Buenas, esto es BIMPRAXIS, el podcast donde el BIM se encuentra con la inteligencia artificial.
Download transcript (.srt)
0:09
0:20
0:28
0:37
0:45
0:46
0:55
0:57
1:03
1:08
1:10
1:11
1:14
1:21
1:28
1:34
1:40
1:42
1:44
1:52
1:53
1:56
2:05
2:09
2:11
2:12
2:21
2:24
2:30
2:31
2:40
2:42
2:49
2:50
3:00
3:06
3:07
3:10
3:12
3:18
3:20
3:31
3:35
3:42
3:44
3:55
3:57
4:06
4:12
4:16
4:17
4:24
4:31
4:34
4:35
4:42
4:47
4:51
4:55
5:00
5:02
5:09
5:12
5:17
5:22
5:23
5:30
5:31
5:36
5:39
5:42
5:43
5:49
5:50
5:52
6:00
6:01
6:08
6:12
6:14
6:14
6:23
6:25
6:26
6:33
6:41
6:41
6:42
6:50
6:59
7:00
7:10
7:12
7:23
7:27
7:39
7:40
7:47
7:56
7:57
8:03
8:07
8:10
8:12
8:13
8:26
8:28
8:40
8:41
8:46
8:53
8:54
9:09
9:10
9:14
9:15
9:24
9:28
9:34
9:40
9:45
9:46
9:54
10:03
10:03
10:09
10:09
10:12
10:19
10:19
10:31
10:36
10:38
10:39
10:47
10:49
10:56
11:00
11:06
11:09
11:14
11:15
11:24
11:25
11:32
11:37
11:39
11:45
11:48
11:53
12:00
12:09
12:11
12:22
12:24
12:27
12:39
12:40
12:47
12:50
12:56
13:04
13:09
13:12
13:13
13:28
13:35
13:35
13:39
13:49
13:50
13:51
13:58
14:07
14:08
14:09
14:10
14:24
14:35
14:36
14:36
14:36
14:36
14:36
14:36
14:36
14:37
14:37
14:37
14:37
14:37
14:37
14:37
14:37
14:37
14:37
14:37
14:37
14:37
14:39
14:40
14:41
14:41
14:41
14:41
14:41
14:41
14:41
14:41
14:41
14:41
14:41
14:41
14:41
14:41
14:41
14:41
14:48
14:52
15:11
15:17
15:27
Exploramos la ciencia, la tecnología y el futuro desde el enfoque de la arquitectura, ingeniería y construcción.
¡Empezamos!
Bueno, acaba de aparecer en escena una nueva empresa de inteligencia artificial que parece sacada de una novela de ciencia ficción.
Totalmente.
Se llama Thinking Machines Lab. La funda Mira Murati, la exdirectora de tecnología de OpenEI. Y atención a la cifra.
Uf, la cifra es de locos.
Han recaudado 2.000 millones de dólares. 2.000 millones en una ronda semilla.
Y eso les da una valoración de 12.000 millones. Antes de tener nada.
Antes de tener un producto público.
Es una auténtica locura.
Y fíjate, no estamos hablando de inversores de medio pelo.
La lista incluye a gigantes como NVIDIA, Andreessen Horowitz, ACIZ, Cisco, AMD.
Cuando ellos apuestan tan fuerte y tan pronto por algo, no es una simple inversión. Es una declaración de intenciones.
Es una señal. Una señal muy clara de que ahí se está cociendo algo que podría cambiar las reglas del juego.
Justo. Totalmente. Pero su comunicación inicial ha sido, bueno, increíblemente críptica.
Muy misteriosa. Sí.
Han lanzado una web que es...
Básicamente una pantalla en blanco y tweets hablando de IA multimodal y de la forma desordenada en que colaboramos.
Muy abstracto todo.
Así que hoy vamos a hacer precisamente eso, ¿no?
Vamos a desentrañar qué es Thinking Machines Lab y sobre todo analizar a fondo su primer producto que acaban de lanzar, llamado Tinker.
A ver si es un nuevo chatbot, un competidor de OpenAI o...
O algo radicalmente distinto.
Esa es la pregunta del Millén.
Vamos a sumergirnos en los documentos técnicos y en los detalles que han ido saliendo para entender qué hay detrás de esta inversión monumental y de tanto secretismo.
De acuerdo. Pues vamos a desgranarlo.
Lo primero que hay que entender sobre Thinking Machines Lab es que su objetivo no es crear otro modelo de lenguaje.
