Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:09
0:15
0:20
0:23
0:26
0:28
0:36
0:39
0:44
0:48
0:50
0:53
0:55
0:57
1:00
1:02
1:04
1:04
1:05
1:07
1:10
1:12
1:16
1:20
1:22
1:23
1:26
1:31
1:32
1:33
1:36
1:40
1:42
1:43
1:43
1:46
1:49
1:52
1:52
1:55
1:58
2:00
2:02
2:04
2:06
2:08
2:10
2:14
2:17
2:19
2:21
2:24
2:26
2:27
2:29
2:31
2:32
2:34
2:37
2:39
2:41
2:42
2:42
2:43
2:46
2:48
2:49
2:51
2:53
2:56
2:57
3:00
3:02
3:03
3:05
3:06
3:07
3:08
3:11
3:13
3:14
3:16
3:19
3:21
3:21
3:24
3:26
3:29
3:31
3:31
3:33
3:35
3:35
3:38
3:40
3:42
3:44
3:45
3:47
3:50
3:51
3:54
3:55
3:56
3:59
4:01
4:03
4:06
4:08
4:09
4:11
4:13
4:15
4:18
4:22
4:23
4:25
4:26
4:27
4:31
4:34
4:36
4:37
4:39
4:39
4:41
4:44
4:46
4:50
4:51
4:52
4:53
4:54
4:55
4:56
4:59
5:00
5:03
5:06
5:09
5:10
5:11
5:13
5:14
5:15
5:16
5:18
5:20
5:22
5:26
5:27
5:29
5:30
5:32
5:34
5:36
5:37
5:39
5:39
5:40
5:41
5:42
5:45
5:48
5:49
5:50
5:51
5:52
5:55
5:57
5:59
6:02
6:04
6:07
6:09
6:11
6:13
6:15
6:15
6:18
6:19
6:21
6:23
6:25
6:27
6:28
6:31
6:35
6:36
6:38
6:39
6:40
6:41
6:43
6:44
6:47
6:50
6:51
6:53
6:55
6:58
7:00
7:03
7:03
7:04
7:07
7:07
7:09
7:10
7:11
7:14
7:16
7:19
7:21
7:23
7:24
7:25
7:26
7:28
7:29
7:31
7:32
7:34
7:36
7:37
7:40
7:41
7:42
7:44
7:47
7:48
7:51
7:53
7:55
7:56
8:00
8:02
8:03
8:05
8:05
8:08
8:11
8:12
8:13
8:16
8:17
8:18
8:19
8:22
8:23
8:26
8:28
8:30
8:31
8:33
8:34
8:37
8:38
8:39
8:42
8:46
8:47
8:50
8:53
8:55
8:56
8:58
9:01
9:04
9:04
9:05
9:07
9:07
9:10
9:12
9:13
9:15
9:16
9:18
9:21
9:22
9:24
9:25
9:28
9:29
9:30
9:31
9:32
9:34
9:34
9:37
9:39
9:41
9:43
9:45
9:46
9:48
9:50
9:52
9:56
9:58
10:00
10:03
10:05
10:06
10:07
10:09
10:11
10:14
10:17
10:19
10:20
10:23
10:25
10:27
10:29
10:30
10:32
10:34
10:37
10:40
10:42
10:43
10:46
10:48
10:50
10:53
10:55
10:57
10:58
11:02
11:04
11:06
11:08
11:09
11:12
11:15
11:17
11:18
11:20
11:22
11:24
11:37
11:39
11:52
11:53
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
¡Hola, humanas y humanos!
Aquí estamos con un episodio nuevo de BIMPRAXIS.
En el episodio de hoy, seguimos profundizando en
técnicas innovadoras para que los modelos de IA
ofrezcan resultados de más calidad.
Ya veréis qué interesante.
Porque hoy vamos a analizar a fondo una
de esas técnicas que, bueno, parecen casi ciencia
ficción, pero que ya están dando unos resultados
sorprendentes.
