Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:10
0:15
0:20
0:23
0:26
0:28
0:30
0:39
0:42
0:44
0:46
0:48
0:51
0:54
0:55
0:57
1:00
1:02
1:04
1:06
1:08
1:10
1:13
1:15
1:19
1:22
1:24
1:26
1:28
1:29
1:30
1:33
1:34
1:37
1:40
1:42
1:46
1:47
1:48
1:50
1:53
1:56
1:59
2:02
2:03
2:06
2:10
2:13
2:15
2:16
2:18
2:20
2:23
2:24
2:26
2:27
2:29
2:31
2:31
2:34
2:36
2:40
2:42
2:44
2:47
2:51
2:52
2:55
2:57
2:57
2:58
3:00
3:03
3:06
3:06
3:11
3:13
3:14
3:16
3:19
3:21
3:22
3:23
3:25
3:27
3:29
3:31
3:32
3:34
3:36
3:39
3:42
3:45
3:47
3:49
3:50
3:53
3:56
3:58
4:02
4:06
4:07
4:10
4:11
4:15
4:18
4:19
4:21
4:22
4:25
4:29
4:30
4:31
4:34
4:36
4:38
4:41
4:44
4:46
4:49
4:50
4:51
4:52
4:55
4:58
5:00
5:03
5:03
5:05
5:06
5:09
5:11
5:13
5:16
5:18
5:21
5:23
5:25
5:28
5:30
5:34
5:36
5:38
5:39
5:41
5:43
5:46
5:47
5:48
5:49
5:51
5:55
5:58
5:59
5:59
6:02
6:04
6:06
6:07
6:10
6:11
6:13
6:14
6:15
6:18
6:21
6:23
6:26
6:28
6:31
6:33
6:34
6:36
6:38
6:40
6:43
6:44
6:47
6:48
6:50
6:52
6:55
6:58
7:00
7:04
7:05
7:07
7:10
7:12
7:14
7:16
7:19
7:20
7:23
7:26
7:28
7:31
7:34
7:36
7:39
7:40
7:42
7:45
7:46
7:48
7:50
7:52
7:55
7:57
7:58
7:59
8:02
8:05
8:06
8:07
8:08
8:10
8:13
8:15
8:18
8:20
8:21
8:23
8:25
8:28
8:29
8:31
8:31
8:34
8:37
8:39
8:42
8:45
8:48
8:51
8:53
8:55
8:58
8:59
9:01
9:04
9:06
9:10
9:11
9:12
9:15
9:16
9:18
9:20
9:20
9:23
9:25
9:26
9:28
9:29
9:30
9:32
9:35
9:36
9:38
9:51
9:53
10:04
10:07
10:29
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Hola humanas y humanos, aquí estamos con un
episodio nuevo de BIMPRAXIS.
En el episodio de hoy, el número 53,
seguimos profundizando en el uso de grafos para
mejorar la calidad de los sistemas de generación
aumentada por recuperación, o RAG para los amigos.
Ya sabéis, dentro de nuestra serie dedicada a
los RAG.
Hoy venimos con un paper académico y varias
fuentes expertas que explican una técnica, bueno, fascinante,arxiv
llamada GraphRAG.
Vamos a desgranar de qué va todo esto.
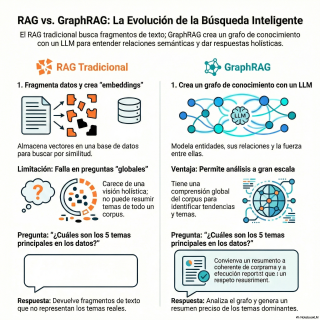
Para empezar, y para que todo el mundo
se sitúe, recordemos un poco cómo funciona un
sistema RAG básico.
El proceso habitual, según explican las fuentes, es
coger un montón de documentos, partirlos en trocitos
más pequeños, en chunks, sí, eso es, y
luego convertirlos en vectores, en números, y guardarlos
en una base de datos vectorial.
Y cuando alguien pregunta algo, pues el sistema
busca los trozos más parecidos y con eso
genera la respuesta.
Exacto.
Es un sistema de recuperación de información muy
potente, la verdad.
Pero tiene una limitación fundamental.
Y el paper From Local to Global la
identifica muy, muy claramente.
