Buenas, esto es BIMPRAXIS, el podcast donde el BIM se encuentra con la inteligencia artificial.
Download transcript (.srt)
0:09
0:20
0:28
0:37
0:42
0:45
0:51
0:55
1:00
1:05
1:12
1:15
1:16
1:20
1:28
1:35
1:42
1:45
1:47
1:52
1:57
2:01
2:05
2:10
2:15
2:17
2:19
2:27
2:31
2:42
2:45
2:53
2:59
3:07
3:14
3:19
3:22
3:31
3:32
3:38
3:47
3:56
4:06
4:07
4:08
4:14
4:21
4:22
4:32
4:38
4:44
4:46
4:48
4:55
4:56
5:02
5:08
5:13
5:15
5:20
5:28
5:36
5:38
5:43
5:44
5:48
5:54
5:54
6:03
6:08
6:20
6:26
6:34
6:34
6:38
6:44
6:50
6:55
7:03
7:04
7:08
7:12
7:16
7:21
7:27
7:36
7:37
7:38
7:43
7:52
7:53
8:02
8:04
8:08
8:10
8:14
8:19
8:23
8:31
8:35
8:36
8:36
8:39
8:44
8:48
8:49
8:53
9:02
9:03
9:11
9:12
9:19
9:25
9:33
9:33
9:33
9:33
9:36
9:44
9:46
9:57
9:59
10:03
10:09
10:13
10:18
10:21
10:25
10:28
10:33
10:37
10:38
10:47
10:56
10:57
11:01
11:11
11:18
11:22
11:22
11:29
11:34
11:35
11:41
11:49
11:55
11:56
11:57
11:59
12:06
12:14
12:15
12:22
12:25
12:30
12:33
12:34
12:36
12:43
12:50
12:52
12:53
12:56
12:59
13:02
13:02
13:06
13:10
13:18
13:22
13:25
13:28
13:29
13:29
13:29
13:29
13:32
13:37
13:39
13:40
13:43
13:49
13:50
13:54
13:58
14:03
14:04
14:07
14:09
14:13
14:21
14:21
14:26
14:28
14:30
14:32
14:33
14:39
14:44
14:46
14:47
14:53
14:56
14:58
15:01
15:06
15:13
15:15
15:17
15:22
15:26
15:28
15:30
15:33
15:36
15:39
15:43
15:48
15:51
15:52
15:53
15:57
15:58
15:59
16:01
16:02
16:08
16:12
16:17
16:19
16:20
16:26
16:28
16:41
16:45
16:54
Exploramos la ciencia, la tecnología y el futuro desde el enfoque de la arquitectura, ingeniería y construcción.
¡Empezamos!
Bienvenidos a una entrega que es, bueno, yo diría que muy especial para nosotros.
Sí, la verdad es que sí, es un día importante.
Hoy cerramos nuestra serie, los papers que cambiaron la historia de la IA, que sabemos que os ha gustado mucho.
Y la cerramos por todo lo alto, con algo un poco diferente.
Totalmente, porque hoy no vamos a analizar un único paper histórico, como veníamos haciendo.
No, hoy hacemos algo distinto. Es que nos ha picado el gusanillo de la investigación.
Así que, bueno, durante los últimos meses, el equipo de BIMPRAXIS se ha sumergido a fondo en la vanguardia más absoluta de la IA.
Y cuando dice a fondo, no es una forma de hablar.
Para nada.
Hemos analizado cerca de 40 artículos científicos de primerísimo nivel.
Todos publicados desde el verano de 2025 hasta hoy mismo, 7 de enero de 2026. Vamos, lo más reciente de lo reciente.
El objetivo era, era detectar la corriente de fondo, ¿no? Hacia dónde va todo esto.
Exacto. Y la hemos encontrado. No es una idea aislada en un paper. Es una convergencia clarísima en casi todos los trabajos.
¿Y el concepto que lo define todo?
Todo es la IA autoevolutiva.
Justo eso. Una IA que se programa, se corrige y se mejora a sí misma.
