Buenas, esto es BIMPRAXIS, el podcast donde el
Download transcript (.srt)
0:10
0:13
0:20
0:23
0:25
0:28
0:38
0:41
0:43
0:44
0:47
0:48
0:50
0:52
0:54
0:56
0:58
1:27
2:01
2:12
2:14
2:16
2:17
2:20
2:21
2:23
2:26
2:27
2:29
2:31
2:34
2:37
2:40
2:42
2:43
2:44
2:47
2:51
2:54
2:56
2:58
3:00
3:03
3:05
3:07
3:09
3:13
3:15
3:16
3:18
3:20
3:24
3:26
3:29
3:32
3:35
3:39
3:41
3:44
3:47
3:48
3:50
3:53
3:54
3:57
4:00
4:02
4:04
4:05
4:07
4:08
4:10
7:07
7:09
7:12
7:12
7:15
7:18
7:19
7:23
7:24
7:27
7:29
7:32
7:34
7:38
7:40
7:41
7:44
7:47
7:50
7:50
7:54
7:57
7:59
8:01
8:04
8:06
8:06
8:13
8:19
8:24
8:27
8:29
8:32
8:35
8:37
8:43
8:46
8:49
8:52
8:55
8:59
9:02
9:05
9:09
9:11
9:13
9:16
9:17
9:21
9:23
9:25
9:27
9:45
10:12
10:28
10:31
10:32
10:34
10:37
10:38
10:41
10:44
10:48
10:50
12:03
12:22
12:24
12:27
12:30
12:31
12:33
12:35
12:37
12:40
12:43
12:45
12:48
12:50
12:53
12:56
12:58
13:11
13:21
13:28
13:38
13:47
13:55
13:56
13:59
13:59
14:02
14:05
14:07
14:09
14:12
14:14
14:18
14:21
16:29
16:57
17:00
17:03
17:06
17:08
17:11
17:13
17:20
17:28
17:33
17:41
17:46
17:46
BIM se encuentra con la inteligencia artificial.
Exploramos la ciencia, la tecnología y el futuro
desde el enfoque de la arquitectura,
ingeniería y construcción.
¡Empezamos! Hola y bienvenidos.
Gracias por acompañarnos en este nuevo episodio del
podcast de BIMPRAXIS.
Hoy vamos a meternos en un tema que,
hasta hace no mucho, sonaba a ciencia ficción,
pura y dura.
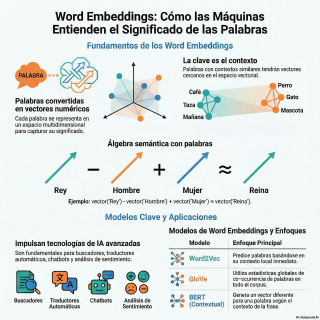
¿Cómo es posible que una máquina entienda el
significado de una palabra?
No que la reconozca o la repita,
sino que entienda su esencia,
su relación con otras.
Es una pregunta fascinante, la verdad.
La distancia entre ellas representa la similitud de
su significado.
Entiendo. Es como un mapa conceptual,
pero generado matemáticamente.
Pero aquí me surge una duda.
Un mapa normal tiene dos dimensiones,
tres a lo sumo.
Pero en las fuentes se habla de espacios
de 100, 300 o incluso más dimensiones.
¿Cómo se mide la distancia ahí?
No puedes usar una regla, ¿no?
Esa es la pregunta clave.
Y la respuesta es sorprendentemente elegante.
En lugar de medir la distancia en línea
recta, que puede ser engañosa en tantas dimensiones,
lo que se mide es el ángulo entre
los vectores.
¿El ángulo?
Sí. El artículo de IBM lo detalla muy
bien, con el concepto de similitud del coseno.
Imagina dos flechas que parten del mismo punto,
se apuntan casi en la misma dirección,
el ángulo entre ellas es muy pequeño y
su similitud del coseno es cercana a 1.
Lo que significa que son semánticamente parecidas.
Justo. Ah, claro.
Así que océano y mar serían dos vectores
con un ángulo minúsculo entre ellos.
Precisamente. Si los vectores son perpendiculares,
un ángulo de 90 grados,
su similitud es cero.
No tienen nada que ver,
como democracia y tornillo, y se apuntan en
direcciones opuestas, las similitudes menos uno,
lo que indicaría que son antónimos.
Vale, es una forma muy eficiente de capturar
estas relaciones complejas, sin importar las dimensiones.
Eso es. El modelo aprende a orientar los
vectores según el significado que extrae del texto.
Y ese es el siguiente paso.
¿Cómo aprende la máquina a crear este mapa,
porque alguien no se sienta a colocar río
cerca del agua a mano?
Las fuentes dicen que el truco está en
alimentarlo con cantidades masivas de texto.
Con toda la Wikipedia, por ejemplo.
