Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:10
0:15
0:20
0:23
0:26
0:28
0:37
0:39
0:43
0:45
0:49
0:53
0:55
0:59
1:01
1:04
1:06
1:08
1:11
1:13
1:15
1:17
1:19
1:21
1:24
1:26
1:29
1:31
1:33
1:34
1:35
1:36
1:39
1:40
1:43
1:44
1:47
1:48
1:49
1:52
1:54
1:56
1:58
1:59
2:00
2:02
2:04
2:07
2:07
2:10
2:10
2:13
2:14
2:16
2:17
2:19
2:22
2:25
2:26
2:28
2:31
2:33
2:34
2:34
2:37
2:38
2:42
2:45
2:48
2:50
2:52
2:53
2:54
2:56
2:58
3:00
3:02
3:03
3:05
3:06
3:07
3:11
3:14
3:17
3:20
3:21
3:23
3:24
3:27
3:28
3:30
3:30
3:32
3:34
3:37
3:41
3:43
3:45
3:47
3:49
3:53
3:54
3:55
3:58
3:59
4:01
4:03
4:04
4:05
4:08
4:11
4:13
4:15
4:17
4:17
4:19
4:22
4:25
4:26
4:27
4:29
4:30
4:32
4:33
4:34
4:34
4:37
4:40
4:41
4:43
4:45
4:47
4:49
4:50
4:53
4:56
4:58
5:00
5:02
5:05
5:08
5:09
5:11
5:12
5:15
5:17
5:18
5:20
5:24
5:25
5:26
5:29
5:32
5:33
5:35
5:38
5:41
5:43
5:47
5:48
5:51
5:54
5:55
5:57
5:59
6:02
6:05
6:07
6:09
6:10
6:13
6:14
6:16
6:17
6:21
6:24
6:26
6:28
6:30
6:33
6:35
6:36
6:38
6:39
6:40
6:42
6:44
6:46
6:48
6:52
6:55
6:56
6:59
7:01
7:03
7:06
7:07
7:10
7:12
7:16
7:19
7:20
7:23
7:25
7:28
7:30
7:32
7:34
7:36
7:37
7:41
7:43
7:46
7:50
7:51
7:52
7:53
7:58
8:00
8:04
8:05
8:07
8:09
8:12
8:16
8:18
8:19
8:21
8:23
8:26
8:29
8:31
8:33
8:34
8:37
8:40
8:43
8:45
8:48
8:49
8:50
8:53
8:54
8:56
8:59
9:01
9:03
9:06
9:07
9:09
9:11
9:13
9:14
9:18
9:20
9:23
9:27
9:27
9:28
9:31
9:37
9:38
9:40
9:41
9:43
9:45
9:48
9:50
9:52
9:54
9:57
9:58
10:00
10:02
10:03
10:05
10:07
10:09
10:11
10:11
10:13
10:16
10:18
10:19
10:21
10:24
10:26
10:27
10:31
10:32
10:33
10:36
10:39
10:42
10:45
10:48
10:50
10:51
10:53
10:55
10:58
11:01
11:03
11:04
11:06
11:08
11:10
11:12
11:15
11:17
11:18
11:19
11:21
11:25
11:27
11:29
11:31
11:33
11:33
11:36
11:37
11:40
11:44
11:46
11:49
11:50
11:53
11:56
11:58
11:59
12:01
12:04
12:07
12:09
12:10
12:11
12:14
12:16
12:19
12:21
12:23
12:24
12:26
12:28
12:29
12:32
12:35
12:36
12:36
12:38
12:40
12:42
12:44
12:46
12:48
12:49
12:52
12:54
12:56
12:59
13:01
13:02
13:05
13:07
13:09
13:11
13:12
13:14
13:17
13:19
13:21
13:24
13:27
13:29
13:32
13:34
13:36
13:38
13:39
13:42
13:44
13:48
13:51
13:52
13:54
13:55
13:57
14:00
14:03
14:06
14:09
14:11
14:12
14:15
14:17
14:18
14:20
14:23
14:26
14:28
14:30
14:31
14:34
14:37
14:41
14:43
14:45
14:48
14:50
14:53
14:57
14:58
15:00
15:03
15:04
15:06
15:09
15:11
15:13
15:16
15:17
15:19
15:21
15:23
15:27
15:30
15:32
15:34
15:38
15:41
15:43
15:45
15:47
15:51
15:54
15:58
16:02
16:05
16:06
16:08
16:11
16:13
16:15
16:19
16:21
16:35
16:37
16:48
16:50
17:13
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Hola, humanas y humanos.