Suena a ciencia ficción, la verdad, pero vamos a ver que no lo es para nada.
Y para que se entienda bien, nos vamos a centrar en el mejor ejemplo que hemos encontrado.
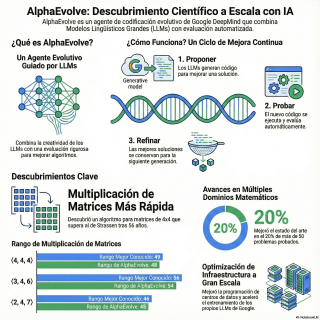
Un agente de codificación de Google DeepMind llamado AlphaEvolve.
Vale, vamos a desgranar esto. ¿Qué es exactamente este agente evolutivo?
A primera vista, una podría pensar que es simplemente otro modelo de lenguaje.
Grande. Otro LLM más.
Pero no, es mucho más.
Eso parece. AlphaEvolve no es un LLM, sino un sistema completo que orquesta a varios LLMs para que trabajen juntos.
Ah, o sea que es como un director de orquesta.
Es una buena analogía, sí. Es una cadena de montaje autónoma y su única misión es coger un programa y mejorarlo, haciendo cambios directamente en su código.
La palabra clave entonces es evolutivo.
Evolutivo. Suena muy potente. Pero, siendo un poco cínica, ¿no es solo un bucle de prueba y error a toda velocidad?
Es una pregunta buenísima. O hay algo más que lo haga realmente evolutivo en un sentido más profundo.
Ahí está el cambio de juego. Sí, es un proceso iterativo, de proponer y probar. Pero la clave es cómo aprende de ese feedback.
Claro. Propone un cambio, unos evaluadores automáticos le dan una nota, le dicen si ha sido una mejora o no,
y el sistema usa esa información para que la siguiente propuesta sea más inteligente.
O sea, no es un ensayo y error ciego, para nada. Es dirigido.
Precisamente. Es una evolución sobre sistemas anteriores, como FoundSearch, que ya eran una pasada, pero estaban más limitados.
¿Y cuál es la gran diferencia?
La escala y la complejidad. FoundSearch era un genio descubriendo pequeñas funciones, fragmentos de código.
Alfa Evolve puede coger una base de código entera con docenas de funciones que interactúan entre sí, y reescribirla de arriba a abajo para hacerla mejor.
Vale. El concepto general lo tengo. Pero suena casi a magia. ¿Cómo es ese proceso por dentro? ¿Cómo empieza una de esas vueltas de mejora?
Pues el punto de partida es humano. Un programador le da tres cosas. El programa que quiere mejorar, el código que servirá para evaluar si las mejoras funcionan…
¿El juez, por así decirlo?
Exacto.
El juez, y algunas configuraciones. A partir de ahí, se pone en marcha el bucle de descubrimiento.
Y el primer paso es que el sistema se inspire en sí mismo, ¿no? El muestreador de prompts.
Correcto.
En lugar de empezar de cero, mira las versiones del código que ya han funcionado bien, y construye una petición, un prompt, muy detallado para los LLMs.
Eso es. Y ese es un paso crucial. Con esos prompts tan ricos en contexto, los LLMs…
…entran en juego. Y ojo, no generan el programa entero de nuevo, que sería muy ineficiente.
Ah, no. ¿Qué generan, entonces?
Generan un diff.
¿Un diff? Para quien no venga del mundo del desarrollo, eso es como las sugerencias de edición de un documento de Word, ¿verdad?
Es la analogía perfecta.
No reescribe el texto, solo te dice, borra esta frase, añade esta otra aquí.
Justo eso. Es una instrucción precisa de qué líneas cambiar. Ese diff se aplica, se crea un código, y se pone en marcha el bucle de descubrimiento.
Se crea un nuevo programa candidato, y el juez automático lo evalúa y le da una puntuación.
¿Y si la puntuación es buena?
Se guarda. En una especie de salón de la fama de los mejores programas encontrados hasta ahora.
