Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:10
0:15
0:20
0:23
0:26
0:28
0:37
0:38
0:40
0:43
0:45
0:49
0:52
0:53
0:55
0:56
0:58
1:02
1:05
1:08
1:10
1:12
1:14
1:16
1:20
1:22
1:26
1:27
1:31
1:33
1:35
1:38
1:39
1:41
1:43
1:45
1:46
1:48
1:49
1:51
1:53
1:57
1:58
2:00
2:02
2:04
2:05
2:08
2:09
2:13
2:15
2:18
2:20
2:22
2:25
2:27
2:31
2:34
2:34
2:37
2:39
2:42
2:44
2:47
2:49
2:51
2:53
2:54
2:57
2:59
3:02
3:05
3:06
3:09
3:12
3:15
3:18
3:19
3:23
3:26
3:27
3:29
3:32
3:35
3:36
3:38
3:42
3:42
3:43
3:45
3:48
3:50
3:54
3:57
3:59
4:02
4:03
4:06
4:08
4:09
4:12
4:14
4:16
4:18
4:21
4:22
4:23
4:24
4:27
4:31
4:34
4:35
4:37
4:40
4:42
4:45
4:49
4:50
4:53
4:55
4:57
4:59
5:01
5:03
5:05
5:06
5:07
5:09
5:10
5:12
5:16
5:18
5:18
5:20
5:21
5:22
5:23
5:27
5:29
5:32
5:35
5:38
5:39
5:41
5:44
5:45
5:46
5:49
5:52
5:55
5:57
6:00
6:03
6:08
6:12
6:13
6:16
6:19
6:21
6:24
6:25
6:28
6:30
6:30
6:32
6:34
6:35
6:38
6:41
6:43
6:45
6:46
6:48
6:50
6:54
6:56
6:57
6:59
7:02
7:03
7:05
7:09
7:11
7:13
7:13
7:17
7:20
7:23
7:25
7:28
7:29
7:30
7:33
7:34
7:36
7:39
7:41
7:44
7:45
7:45
7:48
7:51
7:54
7:56
7:57
8:00
8:02
8:05
8:08
8:10
8:13
8:15
8:15
8:17
8:20
8:23
8:26
8:29
8:31
8:33
8:35
8:36
8:38
8:40
8:41
8:43
8:45
8:50
8:53
8:56
8:56
8:59
8:59
9:02
9:02
9:05
9:06
9:07
9:08
9:11
9:14
9:15
9:17
9:20
9:21
9:25
9:26
9:28
9:32
9:37
9:40
9:42
9:43
9:45
9:45
9:46
9:48
9:52
9:54
9:56
9:57
10:00
10:00
10:02
10:05
10:07
10:08
10:10
10:12
10:14
10:17
10:18
10:23
10:26
10:26
10:29
10:31
10:34
10:36
10:39
10:41
10:43
10:45
10:47
10:50
10:51
10:52
10:55
10:56
10:58
11:01
11:04
11:06
11:08
11:10
11:11
11:13
11:14
11:15
11:17
11:19
11:21
11:23
11:26
11:27
11:29
11:31
11:33
11:36
11:38
11:40
11:42
11:44
11:47
11:51
11:53
11:55
11:56
11:57
11:59
12:00
12:00
12:03
12:06
12:09
12:11
12:13
12:13
12:15
12:19
12:22
12:23
12:25
12:27
12:30
12:31
12:34
12:36
12:38
12:39
12:40
12:43
12:46
12:48
12:51
12:52
12:55
12:59
13:03
13:06
13:09
13:11
13:13
13:15
13:17
13:19
13:21
13:24
13:26
13:29
13:31
13:34
13:36
13:37
13:39
13:41
13:42
13:44
13:47
13:50
13:52
13:53
13:56
13:57
13:59
14:01
14:05
14:06
14:06
14:09
14:13
14:16
14:18
14:19
14:23
14:25
14:28
14:32
14:33
14:35
14:37
14:39
14:43
14:44
14:46
14:48
14:51
14:54
14:57
15:00
15:02
15:03
15:07
15:08
15:13
15:14
15:17
15:20
15:23
15:25
15:28
15:30
15:35
15:39
15:41
15:42
15:45
15:46
15:49
15:52
15:53
15:56
15:58
16:00
16:03
16:07
16:10
16:12
16:15
16:18
16:20
16:22
16:25
16:26
16:39
16:41
16:53
16:55
17:18
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Hola de nuevo a un episodio más de
BIMPRAXIS.