Aquí estamos con un nuevo episodio de BIMPRAXIS.
Hoy continuamos con la serie dedicada a los
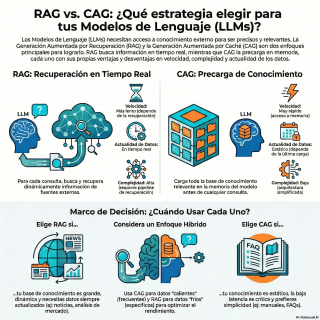
RAG, Retrieval Augmented Generation, y los vamos a
comparar con los CAG o Caché Augmented Generation.
Veremos las ventajas, los inconvenientes de un método
y otro, y también la solución híbrida.
Pues sí, la misión de hoy es analizar
una disyuntiva que es fundamental en la arquitectura
de la IA ahora mismo.
Por un lado, el método que ya conocemos,
RAG, que funciona como un investigador que consulta
una biblioteca en tiempo real.
Y por otro, el aspirante.
Por otro, el aspirante, CAG, que es más
como un experto que se ha memorizado la
biblioteca entera antes de empezar.
Vamos a analizar la velocidad, la precisión y,
sobre todo, cómo su combinación podría definir el
futuro de los sistemas de conocimiento en IA.
Un investigador frente a un sabio memorista.
Me gusta la metáfora.
Muy bien, pues vamos a desgranar esto a
fondo.
Para poner a todo el mundo en la
misma página, si te parece, recordemos brevemente que
es RAG.
Ha sido la solución, bueno, la solución de
facto durante el último par de años para
conectar los modelos de lenguaje con información externa,
¿cierto?
Exacto.
RAG, o Generación Aumentada por Recuperación, es un
sistema de dos pasos.
Cuando recibe una pregunta, lo primero, el primer
paso, es la recuperación.
La búsqueda.
La búsqueda, sí.
Un componente del sistema busca en una base
de datos externa, que suele ser una base
de datos vectorial, los fragmentos de información más
relevantes.
Y el segundo paso es la generación.
Vale.
Esos fragmentos recuperados se meten en el prompt
junto a la pregunta original y se le
entrega todo al modelo para que elabore la
respuesta.
Es la forma de anclar al modelo a
la realidad, por así decirlo, para evitar que
invente datos, las famosas alucinaciones.
Precisamente.
Y para asegurar que sus respuestas se basan
en información fresca, no solo en los datos
con los que fue entrenado, que pueden tener
meses o años.
Claro.
Es ideal para bases de conocimiento enormes o
que cambian constantemente.
Piensa en noticias, informes de bolsa, historiales médicos.
Suena como la solución perfecta, pero los documentos
que hemos revisado para este análisis señalan varias
fricciones importantes.
Y aquí es donde la cosa se pone
interesante.
Así es.
A pesar de sus ventajas, RAG tiene tres
inconvenientes principales.
El primero, y más evidente para quien lo
usa, es la latencia.
La espera.
A nadie le gusta ver el cursor parpadeando
mientras el chatbot piensa.
Exacto.
Ese proceso de búsqueda, de recuperación, de codificar
la pregunta, buscar, recuperar, todo eso añade un
retardo de varios segundos.
Y en una conversación eso rompe la experiencia.
Totalmente.
¿Y el segundo problema?
La complejidad de la arquitectura.
Y esa complejidad no es solo un dolor
de cabeza técnico.
Me imagino que también tiene un coste económico,
¿no?
Has dado en el clavo.
Cada uno de esos componentes, la base de
datos vectorial, los modelos de embedding, el sistema
de indexación, todo tiene un coste de mantenimiento,
de computación, de operación.
Más piezas móviles, más puntos de fallo.
Y más facturas a final de mes.
Y eso nos lleva a la tercera y
quizá más crítica fricción, los errores de recuperación.
Vale.
El sistema es tan bueno como su eslabón
más débil, y en RAG ese eslabón suele
ser el recuperador.
¿Puedes ponernos un ejemplo?
No es solo que no encuentre nada, ¿verdad?