Y ese salón de la fama es lo que alimenta al muestrador de prompts para la siguiente vuelta. Es un ciclo de retroalimentación perfecto.
Exacto. Se va siendo más inteligente en cada iteración. En cada vuelta, parte de una base mejor y pide las cosas de una forma más informada.
Entiendo el bucle, pero me da la sensación…
Me da la sensación de que falta algo. ¿Qué evita que se quede dando vueltas sobre la misma idea una y otra vez?
Buena pregunta.
¿Hay algún truco, algún ingrediente secreto que lo haga tan potente?
Los hay. Y son la clave de su éxito. El primero es una genialidad llamada metaprompts.
¿Metaprompts?
Sí. Aquí la cosa se vuelve recursiva. El propio sistema no solo evoluciona el código, sino que también evoluciona los prompts con los que pide las mejoras.
Espera, espera. ¿Cómo? ¿La IA aprende a pedirse las cosas a sí misma de mejor manera?
Justo eso. Es como si un escritor no solo mejorara su novela, sino que también aprendiera a darse a sí mismo las instrucciones perfectas para inspirarse. Es una optimización a dos niveles.
Eso es fascinante. Y he visto que otro de los trucos es que no usan un único tipo de LLM.
Es una decisión muy inteligente, sí. Combinan modelos grandes y potentes, que son caros, con modelos más pequeños y baratos.
¿Y eso por qué?
Los grandes aportan la calidad, la coherencia.
Los pequeños inyectan variedad, una especie de creatividad ingenua o ruido inteligente.
A veces, una sugerencia un poco rara de un modelo pequeño es lo que saca al sistema de un atasco.
¿Un atasco? ¿Te refieres a eso que en los papers llaman máximo local?
Exacto. Un máximo local es cuando el sistema encuentra una solución que es bastante buena, y cualquier pequeño cambio que intenta la empeora.
Y se queda ahí, claro.
Se queda ahí, pensando que ha llegado a la cima, cuando en realidad hay una montaña.
Una montaña mucho más alta. Una solución mucho mejor, más lejos.
Y los modelos pequeños le dan el empujón para salir de ahí.
Eso es. Con sus ideas extrañas, a veces le ayudan a salir de ese valle y seguir buscando.
Entendido. ¿Y el tercer ingrediente es el feedback? Que no es solo un número, una puntuación.
Efectivamente. Además de la nota objetiva del juez, se pueden usar otros LLMs para que den feedback sobre cosas más abstractas, más humanas.
¿Como por ejemplo?
Por ejemplo.
Lorenzi, el código nuevo es más simple, más elegante o más fácil de entender que el anterior.
Ah, qué bueno. O sea que guía la evolución no solo hacia soluciones que funcionan, sino hacia soluciones que son buenas, en un sentido más amplio.
Precisamente.
Vale. Y toda esta arquitectura tan sofisticada no es teoría. Ha conseguido resultados que son, literalmente, históricos.
Sí, aquí es donde la cosa se pone seria.
Hablemos del primer granito, el de la multiplicación de matrices.
¿Cómo es para enmarcarlo?
Es un problema central en computación. Vamos, de los que se estudian en primero de carrera.
Y desde 1969, el algoritmo de Strassen era el rey.
Un momento. ¿Has dicho 1969?
1969. Durante 56 años, nadie había conseguido mejorarlo para un caso muy concreto.
La multiplicación de matrices complejas de 4x4. Era un techo.
56 años.
56 años.
Y entiendo que Alfa y Wolf se puso a ello.
Se puso a ello y descubrió un procedimiento completamente nuevo.
El método de Strassen necesitaba 49 multiplicaciones para resolverlo.
¿Y Alfa y Wolf?
Alfa y Wolf encontró la manera de hacerlo con 48.
Una. Parece un paso pequeño, pero romper un récord que ha durado más de medio siglo es una barbaridad. Es un hito monumental.
Y no es un caso aislado.
De los 54 tipos de multiplicaciones que analizaron, igualó las mejores soluciones conocidas en 38 casos.