No. No van por ahí.
Su misión declarada es mucho más fundamental. Quieren atacar de raíz dos de los mayores desafíos de la IA. La consistencia y el razonamiento.
Y esto es absolutamente crucial.
Cuando hablamos de consistencia en IA, a ver, nos referimos a algo que parece muy básico, pero que no lo es.
¿A qué exactamente?
A la capacidad de un modelo para dar resultados fiables, predecibles, que no te dé una respuesta brillante un día y una completamente ilógica al día siguiente con una pregunta parecida.
Claro. Porque de nada sirve tener una IA que sea un genio el lunes y el martes se vuelve un completo idiota.
Exacto.
Nadie se subiría a un coche autónomo que funcionase así.
Justo. Piensa en un sistema de diagnóstico médico.
En análisis financieros, para tomar decisiones de miles de millones, o en la conducción autónoma.
Aplicaciones de alto riesgo.
Efectivamente. No puedes tener un sistema que a veces acierta y a veces improvisa o se vuelve impredecible. La fiabilidad lo es todo. Por eso su misión es tan ambiciosa.
Quieren que la IA no solo sea creativa, sino también confiable.
Y para lograrlo han reunido a un equipo que es, literalmente, el Dream Team que hizo posible ChatGPT.
Ahí quería llegar. No es solo Mira Murati.
Para nada. Han fichado a gente como John Shulman, cofundador de OpenAI, y una de las mentes clave detrás de las técnicas que hacen que ChatGPT parezca tan, bueno, tan humano.
Uf, palabras mayores.
Es que cuando juntas a ese nivel de talento, con esa misión tan clara, y con 2.000 millones de dólares, pues todo el sector de la IA se para a escuchar con mucha atención.
Bien. Entonces, con esa misión de crear una IA más fiable, lanzan superiores.
El primer producto, Tinker. Y al principio hubo mucha confusión, ¿no?
Muchísima.
La gente esperaba un competidor directo de ChatGPT o de Cloud. Pero resulta que no tiene nada que ver.
Nada que ver. Tinker no es un producto para el consumidor final. No es una app con la que te pones a hablar.
Y aquí está la clave para entender la revolución que proponen.
A ver.
No se trata de hacer un ChatGPT un poco mejor. Se trata de permitir que un hospital cree un radiólogo de IA
y a cualquier humano, o que un bufete de abogados entrena a un experto en patentes que no comete errores.
O sea, es el paso del sabelotodo generalista al genio especialista.
Exacto. Y eso es un cambio de paradigma total.
O sea, no nos dan el plato cocinado, sino que nos ofrecen la cocina para que cada uno se prepare su receta.
Mmm. Esa analogía es perfecta.
He leído que es como el paso de los ordenadores mainframe de los 70, que solo tenían las grandes instituciones,
a la llegada de los ordenadores personales que democratizaron.
Es una analogía buenísima. Pero con un matiz importante.
Tinker no es una herramienta mágica que crea un modelo de IA a partir de una idea.
Ah, ¿no es pulsar un botón y ya?
No. No le dices créame un experto en derecho mercantil y funciona. Requiere conocimientos técnicos.
Vale.
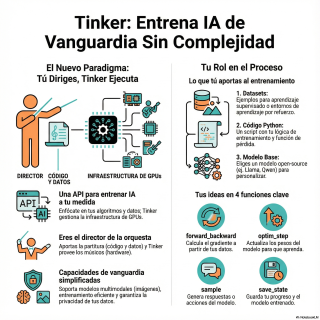
Siguiendo con la metáfora, Tinker te proporciona una cocina industrial de última generación.
Te da la infraestructura, los clústeres de GPUs, la potencia de cálculo…
Todo lo que es carísimo…
… y complicadísimo de gestionar.
Justo. Pero el usuario tiene que traer dos cosas fundamentales. Los ingredientes, que son sus datos…
Y la receta.
¿Y la receta? ¿Qué es su código?
Entiendo. El objetivo, entonces, es que un investigador o un desarrollador pueda centrarse solo en su algoritmo y en la calidad de sus datos.
Exacto.
Y se olvide de la pesadilla que es gestionar el hardware la fiabilidad de cientos de GPUs en paralelo. Toda esa orquestación.
Precisamente. Quieren que el talento se dedique a la ciencia.
No a ser administrador de sistemas.
Claro.
Hablé con una de las primeras investigadoras que lo usó y me contó que llevaba meses atascada intentando configurar un clúster para un experimento.
