Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:09
0:15
0:20
0:23
0:26
0:28
0:36
0:41
0:43
0:46
0:47
0:49
0:51
0:55
0:57
0:59
1:03
1:05
1:07
1:09
1:11
1:13
1:16
1:17
1:19
1:19
1:22
1:25
1:28
1:30
1:32
1:35
1:38
1:41
1:44
1:48
1:49
1:51
1:54
1:55
1:56
1:59
2:01
2:02
2:03
2:06
2:06
2:11
2:12
2:16
2:17
2:19
2:20
2:22
2:25
2:27
2:29
2:30
2:31
2:32
2:37
2:41
2:43
2:46
2:47
2:50
2:51
2:52
2:55
2:56
2:59
3:02
3:04
3:07
3:08
3:09
3:12
3:14
3:15
3:17
3:18
3:19
3:21
3:24
3:26
3:27
3:29
3:32
3:33
3:36
3:37
3:38
3:40
3:43
3:44
3:46
3:47
3:47
3:50
3:53
3:55
3:56
3:59
4:01
4:03
4:05
4:06
4:09
4:11
4:13
4:17
4:17
4:20
4:21
4:24
4:27
4:30
4:33
4:35
4:36
4:38
4:41
4:42
4:45
4:47
4:48
4:48
4:50
4:52
4:55
4:56
4:58
5:02
5:04
5:07
5:08
5:12
5:14
5:16
5:17
5:18
5:20
5:21
5:24
5:26
5:28
5:31
5:31
5:33
5:35
5:38
5:40
5:41
5:43
5:47
5:47
5:50
5:51
5:53
5:54
5:55
5:58
5:59
6:02
6:03
6:05
6:08
6:10
6:12
6:13
6:16
6:17
6:17
6:20
6:23
6:25
6:28
6:30
6:33
6:34
6:37
6:40
6:43
6:45
6:47
6:49
6:51
6:51
6:55
6:58
7:01
7:05
7:08
7:09
7:11
7:14
7:17
7:19
7:21
7:23
7:24
7:26
7:28
7:31
7:33
7:36
7:38
7:41
7:44
7:47
7:47
7:51
7:52
7:54
7:57
8:00
8:03
8:05
8:06
8:07
8:09
8:12
8:14
8:17
8:17
8:17
8:20
8:20
8:22
8:24
8:25
8:25
8:27
8:30
8:32
8:34
8:35
8:37
8:39
8:41
8:41
8:44
8:45
8:47
8:49
8:51
8:52
8:56
8:59
9:02
9:05
9:08
9:12
9:15
9:16
9:18
9:20
9:22
9:23
9:25
9:27
9:29
9:31
9:35
9:38
9:40
9:42
9:44
9:45
9:46
9:50
9:52
9:54
9:58
10:00
10:01
10:05
10:07
10:09
10:11
10:12
10:25
10:27
10:38
10:40
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura, ingeniería y
construcción.
¡Empezamos!
Muy buenas, bienvenidas y bienvenidos al episodio 46
del podcast de BIMPRAXIS.
Continuamos con nuestra serie sobre herramientas open source
gratuitas.
Y hoy os traemos algo que la verdad
es una pasada.
Vamos a analizar una herramienta llamada unstructured .io.
Imaginad por un momento todo el conocimiento que
acumula una empresa.
Informes en PDF, presentaciones, documentos de Word, correos…
Es un mar de datos.
El problema es que la mayor parte está,
como se dice, desestructurado.
O sea que es un caos para que
una inteligencia artificial lo entienda.
Hoy vamos a ver cómo unstructured .io busca
solucionar justo eso.
Vamos allá.
Exacto.
El objetivo es convertir ese caos de datos
en un recurso que de verdad aporte valor.
Y veremos cómo esta herramienta, unstructured, sirve de
base para una tecnología que está en boca
de todos, que se llama RAG.
Esta tecnología permite que las IAs respondan preguntas
usando información privada y actualizada de una empresa.
Y, muy importante, de forma segura.
Bien, pues vamos a desgranar todo esto.
Para empezar, yendo al grano, ¿qué es exactamente?
Unstructured, por lo que he visto en las
fuentes, es un proyecto de código abierto que
ya tiene más de 50 millones de descargas.
Correcto.
No es algo pequeño, para nada.
Su función principal es, a mí me gusta
llamarlo, fontanería de datos.
Fontanería de datos.
Me gusta.
Sí, porque coge documentos de cualquier tipo, de
verdad.
Un PDF, un .docx, un HTML, incluso imágenes.