Claro. Ahí entra en juego lo que se
conoce como la hipótesis distribucional,
una idea que es la base de todo
esto, y que se resume en una frase
famosa.
Sabrás lo que es una palabra por las
compañías que frecuenta.
Me gusta esa frase.
El modelo no aprende conceptos. Aprende relaciones.
La relación entre hombre y mujer es un
cierto vector, una dirección y una distancia en
ese espacio.
Y resulta que esa misma flecha vectorial es
la que conecta rey con reina o tío
con tía.
El modelo captura la relación masculino-femenino como una
dirección constante.
Fascinante. Y lo que es más increíble,
y esto lo detallan en el paper,
es que no se limita a analogías semánticas.
También captura relaciones sintácticas.
Por ejemplo, la relación entre caminar y caminando
es el mismo vector que la que hay
entre correr y corriendo.
O sea, captura el concepto de gerundio.
Justo. Para probar esto, los autores crearon un
conjunto de pruebas con miles de estas preguntas
de analogías.
Por primera vez, se podía medir objetivamente la
calidad del conocimiento semántico de un modelo.
Diendo lo de Word2Vec y su análisis del
contexto cercano, pero me da la sensación de
que se está perdiendo información al mirar solo
una ventana de unas pocas palabras a la
vez.
Absolutamente. Y esa es precisamente la idea que
el equipo de la Universidad de Stanford exploró
con su modelo GLOBE, que son las siglas
de Global Vectors.
Vectores globales. Exacto.
Mientras Word2Vec aprende de forma indirecta,
prediciendo palabras en contextos locales,
GLOBE ataca el problema de frente.
Construye primero una matriz gigantesca de coocurrencias. Básicamente,
cuenta cuántas veces aparece cada palabra junto a
cualquier otra palabra en todo el corpus.
Por ejemplo, contará que hielo y frío aparecen
juntas muy a menudo, mientras que hielo y
fuego aparecen juntas con menos frecuencia,
aunque siguen teniendo una relación.
Su objetivo es que los vectores generados reproduzcan
las proporciones de esas probabilidades de coocurrencia.
Le da una base estadística muy sólida y
robusta. Muchísimo más, vale.
Un enfoque diferente para llegar a un resultado
similar.
Y las fuentes mencionan un tercer modelo, FastText,
de Facebook.
Este parece que introduce una idea interesante,
no mirar solo la palabra entera.
Sí, esa fue su gran aportación.
FastText descompone las palabras en sus partes,
en n-gramas de caracteres.
Por ejemplo, la palabra planeta la descompone en
pla, lan, ane, net, eta,
además de la palabra completa.
Y esto tiene dos ventajas enormes.
Así es.
Sirve para palabras que no ha visto nunca.
El topográfico no se queda en blanco.
Puede inferir su significado a partir de las
partes que sí conoce.
Claro, como si aprendiera las letras de las
palabras.
Justo. Por eso, si se encuentra con una
palabra inventada como caminanteando, aunque no la haya
visto nunca, puede intuir que tiene que ver
con caminar o caminante.
Y la segunda ventaja, que mencionan los artículos,
es especialmente útil para un idioma como el
español, con tantas conjugaciones y derivaciones.
Totalmente. Para un modelo como Word2Vec, correr,
corría y corredor son tres palabras totalmente distintas.
FastText, al compartir los n-gramas de caracteres,
entiende que están intrínsecamente relacionadas y sus vectores
estarán mucho más cerca.
Es una forma de entender la morfología.
Sin embargo, todos estos modelos, Word2Vec, Glove, FastText,
comparten una limitación fundamental.
Crean representaciones estáticas. Es decir,
la palabra banco tiene un único vector,
un único punto en el mapa,
sin importar si hablo del banco de un
parque, de un banco de peces o de
un banco para sacar dinero.
Y ese es el problema.
El significado de una palabra depende totalmente del
contexto.
Necesitábamos modelos que generaran vectores dinámicos, contextuales.
Exactamente. Ahí es donde entra en escena el
nombre que cambió todo. BERT,n-gramas
desarrollado por Google en 2018.
El artículo original de BERT es denso,
pero la idea central que lo diferencia de
todo lo anterior es que es profundamente bidireccional.
¿Y qué significa eso en la práctica?
Pues significa que lee como lo haría un
humano.
Los modelos anteriores, incluso los más avanzados de
la época, como GPT, eran unidireccionales.
Para entender una palabra, solo miraban el texto
que venía antes, de izquierda a derecha.
Claro, no podían esperar al final de la
frase para entender el principio.
Era un problema. Lo que hizo BERT,
y esto es lo que su artículo describe
como la clave de su éxito,
fue forzar al modelo a mirar en ambas
direcciones a la vez.
Para ello, inventaron una tarea de entrenamiento muy
ingeniosa llamada Masked Language Model.