¡Hola!
¿Qué tal?
Pues sí, es un tema fascinante.
El punto de partida es una gráfica que
ha llamado mucho la atención.
Vemos un modelo como Gemini Flash 3, que
está diseñado para ser rápido, ligero… El pequeño
de la familia, por así decirlo.
Exacto.
Y de repente supera a gigantes como GPT
5 .2 Hive o Claude Opus 4 .5.
La pregunta es obvia.
¿Cómo es posible?
Y la respuesta está en un concepto llamado
autoagregación recurrente, o RSA para abreviar.
Vamos a desgranar cómo funciona.
Que tiene miga.
Exacto.
La pregunta clave que resuelve esta técnica es,
si entrenar y reentrenar modelos cada vez más
grandes es carísimo, o sea, es insostenible.
Claro.
¿Cómo podemos exprimir al máximo la inteligencia que
ya tienen sin tener que modificar sus parámetros?
Y la solución, por lo que parece, es
hacer que trabajen más tiempo.
Más tiempo, pero de forma inteligente.
En el momento de la inferencia, que es
cuando generan la respuesta.
Y el método RSA es una forma muy,
muy ingeniosa de gestionar… Vale, pues antes de
meternos de lleno en esta evolución artificial, que
es como la llaman, creo que deberíamos explicar
las formas más comunes de hacer que un
modelo piense más en un problema.
Sí, para entender lo nuevo, hay que ver
lo de antes.
La primera es la que podríamos llamar, no
sé, la fuerza bruta en paralelo.
Correcto.
Consiste de forma muy simple en pedirle al
modelo que genere, por ejemplo, 20 respuestas diferentes
a la misma pregunta.
Y luego, supongo, se hace una especie de
votación.
Justo.
Un sistema de votación.
Si 15 de las 20 respuestas dicen lo
mismo, se asume que esa es la más
probable de ser correcta.
El problema que le veo, y que comentan
las fuentes, es que cada una de esas
20 respuestas es como tirar un dado una
vez.
Le das 20 oportunidades, sí, pero en cada
una de ellas tiene que salir todo perfecto
a la primera.
No hay un proceso de mejora entre un
intento y el siguiente.
Precisamente.
Esa es la gran limitación.
Hay amplitud, pero no hay profundidad.
Y por eso surgió la otra estrategia.
¿La secuencial?
La secuencial, o de autocorrección.
Aquí el modelo genera una primera respuesta, y
luego se le pide que la revise y
la corrija.
Como si fuera su propio profesor o editor.
Eso es, en un proceso paso a paso.
Este es mi borrador, ahora lo reviso.
Ah, mira, aquí he fallado.
Lo corrijo.
Suena mejor, la verdad.
Pero también tiene un punto débil, ¿no?
Sí.
Es como si, al escribir un texto, te
centraras tanto en mejorar una frase, que no
te das cuenta de que todo el párrafo
se basa en una idea equivocada.
Has dado en el clavo.
El modelo puede atascarse mejorando una idea sin
explorar otras que podrían ser mucho mejores.
Le falta diversidad.
Se queda atascado en lo que en optimización
llaman un mínimo local.
Justamente.
Teníamos un método con amplitud, pero sin profundidad,
y otro con profundidad, pero sin amplitud.
Y aquí, por fin, es donde entra la
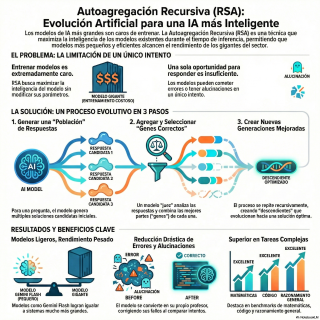
autoagregación recursiva, o RSA.
Para combinar lo mejor de los dos mundos.
¿La idea central?
Es fascinante.
Trata a las respuestas como si fueran una
población en un proceso de evolución.
Es una analogía muy potente y muy acertada.
