Buenas, esto es BIMPRAXIS, el podcast donde el BIM se encuentra con la inteligencia artificial.
Download transcript (.srt)
0:09
0:20
0:28
0:37
0:45
0:46
0:52
1:02
1:03
1:10
1:15
1:16
1:19
1:20
1:22
1:27
1:31
1:33
1:37
1:45
1:46
1:52
1:59
1:59
2:05
2:10
2:15
2:15
2:18
2:26
2:26
2:35
2:45
2:46
2:53
2:57
3:01
3:08
3:13
3:14
3:15
3:24
3:33
3:35
3:39
3:43
3:54
4:03
4:13
4:16
4:18
4:19
4:24
4:32
4:36
4:43
4:47
4:56
5:03
5:11
5:12
5:12
5:19
5:23
5:23
5:24
5:31
5:35
5:36
5:38
5:42
5:55
5:56
6:06
6:06
6:12
6:14
6:18
6:22
6:23
6:28
6:30
6:33
6:35
6:42
6:46
6:48
6:52
6:53
6:58
7:00
7:06
7:10
7:12
7:16
7:19
7:20
7:23
7:24
7:28
7:32
7:35
7:38
7:40
7:42
7:44
7:45
7:49
7:54
7:57
7:58
8:03
8:08
8:10
8:12
8:15
8:17
8:20
8:24
8:27
8:29
8:33
8:36
8:38
8:42
8:47
8:51
8:54
8:56
8:58
9:03
9:05
9:06
9:08
9:12
9:14
9:15
9:18
9:21
9:23
9:24
9:28
9:31
9:34
9:37
9:40
9:42
9:44
9:47
9:49
9:54
9:58
9:59
10:03
10:06
10:08
10:12
10:16
10:19
10:21
10:24
10:26
10:29
10:29
10:32
10:37
10:39
10:42
10:44
10:47
10:50
10:52
10:54
10:55
10:57
10:58
11:00
11:01
11:03
11:04
11:06
11:08
11:12
11:15
11:18
11:19
11:23
11:28
11:29
11:32
11:34
11:36
11:38
11:40
11:42
11:47
11:49
11:55
11:57
12:00
12:05
12:08
12:09
12:12
12:19
12:21
12:25
12:29
12:33
12:39
12:42
12:43
12:47
12:51
12:55
12:56
13:02
13:06
13:09
13:11
13:14
13:16
13:20
13:21
13:26
13:30
13:32
13:59
Exploramos la ciencia, la tecnología y el futuro desde el enfoque de la arquitectura, ingeniería y construcción.
¡Empezamos!
Hola y bienvenidos. Volvemos a la carga con nuestra serie especial de BIMPRAXIS, los papers que cambiaron la historia de la IA.
Pues sí.
Ya vamos por el duodécimo análisis y la verdad cada vez se pone más interesante.
Totalmente. Y el que traemos hoy es de los que te dejan pensando días. Es muy reciente, de febrero de 2024, pero el revuelo que ha montado es tremendo.
A ver, cuenta.
Se titula The Era of One-Bit LLMs. All Large Language Models are in 1.58 Bits.
Uf, el título ya es una bofetada a todo lo establecido.
La era de los LLMs.
El LLM es de un bit. Suena casi a herejía.
Es que es muy provocador.
Vale, vamos a meternos en este jardín.
La misión de hoy es entender qué demonios es un modelo de lenguaje de un bit.
¿Por qué narices dicen que rinde igual que los gigantes actuales?
Y sobre todo, ¿qué puertas abre esto para el futuro?
Exacto. Si esto es una afantasmada o si de verdad es la próxima revolución.
Pues esa es la clave. Vamos a desgranar las afirmaciones del equipo de Shuming Ma, que son de una audacia increíble,
y a explicarles cómo es posible que el mundo no sea así.
Y a explorar si de verdad estamos a las puertas de una nueva era para la IA, una mucho más eficiente y accesible.
Perfecto. Pues antes de hablar de la cura milagrosa, hablemos un poco de la enfermedad, el problema de base.
El coste.
Claro. Los grandes modelos de lenguaje que usamos todos los días son una pasada.
