Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:10
0:15
0:20
0:23
0:26
0:28
0:37
0:38
0:40
0:44
0:47
0:51
0:54
0:57
0:59
1:02
1:05
1:07
1:09
1:11
1:14
1:15
1:19
1:21
1:24
1:27
1:30
1:31
1:32
1:34
1:37
1:38
1:39
1:41
1:42
1:43
1:44
1:47
1:49
1:52
1:52
1:55
1:56
2:00
2:03
2:04
2:05
2:06
2:09
2:11
2:14
2:15
2:17
2:19
2:21
2:24
2:27
2:28
2:30
2:30
2:33
2:35
2:37
2:38
2:40
2:41
2:44
2:47
2:49
2:52
2:55
2:57
3:00
3:01
3:02
3:05
3:07
3:09
3:10
3:13
3:14
3:18
3:20
3:23
3:25
3:28
3:28
3:30
3:33
3:34
3:36
3:38
3:39
3:41
3:44
3:46
3:48
3:51
3:52
3:54
3:56
4:00
4:01
4:03
4:07
4:09
4:11
4:13
4:15
4:17
4:20
4:22
4:24
4:25
4:27
4:29
4:31
4:32
4:34
4:35
4:38
4:40
4:43
4:44
4:46
4:47
4:50
4:52
4:55
4:56
5:00
5:02
5:05
5:07
5:08
5:10
5:13
5:14
5:17
5:19
5:21
5:23
5:26
5:29
5:31
5:34
5:37
5:40
5:41
5:44
5:46
5:46
5:50
5:52
5:55
5:57
6:00
6:02
6:05
6:08
6:09
6:10
6:12
6:16
6:18
6:20
6:21
6:23
6:26
6:27
6:29
6:31
6:33
6:36
6:38
6:40
6:41
6:42
6:45
6:46
6:49
6:50
6:52
6:54
6:57
6:59
7:02
7:06
7:09
7:12
7:16
7:19
7:21
7:25
7:26
7:28
7:31
7:32
7:36
7:38
7:40
7:42
7:43
7:46
7:49
7:50
7:52
7:58
8:01
8:05
8:08
8:11
8:13
8:14
8:16
8:18
8:20
8:22
8:23
8:25
8:29
8:31
8:34
8:37
8:38
8:39
8:41
8:43
8:46
8:48
8:49
8:52
8:55
8:57
8:58
9:00
9:01
9:04
9:06
9:09
9:12
9:14
9:17
9:19
9:22
9:25
9:37
9:39
9:50
9:53
10:16
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas.
Episodio 48.
Hoy continuamos nuestra serie sobre herramientas open source
gratuitas relacionadas con la inteligencia artificial.
Y la de hoy es especialmente interesante para
cualquiera que trabaje con modelos de lenguaje grandes.
Hoy vamos a analizar a fondo VLLM.
Bienvenidos al podcast de BIMPRAXIS.
Nuestra misión hoy es desentrañar por qué esta
herramienta está causando tanto revuelo.
Tenemos como fuente el paper original de sus
creadores en UC Berkeley y también, claro, la
documentación del proyecto.
Vale, vamos a empezar a desgranar esto.
Lo primero que llama la atención es el
problema que VLLM intenta resolver.
Ejecutar estos modelos de lenguaje gigantescos es carísimo.
Una de las fuentes estima que procesar una
petición a un LLM puede ser, ojo, 10
veces más caro que una búsqueda de palabras
clave tradicional.
Exacto.
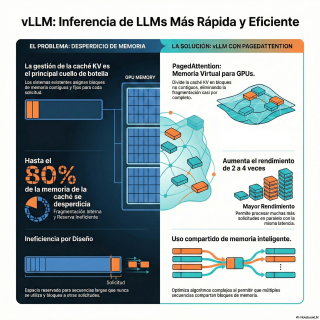
Y el principal cuello de botella, que es
lo interesante, no es siempre la capacidad de
cálculo.
No.
Uno pensaría que es la potencia bruta de
la máquina.
Pues no siempre.