Y los procesa.
Extrae el texto, las tablas, los títulos, todo.
Y lo convierte en un formato de documento.
Un formato limpio y estructurado, que suele ser
JSON.
Y este es el primer paso, el que
es indispensable para que las IAs puedan, digamos,
leer y entender esa información.
Y esto nos lleva a las siglas que
has mencionado antes.
RAG.
¿Qué es exactamente?
Pues RAG son las siglas de Retrieval Augmented
Generation, o en español, Generación Aumentada por Recuperación.
Es una técnica que soluciona uno de los
mayores problemas de los grandes modelos de lenguaje,
los LLM.
Que su conocimiento es estático, ¿no?
Se queda obsoleto.
Justo.
Se queda obsoleto y, sobre todo, no tienen
acceso a datos privados.
RAG lo que permite es que cuando alguien
hace una pregunta, el sistema busque la información
más relevante en una base de datos privada.
Una base de datos creada con los documentos
que ha procesado Unstructured.
Exacto.
Y le entrega esos trocitos de información al
LLM en ese momento para que construya la
respuesta.
El ejemplo del material es muy claro.
Ah, sí, el de Twitter.
Claro.
Un chatbot sin RAG podría decirte que Twitter
todavía existe, mientras que uno con RAG, conectado,
por ejemplo, a Wikipedia, sabría que ahora se
llama X.
En uno de los seminarios web que hemos
analizado, comentan algo que me ha llamado la
atención.
Mencionan que ha habido rumores sobre que el
RAG está muerto.
¿Es así?
Uf, ese es el gran mito.
Las fuentes lo desmienten, pero vamos, categóricamente.
Ya me imaginaba.
No solo no está muerto, sino que está
empleado.
Es una plena expansión.
Es que, a ver, se cita una previsión
de Grandview Research que proyecta un crecimiento anual
de casi el 40 % hasta 2030.
¿Una barbaridad?
Es que hablamos de un mercado que alcanzaría
más de 10 mil millones de dólares.
O sea que no está muerto.
¿Y por qué es tan popular en el
mundo de la empresa?
¿Qué es lo que ven en esta tecnología?
Pues la razón principal, y esto es clave,
es la seguridad.
Ah, no tanto el tener los datos actualizados.
Eso es el gancho.
Pero lo de fondo es la seguridad.
Piensa en esto.
Si una empresa reentrenara un modelo de inteligencia
artificial con todos sus datos sensibles, de finanzas
o de recursos humanos, sería un desastre.
Destruiría todos los controles de acceso.
Con RAG, los datos se quedan en la
base de datos de la empresa.
No salen de ahí.
El sistema solo recupera los fragmentos que necesita
para cada consulta.
Y mantiene la trazabilidad y los permisos.
De hecho, se habla del problema de...
El problema es el espejo de control de
acceso.
La idea es que si un empleado no
puede ver una carpeta en el sistema de
origen, tampoco debería poder consultarla a través del
sistema RAG.
Claro, tiene todo el sentido.
Entonces, ¿cómo funciona a grandes rasgos este proceso?
Pues tiene dos fases principales.
Primero, una fase que llaman offline, que es
la de preparación.
Ahí es donde Unstructured procesa los documentos, los
divide en fragmentos, los chunks...
Y los convierte en vectores.
Eso es.
En representaciones matemáticas.
Y los carga en una base de datos
vectorial.
Y luego está la segunda fase, la online,
que es cuando alguien pregunta.
Ahí se busca en esa base de datos
los fragmentos más relevantes para responder.
Vale.
Y aquí es donde la cosa se pone
realmente interesante.
Porque las fuentes hablan de una evolución.
Parece que no todos los sistemas RAG son
iguales.
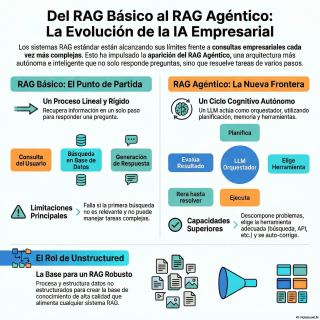
Se empieza por un RAG ingenuo y se
puede llegar a algo que llaman RAG agéntico.
Exacto.
El RAG básico, o ingenuo, es un proceso
lineal.
Busca, recupera y genera.
Punto.
Tiene una sola oportunidad.
Si la primera búsqueda no da buenos resultados,
el sistema falla.
Y supongo que no puede con tareas complejas.
Para nada.
No puede resolver algo que requiera múltiples pasos
o consultar distintas fuentes de datos.