Hoy traemos para este episodio 52, dentro de
nuestra serie dedicada a los RAG, a los
Retrieval Augmented Generation, todo un hallazgo súper potente.
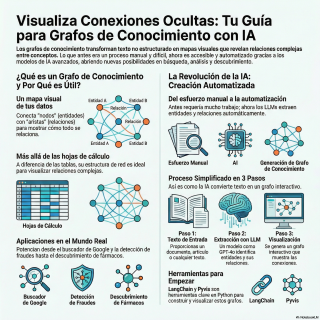
Los grafos como estrategia para estructurar la base
de conocimiento.
La idea de partida, la verdad, es de
esas que te atrapan.
Y si pudiéramos coger un montón de texto
desestructurado, un libro entero, un fajo de artículos,
una página de Wikipedia, y casi por arte
de magia, transformarlo en un mapa visual, un
mapa que nos muestre cómo está todo conectado.
Vamos, parece ciencia ficción.
Pero es que ya está aquí.
Y el objetivo de hoy es precisamente ese,
analizar cómo esta tecnología, que ha recibido un
impulso brutal gracias a los grandes modelos del
lenguaje, está cambiando las reglas del juego.
Y en particular, ¿cómo puede llevar a los
sistemas RAG que venimos explorando a un nivel,
bueno, a un nivel completamente nuevo?
Pues empecemos por lo más básico, porque el
término grafo de conocimiento puede sonar un poco
intimidante.
A mí se me ocurre una analogía que
creo que ayuda mucho a visualizarlo.
Imagina que tienes que explicarle la trama de
Juego de Tronos a alguien.
¡Uf, qué reto!
Menudo reto.
Podrías darle un resumen de mil páginas o
podrías mostrarle un mapa con los personajes, las
casas, sus alianzas, sus traiciones, las batallas.
Claro.
Con un solo vistazo, esa persona entendería la
red de relaciones que es, en realidad, el
corazón de la historia.
Es la analogía perfecta.
Porque eso es, en esencia, un grafo de
conocimiento.
Formalmente, diríamos que es una representación de entidades,
que son los nodos, y las relaciones que
hay entre ellas, que son las aristas.
Pero en la práctica es exactamente eso, un
mapa de conexiones.
Un nodo puede ser Jaime Lannister, otro Cersei
Lannister, y la arista que los une es
la relación hermano de, y también amante de.
Es una forma increíblemente intuitiva de representar el
conocimiento.
Espera, que aquí me surge la primera duda.
A primera vista, esto me suena a una
base de datos relacional de toda la vida,
pero muy compleja.
¿Qué es lo que realmente lo diferencia?
¿No podríamos con suficientes tablas y uniones conseguir
algo parecido?
Sospecho que la respuesta es no, pero no
veo claramente dónde está el límite.
Es la pregunta clave, y la diferencia es
fundamental.
Las bases de datos tradicionales, con sus tablas,
filas y columnas, son una estructura que llamamos
plana.
Son fantásticas para almacenar datos muy estructurados, como
un listado de clientes, por ejemplo.
Pero cuando intentas modelar relaciones complejas y, sobre
todo, heterogéneas como las de Juego de Tronos,
la cosa se dispara.
Necesitarías decenas de tablas, uniones complejísimas y las
consultas se volverían lentísimas e inmanejables.
Se convertiría en un monstruo.
Un monstruo, exactamente.
Un grafo, en cambio, nace para representar redes.
Su estructura nativa son los nodos y las
conexiones.
Esto no solo lo hace más visual, sino
computacionalmente mucho más eficiente para responder a ciertas
preguntas.
Preguntas como ¿cuáles?
Pues preguntas como ¿cuál es el camino más
corto entre este personaje y este otro?
O ¿quién es la persona más influyente de
esta red, la que tiene más conexiones importantes?
Esas son operaciones matemáticas que en un grafo
son naturales y en una base de datos
tradicional una auténtica pesadilla.
Entendido.
O sea, el grafo piensa en relaciones, la
base de datos en registros.
Y lo curioso es que, aunque suene a
tecnología de nicho, la estamos usando todos los
días sin darnos cuenta.