Es la memoria.
La memoria de las GPUs.
Pensemos en una GPU potente como la NVIDIA
A100, con 40 GB de memoria, que es
el ejemplo que usan.
El paper nos da un desglose que es
muy revelador.
Aproximadamente el 65% de esa memoria se va
solo en almacenar los pesos del modelo.
Que son estáticos, ¿no?
No cambian.
Eso es, son estáticos.
Pero casi un 30% se destina a algo
llamado la caché caure.
Y esta, esta es la clave de todo.
Caché KV.
Suena técnico, pero es fundamental.
Es básicamente la memoria a corto plazo del
modelo para una conversación.
Cuando generas texto, el modelo necesita recordar el
contexto, las palabras anteriores, para saber qué viene
después.
Esa memoria es la caché KV.
Justo.
El problema es que es dinámica.
Crece con cada nueva palabra generada y su
tamaño final.
Es impredecible.
Totalmente impredecible.
Y ahí está el gran reto.
Los sistemas tradicionales para gestionar esta memoria recurrían
a una solución, digamos, poco eficiente.
¿Qué hacían exactamente?
Reservaban un bloque de memoria contiguo y enorme
para cada petición, pensando siempre en la longitud
máxima posible de la respuesta.
Por ejemplo, 2048 tokens.
Ahí es donde la cosa se pone de
verdad interesante.
Esta solución es como reservar un autobús entero
para una sola persona por si acaso decide
invitar a 50 amigos por el camino.
Esa es la analogía.
Y el resultado, según los datos del estudio,
es un desperdicio masivo.
En sistemas como Faster Transformer u Orca, solo
entre el 20% y el 40% de la
memoria de la caché KTV se usa realmente
para almacenar información útil.
¿Un momento, solo un 20 o 40%?
Sí, sí.
El resto se pierde por lo que llaman
fragmentación interna y externa.
Es un desperdicio enorme.
Madre mía.
Vayamos entonces a la solución, que me parece
fascinante.
Lo que es fascinante aquí es la solución
que proponen los creadores de VLM llamada Paged
Attention.
La inspiración viene de un concepto clásico de
los sistemas operativos, la memoria virtual y la
paginación.
Una idea brillante.
O sea, no están inventando la rueda, sino
aplicando un concepto superprobado a un problema nuevo.
Totalmente.
En lugar de exigir un gran bloque de
memoria contiguo, Paged Attention divide la caché KB
en pequeños bloques de tamaño fijo.
Como si fueran páginas de un libro.
Esa es la analogía perfecta.
Es como si en lugar de necesitar una
estantería vacía y larguísima para un libro que
aún no se ha escrito, simplemente vas añadiendo
páginas sueltas donde encuentres hueco.
Y tienes un índice que te dice dónde
está cada una.
Y los asigna dinámicamente a medida que se
generan nuevas palabras.
Y esto elimina casi por completo la fragmentación,
claro.
Casi por completo.
La memoria no utilizada es mínima.
Se confina al último bloque de cada secuencia.
Y como todos los bloques tienen el mismo
tamaño, se pueden reutilizar de forma muy, muy
eficiente.
Vale, ¿y todo esto en qué se traduce
en la práctica?
¿Qué gana alguien que use VBLM?
Pues el resultado directo es un aumento espectacular
del rendimiento, el throughput.
¿De cuánto estamos hablando?
Las evaluaciones del paper muestran que VBLM consigue
entre 2 y 4 veces más rendimiento que
otros sistemas de última generación, y esto con
el mismo nivel de latencia.
¿2 a cuatro veces.
Es una barbaridad.
Permite procesar muchas más peticiones simultáneamente en la
misma GPU.
Simplemente porque aprovecha la memoria de una forma
mucho más inteligente.
Y no es solo una cuestión de no
desperdiciar memoria.
Esta arquitectura de páginas o bloques abre la
puerta a optimizaciones muy ingeniosas, ¿verdad?
Sí, y esto conecta con el panorama general.
Permite compartir memoria de forma muy flexible.