Falla estrepitosamente con lo que llaman preguntas globales.
¿Preguntas globales?
¿A qué se refieren con eso?
Pues mira, es una pregunta que no busca
un dato concreto, un trocito de información.
busca una comprensión del conjunto de datos entero.
Por ejemplo, una pregunta como ¿cuáles son los
temas principales de este corpus de documentos?
Ah, claro.
Un RAG convencional buscará fragmentos que tengan las
palabras temas o principales y, bueno, seguramente da
una respuesta bastante pobre o directamente irrelevante, porque
es una tarea de resumen, no de recuperación
pura y dura.
Vale, entiendo.
O sea que el RAG tradicional se queda
corto para entender el bosque, se centra demasiado
en los árboles.
Y es aquí, supondo, donde entra la propuesta
de las fuentes.
GraphRAG.
Lo describen como un proceso en dos pasos.
Sí.
El primer paso es la indexación.
Ahí se usa un modelo de lenguaje grande,
un LLM, para crear un grafo de conocimiento
a partir de todos los datos.
Y el segundo paso es, una vez tienes
ese grafo, usarlo para organizar una recuperación de
información que es muchísimo más inteligente.
Grafo de conocimiento.
Es un término que impone un poco.
Bueno, pero es más sencillo de lo que
parece.
A ver.
A diferencia de una base de datos normal,
con sus filas y columnas, un grafo de
conocimiento tiene nodos y aristas.
Vale.
Los nodos son las entidades, personas, empresas, conceptos.
Y las aristas son las relaciones entre esos
nodos.
Y lo interesante es que tanto los nodos
como las aristas pueden guardar información.
O sea, la línea que los une también
tiene datos.
Exacto.
Un ejemplo que hemos visto todos es la
tarjeta de información que sale en Google o
en Bing cuando buscas una persona famosa.
Ah, la ficha de la derecha.
Esa misma.
Eso se extrae de un grafo de conocimiento.
Aquí es donde la cosa se pone, para
mí, realmente interesante.
La clave de GraphRag no es solo identificar
las entidades en un texto, sino entender las
relaciones que hay entre ellas.
Y una de las fuentes da un ejemplo
que es buenísimo.
La frase es, la líder del PEO, Silvia
Mar, subió al escenario con Luke Jack, fundador
de Save Our Wildlands.
Vale, un sistema normal identificaría a Silvia Mar,
PEO, Luke Jack y Save Our Wildlands, cuatro
entidades.
Pero aquí un modelo como GPT-4 va mucho
más allá.
Entiende la semántica, entiende que la relación entre
Silvia Mar y el PEO es fuerte porque
es la líder.
Claro, es una relación estructural.
Eso es.
En cambio, su relación con Save Our Wildlands
es débil, es circunstancial, solo comparte escenario con
su fundador.
¡Ostras, qué bueno!
Esto lo que crea es un grafo ponderado,
con relaciones que tienen distinta fuerza.
Y eso es mucho más rico que una
simple red de palabras que aparecen juntas.
Y después, sobre este grafo se aplican técnicas
de Machine Learning de grafos para agrupar los
nodos en comunidades semánticas.
Vale, espera.
Comunidades semánticas.
Sí.
Básicamente agrupa los conceptos que están muy relacionados
entre sí, creando como temas o clústeres.
Y eso te da una estructura jerárquica que
te permite hacer consultas a distintos niveles de
detalle.
La teoría suena muy bien, pero vamos a
la práctica.
Las fuentes incluyen demostraciones que muestran la diferencia
de una forma, bueno, espectacular.
La primera usa un conjunto de 3.000 artículos
sobre el conflicto entre Rusia y Ucrania.
Un tema muy denso, sí.
Y la pregunta es, ¿qué es Novorossia y
cuáles son sus objetivos?
Los resultados aquí son reveladores.
Un RAG básico, sin más, falla.
No sabe qué responder.
Un RAG que llaman mejorado o afinado, responde
a la primera parte, te explica qué es
Novorossia, pero no llega a la segunda.
¿Y Graf RAG?
La diferencia es abismal.
No solo explica qué es Novorossia, sino que
da una lista de objetivos súper específicos que
ha sacado de los documentos.
¿Ah, sí?
¿Como cuáles?