El ejemplo más claro es Google.
Buscas Albert Einstein y a la derecha no
solo te salen enlaces, te aparece esa caja
de información.
¿El Knowledge Panel?
Sí.
Exacto, con su foto, fechas y lo más
importante, datos conectados, su conyugue, sus hijos, los
premios que ganó, las universidades donde trabajó.
Totalmente.
Esa caja es la punta del iceberg del
gigantesco grafo de conocimiento de Google.
Es lo que le permite entender que Einstein
no es solo una cadena de texto, sino
una entidad conectada a teoría de la relatividad,
premio Nobel y física teórica.
Le permite dar respuestas factuales y con contexto,
no solo una lista de páginas que contienen
una palabra.
Y ver cómo Google lo usa para conectar
hechos me lleva directamente a los problemas que
hemos visto en los RAG tradicionales.
Un RAG estándar es como un bibliotecario muy
rápido.
Le pides algo sobre Apple Inc.
y te trae todos los documentos que lo
mencionan.
Es útil, sí, pero si le pides algo
como, ¿cuáles son los cinco temas estratégicos principales
de Apple discutidos en estos informes anuales de
la última década?
Se queda en blanco.
No puede sintetizar.
No ve el bosque.
Exacto.
El RAG tradicional es bueno encontrando agujas en
un pajar, pero no puede decirte cómo se
relacionan todas las agujas entre sí.
Se le escapan esas consultas que requieren conectar
ideas o eventos a través de múltiples documentos.
documentos.
Entonces, es aquí donde los grafos entran como
el súper bibliotecario que sí ve el panorama
completo.
Precisamente.
Aquí es donde nace el concepto de GraphRag.
El proceso cambia por completo.
En lugar de limitarnos a indexar fragmentos de
texto, el primer paso es construir un grafo
de conocimiento a partir de toda la documentación.
Un LLM lee todos los informes, artículos y
noticias e identifica automáticamente las entidades clave, personas,
productos, empresas, tecnologías, y extrae las relaciones entre
ellas.
O sea, que extrae cosas como Steve Jobs
cofundó Apple o Apple adquirió Next.
Justo.
O el iPhone revolucionó la industria móvil.
Todas esas conexiones.
O sea, primero creamos ese mapa de Juego
de Tronos, pero con los datos de la
empresa.
Exacto.
Y una vez tienes ese mapa, el juego
cambia.
Cuando un usuario pregunta por Apple, el sistema
ya no busca solo la palabra Apple.
Recupera el nodo Apple Inc.
y todo el subgrafo de información que está
conectado a él.
Ah, claro.
El LLM ya no recibe fragmentos de texto
sueltos, sino que recibe un contexto ya estructurado.
Se ancla, por así decirlo, en la estructura
del grafo.
Y supongo que eso le permite responder a
esas preguntas complejas que antes no podía.
De forma espectacular.
Para responder a tu pregunta de cuáles son
los cinco temas principales, el sistema puede analizar
el grafo, ver los clústeres o comunidades de
nodos más densos.
Clústeres.
Sí, grupos de nodos muy interconectados.
Podría encontrar un clúster sobre litigios de patentes,
otro sobre la cadena de suministro en China,
otro sobre el desarrollo del Vision Pro, y
a partir de ahí sintetizar una respuesta coherente
y estructurada.
Ya veo.
Pasamos de la recuperación de información a la
síntesis de conocimiento.
Es un salto cualitativo brutal.
Suena increíble en teoría, pero también me parece
que podría ser computacionalmente carísimo.
Construir y luego consultar un grafo así no
es mucho más lento que una simple búsqueda
semántica.
Es una objeción muy razonable.
La construcción inicial del grafo, el parsing de
todos los documentos, es un proceso intensivo que
se hace una sola vez o de forma
periódica.
Pero una vez construido, las consultas sobre el
grafo son, para muchas de estas preguntas complejas,
muchísimo más rápidas y eficientes que intentar que
un LLM razone sobre miles de fragmentos de
texto inconexos en tiempo real.
O sea, inviertes más al principio para ganar
velocidad y precisión después.
Exacto.
Y no solo se aplica a RAH.