Por ejemplo, en el muestreón paralelo, cuando pides
al modelo varias posibles respuestas a un mismo
prompt.
Claro, todas las respuestas comparten el contexto inicial.
El prompt es el mismo.
Eso es.
Con BLLM, todas esas secuencias pueden apuntar a
los mismos bloques de memoria física para el
prompt, ahorrando una cantidad significativa de espacio.
¿Y se cuantifica ese ahorro?
Sí, el estudio lo cuantifica entre un 6
y un 10% en sus experimentos.
¿Y mencionan un mecanismo llamado copia en escritura,
o copy and write, otro concepto de los
sistemas operativos?
Correcto.
Cuando una de las secuencias necesita modificar un
bloque compartido, en lugar de alterarlo para todas…
El sistema crea una copia de ese bloque
solo para esa secuencia.
Tremendamente eficiente, sí.
Y esto se vuelve aún más potente en
algoritmos más complejos como la búsqueda por haz,
Beam Search.
Donde hay muchos candidatos a mejor respuesta que
comparten gran parte de su historia.
Ahí el ahorro de memoria, según el paper,
puede llegar a ser superior al 55%.
Más del 55%.
Es un cambio de paradigma total.
Desde luego.
Y por lo que veo en la documentación
del proyecto, VLM no es solo un concepto
académico.
Es un proyecto de código abierto muy activo.
Sí, empezó en UC Berkeley, pero ahora es
totalmente comunitario.
ofrece integración con los modelos más populares de
Hugging Face, una API compatible con la de
OpenAI para facilitar la adopción, lo cual es
un movimiento muy inteligente para que la gente
lo pueda probar y migrar fácilmente, y funciona
en una variedad de hardware impresionante.
GPUs de NVIDIA y AMD e incluso soporte
para hardware de Intel, IBM o Google.
Además, esta arquitectura de gestión de memoria resuelve
otros casos de uso comunes.
Por ejemplo, las peticiones que comparten un prefijo
común.
Como una serie larga de instrucciones o ejemplos
que se repiten para diferentes usuarios, te refieres.
Justo.
Con VBLM, la caché KV de ese prefijo
se puede calcular una sola vez y reutilizar
para todas las peticiones.
Acelerando enormemente el proceso.
Muchísimo.
Los experimentos con un modelo de traducción muestran
mejoras de hasta 3.5 veces en el rendimiento
gracias a esto.
Es una optimización muy potente.
Entonces, resumiendo, VLLM ataca un problema fundamental, la
ineficiencia de la memoria en la inferencia de
LLMs, con una solución elegante, inspirada en décadas
de conocimiento en sistemas operativos y los resultados
son, bueno, espectaculares.
Y esto plantea una pregunta importante de cara
al futuro.
El paper señala que la velocidad de computación
de las GPUs crece más rápido que su
capacidad de memoria.
El cuello de botella de la memoria es
cada vez más crítico.
Cada vez más.
VLLM lo soluciona a nivel de software.
La pregunta a reflexionar es, ¿deberían los futuros
diseños de hardware para IA incorporar de base
principios de gestión de memoria no contigua como
la paginación?
Es una gran pregunta.
¿Podríamos estar viendo el principio del fin de
la idea de que los grandes tensores de
datos deben residir siempre en bloques contiguos de
memoria para ser eficientes?
Quizá.
BLM ha demostrado que hay otro camino, uno
mucho más eficiente, y puede que el hardware
del futuro tenga que empezar a pensar de
esta manera.
Y así hemos llegado al final de nuestro
episodio de hoy.
Os recordamos que detrás de las voces sintéticas
que escucháis en estos episodios, y que están
generadas con Notebook LM, pues en la trastienda
está un humano con meñiques, muñecas y riñones,
entre otras cosas, que no es otro que
Julio Pablo Vázquez, el que dirige el podcast.
Si escuchas algún error, el error será humano
en un 99% de los casos.
Ya sabes a quién pedir explicaciones.
Hasta la próxima, amigos.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.
¡Suscríbete al canal!