El RAG agéntico es el siguiente nivel.
Aquí, el modelo de IA no es solo
un generador de texto.
Es más bien un orquestador que razona.
Un orquestador.
Sí.
Puede descomponer una pregunta compleja en subtareas.
Puede elegir la herramienta adecuada para cada una.
Buscar en la base de datos, consultar una
API en tiempo real, hacer una búsqueda web.
Y lo más importante, puede evaluar sus propios
resultados y autocorregirse si falla en el primer
intento.
Es como la diferencia entre preguntarle a un
bibliotecario por un libro concreto y encargarle a
un asistente de investigación un informe complejo.
Esa es la analogía perfecta.
El asistente puede ir a la biblioteca.
Buscar envases de datos online.
Hacer llamadas si es necesario.
Precisamente.
Y bueno, existe todo un espectro de autonomía.
Desde un simple enrutador, que solo dirige las
preguntas a la fuente de datos correcta, hasta
sistemas que llaman de enjambres multiagente, que colaboran
para resolver tareas muy, muy complejas.
Entendido.
Entonces, volviendo a la herramienta principal.
¿Qué significa todo esto para alguien que quiera
implementar estas soluciones?
¿Cómo le ayuda Unstructured a evitar lo que
en las fuentes llaman, y me encanta la
expresión, el nido de ratas del hazlo tú
mismo?
Es que la expresión es buenísima porque describe
una realidad muy común.
Ese nido de ratas es el caos que
se produce cuando cada equipo de una empresa
crea sus propias chapuzas para procesar datos.
Claro, cada uno por su lado.
Sin estandarización, sin seguridad, sin calidad.
Unstructured lo que ofrece es una plataforma centralizada
para gestionar todo ese proceso de ingesta y
transferencia.
Una especie de tubería única y robusta.
Justo.
Proporciona las herramientas para procesar decenas de tipos
de archivos, y usa una estrategia que llaman
de particionamiento de alta resolución, y luego aplica
enriquecimientos con modelos de visión por lenguaje, los
VLMs.
¿Enriquecimientos?
¿Qué tipo de cosas hace?
Pues, por ejemplo, puede generar descripciones de las
imágenes que hay en un documento, o mejorar
la precisión del texto con OCR generativo.
O, y esto es muy útil, convertir tablas
en un documento.
O, y esto es muy útil, convertir tablas
complejas a un formato HTML limpio y fácil
de usar.
Suena muy potente.
¿Y todo esto se puede usar de forma
sencilla?
Sí.
Las fuentes destacan dos formas de uso.
Una es una interfaz de usuario muy visual,
donde puedes arrastrar un archivo y ver los
resultados en segundos.
En la demo se ve con un PDF
de una inmobiliaria y es una pasada.
¿Y la otra será para un uso más
a gran escala, imagino?
Exacto.
Una API para integrarlo en flujos de trabajo
de forma programática.
Se encarga de todo el trabajo sucio para
que los equipos de desarrollo puedan centrarse en
construir los sistemas de IA, no en la
fontanería.
En resumen, entonces, Unstructured .io se posiciona como
una pieza fundamental de código abierto para poner
orden en el caos de los datos empresariales.
Es como la infraestructura esencial que permite construir
después sistemas de IA avanzados, como los de
RAG y RAG agéntico, que pueden entender y
utilizar el conocimiento interno de una organización.
De forma segura y eficaz.
Esa es la idea central, sí.
Y aquí me gustaría dejar una reflexión final
que se deriva de todo esto.
Adelante.
Hemos hablado de agentes de IA que usan
datos para responder preguntas.
Pero a medida que estos sistemas se vuelven
más autónomos y son capaces no sólo de
recuperar información, sino de ejecutar acciones, ¿qué nuevos
desafíos de gobernanza y control surgirán?
Quiero decir, ¿qué pasa cuando una IA no
sólo puede leer todos los datos de una
empresa, sino también actuar en base a ellos
usando otras herramientas?
Es algo en lo que pensar.
Una pregunta muy potente para terminar, desde luego.
Y con esto llegamos a la despedida.
Como siempre, queremos recordaros que detrás de las
voces sintéticas que escucháis en estos episodios, creadas
gracias a la IA de Notebook LM, se
encuentra un humano.
Un humano con lóbulos auriculares, párpados y trompas
de eustaquio, entre otras cosas.
Concretamente, Julio Pablo Vázquez.
Si detectáis algún error, casi seguro que es
humano.
Os esperamos en el próximo episodio.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.