El proceso, explicado de forma sencilla, sigue varios
pasos.
Podemos usar un ejemplo de las fuentes para
que quede más claro.
Perfecto.
Mencionaban el de calcular el factorial de 136.
Ideal, porque implica muchísimas multiplicaciones seguidas.
Un error en una de ellas y ya
está todo mal.
Vale, pues, primer paso.
¿El modelo?
No genera una, sino una población.
Digamos, ocho respuestas distintas.
Ya tenemos la diversidad del primer método.
Algunas serán parecidas, otras muy diferentes, con fallos
en distintos puntos.
Exacto.
Segundo paso.
Se identifican los genes.
¿Los genes?
Sí.
Cada parte de la respuesta, cada multiplicación en
este ejemplo, es un gen.
Un gen puede ser correcto o incorrecto.
Imagina que la respuesta número uno hace todo
bien hasta multiplicar 56 por 55.
¿Por qué se equivoca?
Vale.
Pues, todo lo anterior a ese error es
un gen bueno.
Una secuencia correcta.
Entiendo.
Y Kikó es la respuesta número seis, se
equivocó al principio.
Pero a partir de esa multiplicación, la de
56 por 55, lo hizo todo perfecto.
Justo.
Esa parte final es otro gen bueno.
Ya veo por dónde vas.
Se buscan los trozos buenos en todas las
respuestas, aunque la respuesta entera esté mal.
Eso es.
Y ahora viene el tercer paso.
El corazón del asunto.
¿El corazón del asunto?
La agregación.
La reproducción.
Algo así.
Se cogen varias respuestas al azar de la
población, por ejemplo cuatro, y se le presentan
a un modelo juez.
¿Que es otro modelo distinto?
No.
Y eso es importante.
Es el mismo modelo, pero con una instrucción,
con un prompt específico.
El juez tiene la tarea de analizar esos
genes y construir una nueva respuesta que sólo
contenga los buenos, los correctos.
O sea, una especie de Frankenstein optimizado.
Has dado en el clavo.
Y coge las partes buenas de varias respuestas
para crear una nueva que es superior a
cualquiera de las originales.
Exacto.
Y lo crucial es el cuarto paso.
Recursivo.
Este proceso no se hace una sola vez.
Ah, claro.
Se repite para crear una nueva generación de
respuestas que a su vez sirve de base
para la siguiente.
La población de respuestas va evolucionando.
Y cada generación es, en teoría, más correcta,
más apta que la anterior.
Es un ciclo de mejora continua.
¿Es brillante?
Es que es brillante.
Lo es.
Y claro, los resultados son la prueba de
que funciona.
En benchmarks de matemáticas, de código, de razonamiento
general, RSA ha demostrado ser superior a los
métodos anteriores.
Sí, por un margen considerable.
Esto explica perfectamente la gráfica del principio.
Como modelos más ligeros pueden, de repente, competir
e incluso ganar a los más pesados.
Aunque es importante matizar una cosa que señalan
las fuentes.
A ver.
En un área específica, la de recordar conocimiento
puro y duro.
Un dato, vamos.
La capital de Mongolia.
Por ejemplo.
Ahí, la estrategia simple de la votación mayoritaria
sigue siendo más eficaz.
RSA brilla en tareas que requieren razonamiento complejo.
Lo cual tiene todo el sentido del mundo.
No hay nada que razonar en un dato
puro.
O se sabe o no se sabe.
Correcto.
RSA no es para recuperar datos, es para
procesarlos.
Y esto nos lleva a una de sus
aplicaciones más útiles.
Los sistemas RAG, ¿verdad?
Retrieval Augmented Generation.
Justo.
Los que consultan documentos para responder.
Ahí el riesgo de error es alto.
Altísimo.
Y las fuentes describen un ejemplo muy claro.
Un sistema RAG para ingenieros que consultan manuales
técnicos.
La consulta es, ¿cómo solucionar el error de
presión en la válvula X4?
Un entorno donde un error puede ser grave.