Con Tinker, lo tuvo funcionando en una tarde.
¡Qué bueno!
Su frase fue, sentí que me habían quitado una mochila llena de piedras de encima y por fin podía volver a hacer ciencia.
¡Qué pasada! Y lo fascinante es que, a pesar de toda esa complejidad que gestionan por debajo, la interacción parece increíblemente sencilla.
Sí.
¿El usuario?
El usuario escribe un script en Python como si lo ejecutaran su propio ordenador y toda la magia negra ocurre en la nube.
Así es. Como decíamos, el usuario aporta su receta. Y esta receta tiene tres elementos. Primero, eliges un modelo base.
Ah, no empiezas de cero.
No, sería prohibitivamente caro. Escoges un modelo de código abierto potente, como Lama de Meta o Cuen de Alihuabá, y lo usas como punto de partida.
¿Y lo personalizas?
Lo personalizas con una técnica muy eficiente llamada Lora, que en lugar de modificar todo el modelo, entrena una especie de adaptador muy pequeño. Es mucho más rápido y barato.
Vale. Tienes la base. Luego, los ingredientes, que son los datos…
El componente más importante. El usuario es responsable de sus datos. Y aquí es donde se crea la especialización. Y un detalle muy importante. Garantizan total privacidad.
¿En qué sentido?
Los datos de un cliente se usan exclusivamente para entrenar su modelo. Nunca para los de Thinking Machines ni para los de otros clientes.
Pero ese método de entrenar con datos, por ejemplo, con aprendizaje supervisado, dándole pares de pregunta-respuesta, suena increíblemente laborioso, ¿no?
Uf, sí.
¿No hay una forma más inteligente de que la IA aprenda, quizá por su cuenta, sin que tengamos que darle todo masticado?
Es una pregunta excelente y toca el corazón del asunto.
El aprendizaje supervisado es muy potente.
Pero, como dices, muy costoso.
Claro.
Por eso, Tinker también soporta plenamente el aprendizaje por refuerzo, el RL. Ahí no le das las respuestas, sino que creas un entorno, una simulación, donde un agente de IA aprende por prueba y error.
Recibiendo recompensas o castigos.
Exacto. Además, soporta modelos multimodales. Así que los ingredientes pueden ser texto, pero también imágenes, lo que abre la puerta a entrenar modelos que entiendan radiografías…
… planos…
Entendido. Tenemos el modelo base y los datos. Y el tercer componente.
El código. El script de Python que mencionabas. Es el director de orquesta. Y aquí está la genialidad de su diseño.
A ver…
Toda esa complejidad de coordinar cientos de GPUs se controla con un puñado de comandos. Es como decirle a la máquina, toma estos datos y aprende. Ahora actualiza el modelo. Générame un ejemplo para ver cómo vas. Y guarda el progreso.
O sea…
Simplifican algo que es increíblemente complejo en cuatro ideas básicas.
Justo.
Ah, ahora entiendo mucho mejor su comunicación inicial. Cuando hablaban de la forma desordenada en que colaboramos, no se referían a nosotros, los usuarios.
No, se referían a la propia comunidad de investigadores de IA.
Están intentando arreglar el caos y la complejidad que supone construir estos modelos desde cero.
Exactamente. Su cliente es el investigador, el desarrollador, el científico de datos.
Y la flexibilidad es total. Si quieres cambiar tu modelo base, de Lama a Cuban.
No tienes que rehacer todo.
No, es literalmente cambiar una línea de texto en tu código. Abstraen la complejidad del hardware para potenciar la innovación en el software.
Vale. Tenemos una herramienta que pone el poder de un gigante tecnológico en manos de equipos mucho más pequeños. Eso suena increíblemente potente.
Lo es.
Pero también me hace pensar inmediatamente en las consecuencias. Si cualquiera puede construir una IA súper especializada…
¿Qué es la IA?
¿Qué es lo primero que puede salir mal?
Esa es la otra cara de la moneda, el arma de doble filo. Por un lado, tienes el efecto de la democratización.
Claro.
Permite a investigadores universitarios, hospitales o startups pequeñas experimentar con capacidades que hasta ahora estaban reservadas casi en exclusiva para Google, Meta u OpenAI.
Y eso puede acelerar la investigación en curas para enfermedades, en nuevos materiales…
Lo que se te ocurra. Pero por otro lado…
Por otro…
Por otro, si de repente es mucho más fácil crear modelos de IA muy potentes y personalizados que impide que alguien lo use para fines maliciosos.
