la respuesta para la
usuaria.
Y lo más alucinante es que en la
demo todo este viaje, las dos búsquedas, el
enriquecimiento, la fusión, la generación, ocurre en menos
de un segundo.
Es que la arquitectura está muy bien diseñada
y plataformas como MongoDB están súper optimizadas para
esto.
Entonces, resumiendo, la clave es esta estrategia híbrida
que une la precisión de la vieja escuela
con la inteligencia de lo nuevo.
Necesitamos herramientas como DocLink para preparar bien los
datos y un método como RFRF para fusionar
los resultados de forma elegante.
Hemos construido nuestro buscador personal.
Pero, me pregunto, ¿y si esto es solo
el principio?
Es que esto plantea una pregunta muy importante.
Todo este sistema que hemos descrito es reactivo.
Le pregunto, me contesta.
Exacto.
Lo usamos para tirar de la información que
necesitamos.
Pero, ¿y si la gente pudiera empujar la
información hacia nosotros, de forma proactiva?
¿A qué te refieres?
¿Que me dé respuestas a preguntas que no
he hecho?
Algo así.
Imagina una gente que no solo busca, sino
que lee y conecta tus notas por sí
mismo.
Que coge las notas de la reunión de
esta mañana, las cruza con un informe de
ventas de la semana pasada y te dice,
oye, he detectado una inconsistencia en las proyecciones
de ventas del producto X.
Ostras, estaríamos pasando de un buscador a un
asistente de conocimiento, casi un socio estratégico.
Exactamente.
Estaríamos dando el salto de la búsqueda de
información a la síntesis de conocimiento.
El sistema no sólo encontraría datos, sino que
generaría nuevos insights, nuevas ideas.
Que te hiciera un resumen de los puntos
clave de un proyecto cada mañana sin que
se lo pidas.
Ese, sin duda, es el siguiente horizonte.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.
SUSCRÍBETE 🙏