Pero tienen un secreto a voces. Son carísimos. De entrenar, de mantener, de todo.
El paper habla de los modelos de precisión completa, o FP16.
¿Qué es el paper?
Para quien no esté en el ajo. ¿Qué es esto en cristiano?
A ver, imagina que el cerebro del modelo está hecho de millones de pequeñas neuronas, que en la jerga se llaman parámetros o pesos.
Vale.
Son los que almacenan el conocimiento. En un modelo estándar, uno de FP16, cada una de esas neuronas se representa con un número de 16 bits.
Pues significa que cada parámetro puede tener unos 65.000 valores distintos. Es un nivel de detalle de matiz altísimo.
Muchísimo.
Piensa en un potenciómetro de volumen que, en lugar de ir de 0 a 10, tiene 65.000 posiciones intermedias.
Esa precisión permite capturar relaciones muy sutiles en los datos, pero tiene un coste.
Un coste energético y computacional salvaje, me imagino.
Exacto. Es como pedirle a un ordenador que para cada mínima decisión haga cálculos con números con muchísimos decimales.
Requiere una memoria inmensa, una capacidad de proceso brutal y, claro, el consumo de energía se dispara.
O sea que…
¿La potencia de estos…?
Estos modelos vienen de su complejidad y su tamaño. Para ser inteligentes necesitan ser gigantescos y consumir una cantidad de energía absurda.
Esa ha sido la premisa hasta ahora. Más parámetros, más datos, más bits de precisión, igual a más inteligencia. Es una carrera armamentística de fuerza bruta.
El peaje que pagamos, ¿no?
Justo. El peaje por tener una IA potente es que sea ineficiente por diseño.
Pero claro, aquí llega este paper y le pega una patada a la mesa.
La pregunta que lanzan es demoledora en su simplicidad. ¿Y si toda esa precisión, todo ese despilfarro, no es necesario?
Justo. Cuestionan el dogma. Se preguntan si estamos construyendo rascacielos con vigas de oro macizo cuando a lo mejor, con acero, nos valía. Y de sobra.
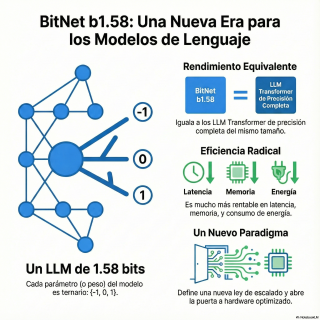
Vale, y aquí es donde la cosa se pone de ciencia ficción. La propuesta que hacen se llama BitNet B1.5. Y rompe la baraja por completo.
En lugar de sus 65.000 valores posibles por parámetro…
Lo reducen a 3.
¿Cómo que a 3?
A 3. No es una errata. Cada parámetro solo puede ser menos 1, 0 o 1. Sácaro.
Un momento, un momento. O sea, o está encendido en negativo, apagado o encendido en positivo.
Eso es. Es lo que se conoce como un sistema ternario.
Pero es que esto es tan simple que parece absurdo. Pasamos de un dial con 65.000 posiciones a un interruptor de 3.
Y afirman que el resultado es el mismo. A mí esto me suela que hay truco.
Es que es tan contraintuitivo que choca. Pero la clave está en el título. En ese 1.58 bits. No es un número puesto al azar, ¿eh?
Explícame de dónde sale ese número tan específico porque no es un bit ni es dos bits. ¿Qué es 1.58?
A ver, es una forma muy precisa de medir la cantidad de información. La unidad básica, el bit, tiene dos estados. 0 y 1.
Sí, hasta ahí llego.
¿Qué es eso?
Para saber cuántos bits necesitas para representar un número de estados, usas el logaritmo en base 2 de ese número de estados.
Para dos estados, logaritmo en base 2 de 2 es 1.
¿Un bit?
Lógico.
Pues para representar tres estados, como aquí con menos 1, 0, 1, necesitas el logaritmo en base 2 de 3.
Y eso da aproximadamente 1.5849.
Ah, vale.
Lo redondean a 1.58.
Es su manera de decir, ojo, hemos reducido la información necesaria.
Es una reducción brutal, pero la afirmación que te vuela la cabeza, la que está en el abstract y que todo el mundo está debatiendo…
La de que iguala el rendimiento, ¿no?