Pues mira, la Compañía Nacional de Televisión de
Ucrania, una emisora de radio, un banco privado,
propiedades de Roshan e incluso planes de ataques
en Odessa.
¡Guau!
Y supongo que lo más importante es que
puedes rastrear de dónde saca cada cosa.
Para evitar alucinaciones.
Totalmente.
Cada afirmación está vinculada al fragmento de texto
original.
Esto te permite verificar la información, que es
crucial.
Y esto nos lleva de vuelta a las
preguntas globales, al gran problema.
Le preguntaron al sistema, ¿cuáles son los cinco
temas principales de los datos?
Y aquí, el RAG básico dio respuestas genéricas,
cosas como, estado de la economía rusa.
¿Cuándo el 80% de los artículos iban sobre
el conflicto.
Exacto.
Ignoró el tema principal.
GraphRAG, en cambio, identificó el conflicto como el
tema central, sin dudarlo.
Claro, porque tiene esa visión de conjunto.
Hay una contrapartida, eso sí.
GraphRAG es más costoso computacionalmente.
Mucho más.
En el ejemplo, usó 50.000 tokens y tardó
71 segundos.
El RAG básico, 5.000 tokens y 8 segundos.
Uf, es bastante diferencia.
Sí, pero la calidad y la corrección de
la respuesta son inmensamente superiores.
Al final es un trade-off.
¿Quieres rapidez o quieres precisión?
Hay otra demostración que me pareció muy visual.
Se hizo con las transcripciones del podcast Behind
the Tech de Kevin Scott.
Sí, ese caso es fascinante.
Ahí el LLM construyó el grafo de conocimiento
desde cero.
En la visualización, cada nodo era una entidad
y los colores representaban, digamos, los temas, las
particiones semánticas.
Y lo fascinante es cómo agrupó las cosas.
Sí, porque identificó una comunidad semántica sobre biología
y en el mismo clúster, en el mismo
grupo, junto a dos expertos diferentes.
Drew Endy y David Baker.
Vale, ¿y qué tiene eso de especial?
Pues que aparecieron en episodios distintos.
Nunca hablaron entre ellos.
Espera, ¿me estás diciendo que el sistema los
agrupó solo porque se dio cuenta de que
los dos hablaban de lo mismo, aunque fuera
en momentos diferentes y sin mencionarse?
Exactamente eso.
No se basó en que sus nombres aparecieran
juntos.
Se basó en que entendió las conexiones temáticas
que había debajo de sus conversaciones.
Es la prueba de que de verdad entiende
el contenido.
Desde luego.
Demuestra que no solo recupera, sino que comprende.
Entonces, después de ver todo esto, ¿qué significa?
¿Cuál es la gran conclusión?
Significa que GraphIRG no es sólo una mejora
incremental, es un cambio de paradigma.
¿De qué manera?
Pasamos de la recuperación local de fragmentos de
texto, que es lo que teníamos, a la
creación de una memoria estructurada, una comprensión global
de todo un corpus.
¿De lo local a lo global, como el
título del paper?
Justo eso, es exactamente lo que resume.
Esto plantea una pregunta interesante, creo.
Todo esto se basa en que un LLM
construye estos grafos de forma autónoma, Pero para
dominios de alto riesgo como la medicina o
el derecho, ¿podríamos fiarnos de un sistema así?
Esa es la gran pregunta.
¿Podemos ver sistemas híbridos en el futuro?
Sistemas que combinen la escala de la IA
con la precisión y la verificación del conocimiento
humano.
¿Cómo funcionaría eso?
Pues imagina un sistema donde el LLM propone
un primer borrador del grafo y luego expertos
humanos, médicos o abogados lo revisan, lo curan…
Lo validan.
Exacto.
Creando sistemas RAG que serían aún más fiables
y robustos.
Podría ser el siguiente paso.
Bueno, pues con esa reflexión nos despedimos por
hoy.
No sin antes recordar que las voces que
escuchas son generadas por una IA, por Notebook
LM.
Pero el podcast no se genera de forma
automática.
Detrás de todo lo que escuchas hay un
humano, que os manda saludos.
Se llama Julio Pablo Azquez y está encantado
de que el podcast cada vez tiene más
suscriptores.
Muchas gracias y hasta el próximo episodio.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.
SUSCRÍBETE 🙏