Claro.
Hay dos tipos de error.
Podríamos tener un error de baja precisión, donde
el sistema te trae muchos documentos, pero la
mayoría son irrelevantes, son ruido.
Y el modelo se vuelve loco con tanta
información basura.
Exacto.
Y la respuesta se degrada.
O peor, un error de baja exhaustividad, donde
no encuentra el fragmento clave, el que tiene
la respuesta.
Y ahí da igual lo bueno que sea
el modelo, si no le das la materia
prima correcta.
Basura entra, basura sale.
El clásico.
El clásico.
De acuerdo.
Entonces tenemos latencia, una complejidad que es costosa
y el riesgo constante de que el recuperador
falle.
Un caldo de cultivo perfecto para que surja
una alternativa.
Y esa es CAG.
Caché Augmented Generation.
¿En qué consiste?
Pues CAG representa un cambio de mentalidad radical,
y es posible gracias a una evolución espectacular
de los modelos recientes, las ventanas de contexto
gigantescas.
Que cada vez son más y más grandes.
Hablamos de modelos que ya procesan cientos de
miles o millones de tokens de una vez.
Libros enteros.
La idea de CAG es simple pero muy
potente.
En lugar de buscar la información fuera, ¿por
qué no la precargamos toda dentro del modelo
desde el principio?
¿Te refieres a meter toda la base de
conocimiento directamente en el prompt, como un anexo
gigantesco?
Esencialmente sí.
El flujo de trabajo es completamente distinto.
Primero cargas todos los documentos en el contexto
del modelo.
Y luego haces un paso clave.
Precomputas la caché de clave-valor, la KV-Caché.
A ver, explícanos eso un poco más.
Es, a grandes rasgos, el estado interno del
modelo, sus cálculos, después de haber asimilado todo
ese conocimiento.
Es como si el modelo se estudiara todo
el temario de una sentada antes del examen.
Y ese estado de ya me lo he
estudiado se guarda.
La analogía es perfecta.
Ese estudio es un coste computacional que asumes
una sola vez, al principio.
Una vez generada la caché, cada nueva pregunta
simplemente se añade al final de ese contexto
ya procesado.
Con lo cual, no hay búsqueda externa.
Ninguna.
Ya sabe todo el contenido y puede generar
la respuesta casi al instante.
Ese coste único suena importante.
¿Hablamos de un proceso que tarda minutos, horas?
Porque podría ser un cuello de botella.
Es una pregunta muy pertinente.
No es trivial.
Generar la caché para, digamos, unas 300 páginas
puede llevar varios minutos en una GPU de
gama alta.
Es una inversión inicial.
Pero se amortiza.
Se amortiza muy rápido.
Si el sistema va a recibir miles de
consultas, el tiempo que te ahorras en cada
una compensa con creces esa inversión.
Entendido.
Entonces, si aceptamos ese coste, SIG parece que
resuelve de un plumazo los tres grandes problemas
de RAG.
Latencia, complejidad y errores.
Simplemente desaparecen.
En su mayor parte sí, desaparecen.
La latencia de recuperación se evapora porque no
hay recuperación.
La arquitectura se simplifica muchísimo.
Adiós a la base de datos vectorial, al
indexador… Y los errores de recuperación son imposibles.
Imposibles, porque el modelo no tiene que elegir
qué fragmentos ver.
Tiene una visión completa, holística, de todo el
conocimiento desde el primer momento.
Vale, pongámoslos frente a frente.
Si SIG es tan bueno.
La pregunta obvia es, ¿por qué no lo
usamos para todo?
¿Qué dicen los datos de rendimiento que hemos
analizado?
Aquí es donde los resultados son realmente impactantes.
En pruebas con basas de conocimiento como Hotpot
QA, las diferencias de velocidad son abismales.
Un sistema CAG responde de media en 0,85
segundos.
¿0,85?
Sí.
Un sistema RAG comparable tarda unos 9,25 segundos.
Eso es más de 10 veces más rápido,
una diferencia brutal para cualquier aplicación interactiva.
Y se pone mejor.
En conjuntos de datos un poco más grandes,
la diferencia se dispara.
Las fuentes hablan de 2,3 segundos para CAG
frente a unos increíbles 94,3 segundos para RAG.
Un momento, es una mejora de hasta 40
veces.