Uf, ese es el tema.
Imagina un modelo experto en generar desinformación política hiperrealista, en buscar vulnerabilidades de software a gran escala.
O en crear contenido dañino. Es un riesgo muy real.
Y ellos son conscientes de esto, supongo. ¿Cómo están gestionando ese riesgo? Porque parece una caja de Pandora.
Lo son. Por ahora, su solución es muy importante.
Están revisando personalmente cada solicitud de acceso a la plataforma.
Una a una.
Una a una, para asegurarse de que los proyectos tienen fines legítimos. Pero ellos mismos admiten que eso no es escalable a largo plazo.
Claro. Imposible.
Han dicho que planean implementar sistemas automatizados en el futuro para detectar y prevenir el mal uso.
Sinceramente, es un debate muy complejo y todavía abierto en toda la comunidad.
Suena bien en teoría, pero…
¿Es realista pensar que pueden controlarlo? Si la herramienta es tan buena, ¿no es inevitable que acaben las manos equivocadas?
Es el gran dilema de nuestro tiempo.
La historia de la tecnología está llena de herramientas bien intencionadas usadas para fines terribles.
Sí, no hay una respuesta fácil. Su enfoque actual es un primer paso, un intento de filtrar los casos más obvios.
Pero a medida que la tecnología se extienda, la responsabilidad recaerá en una combinación de salvaguardas técnicas, regulación…
No, imposible.
Y hay otro punto que me genera dudas. ¿No crea esto una nueva dependencia? Antes dependías de OpenAI para usar su modelo, y ahora dependes de Thinking Machines para construir el tuyo.
Es una objeción muy inteligente.
¿Es realmente una democratización o solo un cambio de proveedor?
Y la han abordado de una forma que creo que es clave. A diferencia de las APIs cerradas, donde solo puedes hablar con el modelo, aquí el modelo final que tú creas con tus datos es tuyo.
Ah, ¿te lo puedes descargar?
Te lo puedes descargar. Puedes ejecutarlo en tus propios servidores, en la nube que tú elijas, donde quieras. No estás atado a su plataforma.
O sea, te dan la fábrica para construir el coche.
Exacto. Pero una vez construido, el coche es tuyo y te lo llevas. Esa es una diferencia fundamental.
Eso sí que cambia las cosas. Y para que la gente pueda empezar, han publicado recursos. He visto que mencionan un Tinker Cookbook.
Sí, es un repositorio en GitHub.
Es un repositorio de recetas, con ejemplos prácticos de código, para empezar.
Vale.
Cubre desde el aprendizaje supervisado más básico hasta configuraciones muy avanzadas de aprendizaje por refuerzo, como RLHF o DPO, que son, bueno, formas de enseñar a la IA a ser más útil y segura usando feedback humano.
Muy bien. A modo de recapitulación. ¿Queda claro que Thinking Machines Lab no es un competidor directo de ChatGPT?
Correcto.
No están construyendo un producto para el gran público.
Es un proveedor de herramientas de alto nivel. Si la IA es la nueva fiebre del oro, ellos no venden el oro, venden los picos, las palas y la maquinaria pesada para que otros lo encuentren.
Y Tinker es su primera gran máquina.
Exacto.
Y el modelo final que creas es tuyo, lo que resuelve el problema de la dependencia. Puedes llevártelo y usarlo como quieras.
Exacto. Y yo diría que el verdadero poder de Tinker, su promesa a largo plazo, reside precisamente en esa capacidad de crear expertos de nicho.
¿Modelos únicos?
¿Modelos únicos?
Ultraespecializados.
Eso es. Modelos que puedan superar con creces a los generalistas en tareas específicas. El futuro podría no ser una única IA que lo hace todo bien, sin un ecosistema de miles de IAs especializadas colaborando entre sí.
Y eso nos deja con una reflexión final, ¿no? La historia de la tecnología nos enseña que cuando las herramientas de creación se vuelven más accesibles, la innovación explota en direcciones que nadie esperaba.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
Totalmente.
La pregunta es inevitable, ¿qué tipo de asistentes hiperinteligentes para tareas que hoy ni imaginamos podrían surgir?
Y lo más importante, ¿quiénes serán los que los construyan?
Ya no solo los gigantes tecnológicos, sino quizás cualquiera con una buena idea, buenos datos y una buena receta.
Y hasta aquí el episodio de hoy. Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.