Muy grave.
El sistema recupera varios fragmentos de los manuales.
Y a partir de ahí, genera su población
de respuestas.
Imagina dos candidatos.
Venga.
Un candidato de respuesta identifica bien los pasos
de seguridad, pero se equivoca en las herramientas
que hay que usar.
Mal.
Otro candidato acierta con las herramientas, pero olvida
un paso de seguridad crítico.
Peor todavía.
Exacto.
Por sí solas, ambas respuestas son un desastre
potencial.
Pero con RSA, el juez identifica el gen
bueno de la seguridad del primero.
Y el gen bueno de las herramientas del
segundo.
Y los combina en una respuesta final completa
y correcta.
Reduce muchísimo el riesgo de alucinaciones o de
errores lógicos.
Una de las cosas que más me llama
la atención es que, según el análisis, la
implementación de RSA es bastante sencilla.
Relativamente, sí.
El prompt para el modelo juez es tan
simple como agrega ideas útiles y produce una
sola respuesta de alta calidad.
Sí.
Su accesibilidad es un punto a favor.
No requiere una ingeniería de prompts súper compleja.
Sin embargo, el autor del análisis original indica
que no.
Y entonces se introduce una idea que me
parece, bueno, me parece clave.
¿Cuál?
El crema es en una explosión del trabajo
que en una explosión de la inteligencia.
Explosión del trabajo.
¿Qué significa eso exactamente?
Pues que si tomas un modelo que ya
es muy inteligente y le das un proceso
estructurado como RSA, junto con muchísimo tiempo de
cómputo.
Claro, porque esto consume tiempo.
Mucho tiempo.
El resultado puede parecer súper inteligente, pero no
es que el modelo base sea mágicamente más
listo.
Entiendo.
Sino que se le ha dado un método.
Y los recursos para trabajar así.
Y eso puede llevar en un problema a
un nivel de profundidad que antes era imposible.
Es una distinción muy importante.
No es que la IA sea de repente
más consciente, sino que le hemos dado un
método de trabajo mucho mejor.
Exacto.
Hemos pasado de pedirle que corra un sprint
a darle un plan de entrenamiento y los
medios para correr una maratón.
Entonces, si esta es la explosión del trabajo,
¿cuál es la limitación?
O bueno, ¿cuál es el siguiente paso?
La gran ventaja de RSA es que no
necesita verificadores.
¿Se autocorrige?
Se autocorrige, sí.
No tiene que consultar Internet o ejecutar código
para saber si va por buen camino.
Sin embargo, el análisis sugiere que las versiones
más potentes en el futuro… Mmm, probablemente sí
incorporarán esa verificación externa.
Sin duda.
Además de otras técnicas como dividir problemas complejos
en tareas más pequeñas.
RSA es un método potentísimo.
Pero es una pieza del puzzle.
Exacto.
Quizá es sólo una pieza del puzzle final
para alcanzar un razonamiento.
Un razonamiento artificial aún más robusto.
Imagina combinar la evolución interna de RSA con
la capacidad de contrastar las ideas con el
mundo real.
Que el modelo pueda pararse y decir, a
ver, esta pieza de código que he creado,
¿funciona si la ejecuto de verdad?
O este dato que estoy usando, puedo verificarlo
en una fuente fiable en tiempo real.
Eso sería un salto cualitativo enorme.
La verdad es que sí.
Por eso, RSA es un avance formidable en
cómo organizar el trabajo de una IA.
El siguiente gran avance vendrá de conectar ese
trabajo con la realidad.
Nos despedimos por hoy.
No sin antes recordar que las voces que
escuchas son generadas por una IA, Notebook LM.
Pero el podcast no se genera de forma
automática, no.
Detrás de todo lo que escuchas está un
humano, que os manda saludos, que se llama
Julio Pablo Vázquez.
Muchas gracias y hasta el próximo episodio.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
BIMPRAXIS.
Nos escuchamos en el próximo episodio.