Piensa en la detección de fraude, analizando redes
de transacciones para encontrar patrones anómalos, o en
el descubrimiento de fármacos, mapeando las relaciones entre
genes, proteínas y enfermedades.
Si son tan potentes, la pregunta es obligada.
¿Por qué estamos hablando de esto como una
revolución ahora?
¿Por qué no se usaban de forma masiva
hace 10 años?
Porque antes, construir uno era un trabajo de
chinos.
Era un proceso casi artesanal.
Requería equipos de expertos en un dominio concreto,
historiadores, biólogas, financieros, leyendo miles de documentos y
extrayendo manualmente cada entidad y cada relación.
Un cuello de botella carísimo en tiempo y
dinero.
Se intentarían crear atajos, supondo.
Claro.
Primero con sistemas basados en reglas, pero eran
muy rígidos.
Si cambiaba un poco el formato del texto,
todo se rompía.
Frágiles.
Muy frágiles.
Luego llegaron los primeros modelos de Machine Learning,
que mejoraron las cosas, pero tenían un alcance
limitado.
Funcionaban bien para textos muy específicos, casi siempre
en inglés, y se perdían con la ambigüedad
y los matices del lenguaje.
Y entonces llegaron los LLMS modernos y lo
cambiaron todo.
Cambiaron las reglas del juego por completo.
Un modelo como GPT-4O puede leer texto en
múltiples idiomas, entender el contexto, el sarcasmo, las
relaciones implícitas y hacer ese trabajo de extracción
de forma automática y a una escala que
antes era impensable.
Es que esto es lo que lo cambia
todo.
Totalmente.
Recuerdo haber intentado hacer algo parecido hace años
para un proyecto personal, mapeando personajes de novelas.
Fue un trabajo manual de semanas y lo
abandoné por pura extenuación.
Ver que ahora se puede hacer con un
clic es un poco deprimente y alucinante a
la vez.
Te entiendo perfectamente.
Vi una demostración con una herramienta de NeoFatch
que era casi insultante, de lo fácil que
parecía.
Se pegaba el texto de la Wikipedia de
Juego de Tronos y al instante tenías en
pantalla un grafo interactivo.
En el centro, Juego de Tronos, y conectados
a él nodos de colores con datos.
el número de episodios, los premios, los libros.
Se podía explorar toda la saga visualmente.
Era una pasada.
Esa demostración es el ejemplo perfecto de la
democratización de esta tecnología.
Lo que antes costaba meses de trabajo de
un equipo de doctorandos, ahora se puede prototipar
en segundos con las herramientas adecuadas.
Vale, pues vamos a meternos un poco más
en la parte técnica para quienes les gusta
trastear con el código.
El proceso de convertir, por ejemplo, el primer
párrafo de la Wikipedia de Einstein en un
grafo.
¿Cómo funciona por debajo?
Pues mira, principalmente hay dos maneras de pedirle
a un LLM que haga esto.
La primera es la más directa.
Le escribes un prompt muy detallado pidiéndole extrae
todas las personas, lugares y conceptos de este
texto y devuélvemelos en formato JSON con nodos
y relaciones.
Es el enfoque basado en prompts.
¿Y el problema es?
Que los LLMs a veces son un poco
creativos, digamos.
Exacto.
No tienes ninguna garantía de que la salida
sea siempre un JSON válido y con la
estructura exacta que necesitas.
A veces puede añadir un comentario, olvidar una
coma y tu código se rompe.
Es inconsistente.
¿Y la alternativa más robusta?
La alternativa es el enfoque de salida estructurada,
o lo que a veces se llama function
calling, que soportan los modelos más avanzados.
Es la diferencia entre dar instrucciones vagas y
entregar un plano detallado.
A ver, en lugar de pedirle un texto,
defines un esquema formal.
La salida debe ser una lista de objetos
nodo y cada nodo debe tener un ID
de tipo string y un tipo de tipo
string.
Y lo mismo para las relaciones.
Ah, vale.
O sea, obligas al modelo a rellenar tu
plantilla.
Justo.
Lo fuerzas a seguir tu esquema.
El resultado es una salida increíblemente fiable y
consistente, lista para ser usada por tu programa
sin miedo a errores de formato.
Siempre que se pueda, es el camino a
seguir.
Para los que no queremos pelearnos con todo
eso, existen librerías como Landchain con herramientas como
el LLM Graph Transformer, que básicamente es una
caja negra a la que le das texto
y te devuelve el grafo ya hecho.