Hasta 40 veces.
Suena casi demasiado bueno para ser verdad.
En estas comparativas estamos seguros de que se
comparan sistemas optimizados en ambos lados.
O sea, no podría ser un escenario ideal
para CAG contra un RAG que no está
del todo afinado.
Es una dosis de escepticismo muy saludable.
Y aunque la optimización siempre es un factor,
la diferencia aquí es arquitectónica.
RAG implica, por narices, una llamada de red
a una base de datos, una búsqueda… Unos
pasos que no te puedes saltar.
Exacto.
CAG elimina todo eso.
Es la diferencia entre buscar un dato en
un libro que tienes en otra habitación o
tenerlo ya abierto sobre la mesa.
Incluso el RAG más optimizado del mundo tendrá
siempre ese cuello de botella.
Vale, aceptamos la ventaja en velocidad.
Pero la velocidad no sirve de nada si
las respuestas son peores.
¿Qué pasa con la precisión?
Uno podría pensar que darle al modelo cientos
de páginas a la vez podría confundirlo.
Pues, contra toda intuición, ocurre lo contrario.
Aquí también hay sorpresas.
Lejos de confundirse, los estudios muestran que CAAG
suele obtener puntuaciones de precisión ligeramente superiores.
Ah.
Sí.
Por ejemplo, una fuente reporta una puntuación BERT
score de 0,7759 para CAG frente a 0,751
para RAG.
¿Y cuál es la teoría detrás de esa
mejora?
La hipótesis es que, al tener la visión
global de todo el contexto, el modelo puede
realizar razonamientos más complejos.
Puede conectar una idea del documento A con
un detalle del documento Z.
Algo que un RAG solo podría hacer si
el recuperador, por casualidad, trae justo esos dos
fragmentos.
Exactamente.
Si falla en recuperar uno, la conexión se
pierde.
CAG, al tener la panorámica completa, no sufre
esa limitación.
Puede encontrar relaciones sutiles entre distintas partes del
conocimiento.
De acuerdo.
Recapitulo.
Es drásticamente más rápido y, sorprendentemente, un poco
más preciso.
Aquí tiene que estar la trampa.
¿Cuál es el talón de Aquiles de CAG?
Tiene dos, y son muy importantes.
Son las razones por las que RAG no
va a desaparecer.
La primera, el conocimiento es estático.
La caché es una foto fija.
Claro.
Si tu base de datos se actualiza constantemente,
precios de acciones, noticias, el inventario de una
tienda, la caché se queda obsoleta al instante.
Y para actualizarla tendrías que regenerar toda la
caché, con el coste que eso implica.
Inviable para datos en tiempo real.
Exacto.
Y la segunda gran limitación es el propio
tamaño de la ventana de contexto.
Aunque son enormes, tienen un límite.
Una ventana de 128.000 tokens puede albergar unas
300 páginas.
Que es mucho.
Es mucho, pero es insuficiente para bases de
datos a escala de una gran empresa, que
pueden tener millones de documentos.
O sea que, por ejemplo, no podrías cargar
todo el boletín oficial del Estado, o toda
la documentación técnica de una multinacional.
Simplemente no cabe.
Correcto.
RAH, en cambio, tiene un tamaño de corpus
teóricamente ilimitado, porque solo carga los pocos fragmentos
que necesita en cada consulta.
Lo que nos lleva a la conclusión lógica.
No se trata de que una tecnología vaya
a reemplazar a la otra.
Para nada.
Sino de que son herramientas diferentes para problemas
diferentes.
O, como sugieren varias de las fuentes, de
que la solución definitiva podría ser usarlas juntas.
Esa es precisamente la dirección que está tomando
la industria, los sistemas híbridos.
Y la estrategia más común es la de
clasificar los datos como calientes y fríos.
¿Puedes explicar qué significa eso en la práctica?
¿Qué es un dato caliente frente a uno
frío?
Piensa en los datos calientes como el núcleo
de conocimiento estable y de acceso muy frecuente.
Para una empresa, pues sus políticas internas, manuales
de producto, las preguntas frecuentes.
Lo que se pregunta siempre.
Eso es.
Esa información se carga en la capa CAG.
Al estar en la caché, las respuestas a
las preguntas más comunes son instantáneas.
Y supongo que RAG se encarga de todo
lo demás, del conocimiento frío.