¿Y en el resto?
Y encontró un método superior en 14 de ellos. Es una demostración de fuerza bruta y descubrimiento.
Y no se queda ahí. También lo han enfrentado a problemas matemáticos puros, de esos que llevan décadas abiertos.
Sí, y los resultados son igual de alucinantes. Lo probaron con más de 50 problemas de campos como el análisis, la combinatoria, la geometría.
¿Y en la matemática?
Sí.
¿Y en la matemática?
En la mayoría de casos redescubrió lo que ya sabíamos, ¿no?
En el 75% de los casos, sí. Redescubrió por sí solo las mejores soluciones que ya conocíamos. Lo cual ya es impresionante.
Pero, ¿y el otro 25%?
Ahí es donde está la magia. En el 20% de los problemas, uno de cada cinco, Alfa y Wolf descubrió un objeto matemático nuevo y mejor que cualquiera conocido hasta la fecha.
O sea, mejoró el estado del arte.
Exacto. Por ejemplo, consiguió refinar ligeramente el límite superior de la matemática.
El límite superior del problema del solapamiento mínimo de ER2. Un problema con muchísima historia.
Son pequeñas victorias que demuestran una capacidad de descubrimiento genuina.
Esto nos lleva a las aplicaciones prácticas, que es donde se ve el impacto real.
¿Cómo se está usando esto ya dentro de un gigante como Google?
Aquí es donde la cosa se traduce en millones de dólares.
Google gestiona sus centros de datos con un sistema llamado BORG.
Es un problema de planificación colosal, lo que se conoce como beanpacking.
Beanpacking. Como jugar al Tetris a una escala demencial, ¿no?
Es la mejor forma de explicarlo, sí.
Tienes que meter piezas de trabajo, que necesitan CPU y memoria, en las cajas que son los servidores, intentando no dejar huecos.
Y la eficiencia aquí es crítica. Pues usaron Alfa y Wolf para optimizar la fórmula, la heurística que decide dónde va cada pieza del Tetris.
¿Y qué encontró?
Descubrió una función sorprendentemente simple, de apenas siete líneas de código.
Pero implementar esa pequeña fórmula ha supuesto una recuperación continua del 0,7% de los recursos computacionales de toda la flota de servidores de Google.
Espera, para un momento. El 0,7% suena a poco, pero en la escala de Google. ¿De qué estamos hablando?
Estamos hablando de una cifra de ahorro y eficiencia absolutamente descomunal.
Me lo imagino.
Y hay un detalle importantísimo. En los informes cuentan que había una alternativa basada en Deep Reinforcement Learning,
que también funcionaba bien, pero prefirieron la de Alfa y Wolf.
¿Por qué?
Porque la solución de Deep Learning era una caja negra. Funcionaba, pero nadie sabía muy bien por qué.
La de Alfa y Wolf era una fórmula en código, interpretable, fácil de depurar y segura de implementar en un sistema tan crítico como Borg.
Claro. A veces la mejor solución no es la más compleja, sino la más elegante y comprensible.
Totalmente.
Es un punto clave.
Pero la cosa se vuelve todavía más loca.
La recursividad de todo esto es vertiginosa. También se usó para acelerar la propia IA, ¿no es así?
Es el ejemplo perfecto del ciclo de automejora. Alfa y Wolf optimizó esos algoritmos de multiplicación de matrices que comentábamos antes.
Ajá.
A entrenar a Gemini, el LLM, que a su vez es uno de los motores del propio Alfa y Wolf.
O sea que la IA se está acelerando a sí misma.
Se está acelerando a sí misma. No solo mejora el software de los centros de datos.
Mejora el software que la entrena a ella misma.
Es increíble.
Y no solo el software, también el hardware.
Encontró simplificaciones en el diseño de los circuitos de los aceleradores de hardware de Google, los TPUs.
O sea que está optimizando el software de gestión, el software de entrenamiento y el chip sobre el que todo eso corre.
Cierra el círculo por completo.
Cierra el círculo.