Es una maravilla de abstracción.
Esa herramienta mira qué LLM estás usando y
decide por ti.
Si soporta salida estructurada, la usa.
Si no, utiliza un sistema de prompts muy
robusto por debajo.
Te quita toda la complejidad.
O sea que el proceso es tan simple
como… ¿Cómo lo describes?
Instalas las librerías, configuras tu LLM con tu
clave de API, le pasas el texto de
Einstein al transformador y ya está.
Y lo que te devuelve es una lista
de nodos como Albert Einstein, tipo persona, y
una lista de relaciones como sujeto Albert Einstein,
relación, desarrolló objeto, teoría de la relatividad.
Exacto, y con eso ya puedes usar una
librería como PyBIS para pintar ese mapa interactivo
de la vida de Einstein, con las personas
en azul, las organizaciones en verde.
Es cuando lo ves visualmente que el concepto
realmente hace clic, lo que me lleva a
un problema práctico.
El primer grafo que generé para probar esto,
sobre Einstein, era un poco caótico.
Una bola de pelo, como se suele decir,
de nodos y líneas, con muchísima información.
¿Qué pasa si solo me interesan, por ejemplo,
sus afiliaciones académicas y no su vida personal?
¿Cómo evitamos que el grafo se llene de
ruido?
Es un punto fundamental.
Un grafo no es mejor por tener más
nodos.
Es mejor por tener los nodos y relaciones
correctos para tu objetivo.
La solución es guiar y restringir al LLM
durante la extracción.
¿Cómo?
¿Añadiendo más instrucciones al prompt?
Exactamente.
En herramientas como la de LandChain puedes pasarle
parámetros muy específicos.
Por ejemplo, una lista de Allowed Nodes.
¿Nodos permitidos?
Vale.
Y ahí le dices, solo me interesan los
nodos de tipo persona, universidad y publicación.
Todo lo demás lo ignoras.
Y puedes ser aún más precisa con las
relaciones.
Puedes definir una lista de Allowed Relationships y
especificar patrones completos.
Por ejemplo, solo quiero relaciones que sigan la
estructura Persona trabajó en universidad o Persona publicó
publicación.
Ah, claro.
De esa forma, en lugar del mapa completo
de la vida de Einstein, creas un grafo
específico y enfocado en su carrera académica, mucho
más limpio y útil.
Precisamente.
Y para un sistema RAG, este paso de
refinamiento es absolutamente crucial.
Si alimentas al RAG con un grafo ruidoso
y lleno de conexiones irrelevantes, sus respuestas serán
igual de ruidosas y desenfocadas.
Curar el grafo es curar la calidad de
las respuestas futuras.
Entonces, si recapitulamos el viaje, hemos pasado de
un simple bloque de texto a un mapa
de conocimiento estructurado, interactivo y, sobre todo, útil.
Y esto no es solo un adorno visual,
Es una forma radicalmente más potente de estructurar
el conocimiento para que sistemas de IA como
los RAG puedan razonar sobre él.
Si lo conectamos con la idea general, estamos
presenciando el paso de la recuperación de información
a la síntesis de conocimiento.
Ya no buscamos documentos, buscamos respuestas, conexiones, patrones.
Estamos construyendo un cerebro digital sobre nuestros datos,
una capa de inteligencia que entiende las relaciones
que hay en ellos.
Construir un cerebro digital sobre nuestros datos es
una idea muy potente.
Y nos deja con una reflexión final.
Si esta técnica nos permite mapear los conceptos
de un libro o de todo un campo
científico, ¿qué pasaría si la aplicáramos a nuestros
propios datos?
A nuestras notas personales, a los correos electrónicos
del trabajo, a los documentos de un proyecto.
¿Qué conexiones ocultas sobre nuestras propias ideas, sobre
la forma en que colaboramos, podríamos descubrir?
Quizás el próximo gran avance no venga de
encontrar nueva información, sino de entender por fin
las relaciones profundas que ya existen en la
información que generamos cada día.
Llegamos al final por hoy.
El podcast BIMPRAXIS está dirigido por un humano,
Julio Pablo Vázquez.
Os esperamos en el próximo episodio.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.
¡Suscríbete al canal!