Exacto.
El conocimiento frío son los datos de nicho,
los que son muy voluminosos o los que
cambian a gran velocidad.
En un sistema híbrido, el flujo sería así.
Llega la pregunta, el sistema intenta responderla con
la capa CAG.
Que es la rápida.
La rapidísima.
Si encuentra la respuesta, perfecto.
Si no, o si la información no es
suficiente, la consulta se escala y se pasa
a la capa RAG para que haga una
búsqueda en tiempo real en la base de
datos completa.
Demos un ejemplo más para solidificar la idea.
Pensemos en un asistente para una tienda online.
Los datos calientes en la caché de CAG
serían las políticas de devolución, las especificaciones de
los productos más vendidos.
Perfectamente ilustrado.
Y si un cliente pregunta, ¿dónde está mi
pedido con número X?
O, ¿tenéis la talla M de esta camiseta
en stock ahora mismo?
Esa es una consulta fría.
Claro, eso cambia a cada minuto.
El sistema activaría la capa RAG para consultar
en tiempo real la base de datos de
pedidos o el sistema de inventario.
Así combinas la velocidad de CAG para el
80% de las consultas comunes con la flexibilidad
de RAG para el 20% restante.
¿Esto implica que el sistema necesita una especie
de director de orquesta que decida qué camino
tomar con cada pregunta?
Correcto, y esa es un área de investigación
muy activa.
Ya existen mecanismos de enrutamiento inteligente.
Uno de los estudios que revisamos menciona un
sistema llamado Self-Route, que entrena al propio modelo
de lenguaje para que sea él quien decida.
El propio modelo.
Sí, le llega una pregunta y el modelo
predice.
¿Puedo responder esto con la información de mi
caché o necesito pedir ayuda externa?
Así que el modelo se convierte en su
propio controlador de tráfico de conocimiento y eso
requiere un entrenamiento muy específico.
Generalmente requiere un fine tuning para esa tarea
de clasificación.
Se le entrena con miles de ejemplos, pero
lo fascinante es que estos sistemas son muy
eficientes.
El estudio de Selfroot demostró que podía alcanzar
la misma calidad de respuesta, pero usando de
media solo el 38% de los tokens.
Es lo mejor de ambos mundos, entonces.
Velocidad y eficiencia.
Exacto.
Notebooks LM, aunque entre bambalinas del podcast siempre
está Julio Pablo Vázquez, que sigue con su
vigilancia tecnológica en alerta constante para pescar los
mejores temas y de más actualidad.
Además, nos dice que os manda saludos y
que está muy contento porque acaba de desarrollar
un sistema propio con Python y Javascript y,
por supuesto, IA, para automatizar el proceso de
edición, descripción, transcripción, publicación y programación de todos
los episodios.
Ya veis, no solo le vamos a las
parrafadas, también aplicamos el conocimiento a la práctica
diaria.
Gracias a este sistema, que hemos bautizado como
Autopod, ahora podemos dedicar más tiempo al factor
humano y minimizar errores.
Quizá un día le dediquemos un episodio a
contaros cómo creamos cada episodio, porque hay mucha
IA y herramientas implicadas.
¿Os parece interesante?
Y para cerrar, una reflexión final que se
deriva de toda esta discusión.
La tensión entre RAG y CAC, impulsada por
la explosión de las ventanas de contexto, nos
obliga a plantearnos una pregunta de diseño fundamental
para el futuro.
CAC favorece un enfoque monolítico, centralizar todo el
conocimiento posible en un único y masivo prompt,
un gran cerebro precargado.
Mientras que RAG es modular.
RAG, por el contrario, aboga por un enfoque
modular, mantener el conocimiento externo, descentralizado, en una
biblioteca que se consulta sólo cuando es necesario.
La pregunta que debemos hacernos es, ¿qué tipo
de arquitectura de IA queremos construir?
¿Sistemas con un único y enorme cerebro que
lo sabe todo de antemano?
¿O sistemas con un cerebro más ágil y
especializado que es experto en consultar una vasta
red de bibliotecas externas?
Las decisiones que los arquitectos de IA tomen
hoy entre estos dos modelos definirán la flexibilidad,
la escalabilidad y, en última instancia, la robustez
de la inteligencia artificial del mañana.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.
¡Gracias!