Entonces, ¿qué significa todo esto?
Está claro que no se trata solo de que una IA resuelva problemas.
Es la versatilidad con la que lo hace.
Exacto.
Puede buscar una solución directa, como la fórmula para Borg.
O puede encontrar un programa que construya esa solución.
O, y esto ya es el siguiente nivel, puede evolucionar un algoritmo de búsqueda para que sea ese algoritmo el que encuentre la solución.
Es una capacidad de abstracción a múltiples niveles.
Y esto nos lleva directamente a la siguiente pregunta.
¿Cuál es nuestro papel, el de los humanos, en todo esto?
Claro.
¿Por qué no?
¿Por qué no?
¿Por qué no?
Porque la idea no es reemplazar, sino colaborar.
Los descubrimientos de Alpha Evolve no son un punto final, son el punto de partida.
¿Colaboración con humanos o con otras IAs?
Con ambos.
Ya se está viendo un ecosistema de IAs especialistas.
Por ejemplo, un nuevo objeto matemático que descubre Alpha Evolve se le puede pasar a otra IA llamada DeepThink.
¿Para que lo analice?
Para que intente encontrar una fórmula general que explique el patrón.
Y esa fórmula, a su vez, se le puede enviar a una tercera IA, Alpha Proof,
para que genere una prueba matemática formal y rigurosa.
Alucinante.
Un equipo de investigación formado por IAs.
Y supervisado por humanos.
Hay una anécdota fantástica sobre el problema de empaquetar hexágonos.
Alpha Evolve encontró la mejor forma conocida de meter 11 y 12 hexágonos pequeños dentro de uno grande, batiendo el récord.
Vale.
Pero la solución que encontró, aunque era la más eficiente, no era perfectamente simétrica.
Algo que a un matemático le chirriaría.
Y lo haría inmediatamente.
La belleza y la simetría son importantes.
Exacto.
Un matemático, Johann Schellhorn, vio la solución y se dio cuenta de que con un pequeño ajuste manual,
un toque de intuición humana, podía hacerla perfectamente simétrica, sin perder nada de eficiencia.
Es la prueba de que la combinación es la clave.
Esa es la clave.
La combinación de la fuerza de búsqueda casi infinita de la IA con la intuición humana para la estética y la simplicidad
es donde está el verdadero potencial.
Lo que nos deja con una reflexión final...
Es una reflexión total que es casi obligatoria.
Hemos visto una IA que optimiza el software que la entrena y el hardware sobre el que corre.
Si una IA puede mejorar de forma autónoma y recurrente sus propios algoritmos y la infraestructura que la soporta,
¿qué implicaciones tiene esto a largo plazo?
Esa es la gran pregunta.
Estamos en la primera etapa de un ciclo de automejora que podría volverse exponencial.
No tenemos la respuesta, pero la tendencia que hemos identificado en estos 40 artículos,
apunta a que esta pregunta ya no es ciencia.
Es un problema de ingeniería.
Es un problema de ingeniería a corto y medio plazo.
La IA autoevolutiva no es una promesa.
Es una tendencia tangible que ya está aquí.
Y está produciendo resultados que superan décadas de investigación humana.
Ha sido un viaje increíble a través de los papers que cambiaron la historia de la IA.
Y sólo podemos daros las gracias por habernos acompañado.
Desde luego.
Pero que nadie se confunda.
Que acabe la serie no significa que se acaben nuestras exploraciones en BIMPRAXIS.
Ni mucho menos.
Para nada.
El campo de la IA avanza a una velocidad de locos.
Y seguiremos aquí.
Con el microscopio puesto sobre las publicaciones más relevantes para destilarlas y entenderlas juntos.
De hecho, para la próxima entrega ya tenemos preparado un contenido fascinante
sobre una herramienta que está cambiando las reglas del juego en cómo accedemos al conocimiento.
Una herramienta que está en boca de todos en el sector.
Y con razón.
Una herramienta que, os lo aseguro, os va a dejar perplejos.
Se capta la indirecta.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.