Esa. Que este modelo esquelético iguala el rendimiento del transformer de precisión completa del mismo tamaño. Es que me parece increíble.
Sí, sí, lo es.
Es como si me dices que has construido un coche con el motor de un avespino y corre lo mismo con Fórmula 1.
¿Cómo es posible?
Esa es la pregunta del millón. Y el núcleo de la disrupción.
El paper sugiere que, bueno, que nos hemos estado equivocando de foco.
¿En qué sentido?
O menos 1, 0 o 1, el modelo aprende a ser extremadamente eficiente.
No se anda con tonterías.
O una conexión es importante y la pone a 1 o menos 1.
O no lo es y la pone a 0. La anula.
Es como si en una orquesta lo importante no fuera que cada músico pueda tocar miles de matices sutiles,
sino que todos toquen la nota correcta en el momento justo.
Es una analogía fantástica.
La magia está en la coordinación, no en la complejidad individual.
Exactamente.
Parece que este enfoque obliga a la red a aprender las rutas de información más importantes y a descartar el ruido.
Se centra en lo esencial.
Y lo más loco es que, según ellos, lo esencial es sufriente para igualar a sus hermanos mayores, los de 16 bits.
Vale, vamos a asumir por un momento que no es un farol, que es cierto.
Si el rendimiento es el mismo,
pero el coste computacional, la memoria y la energía se desploman,
las consecuencias tienen que ser gigantescas.
Gigantescas.
No hablamos de una mejora, hablamos de un cambio de paradigma.
Totalmente.
El paper no se corta y habla de tres consecuencias transformadoras
que van mucho más allá de ahorrar en la factura de la luz.
Esto no es una optimización, es una reinvención.
Pues vamos a por ellas. ¿Cuál es la primera?
La primera es que define una nueva ley de escalado.
Esto suena muy técnico.
Sí, es técnico, pero es cambiar las reglas del juego.
A ver.
Hasta ahora, la ley no escrita, la de OpenAI, Google y compañía,
era que para tener modelos más potentes necesitabas escalar exponencialmente tres cosas.
Número de parámetros, cantidad de datos y cómputo.
Más grande siempre era mejor.
Diciendo que la carrera por hacer modelos cada vez más gigantescos,
los GPT-5, 6 y 7, podría ser un callejón sin salida energético y económico.
Eso es lo que sugieren.
Que la nueva ley podría ser...
¿Más eficiente es mejor en lugar de más grande es mejor?
Exactamente eso.
Proponen una nueva receta para construir los modelos del futuro.
Una donde la eficiencia no es algo que intentas apañar al final,
sino que está integrada en el diseño desde el principio.
Podría significar que el camino a la inteligencia artificial general
no es la fuerza bruta, sino la inteligencia en el diseño.
Me dejas sin palabras. Es un hordago a la grande.
Vale. ¿Cuál es la segunda consecuencia?
La segunda es que habilita un nuevo paradigma de computación.
A ver, las GPUs, los chips de NVIDIA, que son los reyes absolutos de la IA,
son extraordinariamente buenas haciendo una cosa.
Multiplicaciones masivas de números complejos y de alta precisión.
Los de 16 bits.
Toda la arquitectura está pensada para eso.
Pero claro, un modelo que solo tiene los valores menos uno, cero y una,
no necesita multiplicar casi nada.
Ahí está.
Multiplicar por uno es dejar el número como está,
por menos uno es cambiarle el signo y por cero es anularlo.
La operación principal pasa a ser la suma.
Justo.
Y usar una GPU de 5.000 euros para sumar y restar
es como usar un martillo pilón para cascar una nuez.
Es un derroche absoluto de potencial.
Entiendo.
Este paper abre la puerta a un tipo de computación mucho más simple,
que sería muchísimo más rápida y eficiente energéticamente.
Y eso nos lleva de cabeza a la tercera consecuencia,
que si no me equivoco es la que más nos va a afectar a todos.
La posibilidad de crear hardware específico.
Y aquí es donde la cosa se va.
Ahora se pone realmente tangible.
Si ya no necesitas la arquitectura de una GPU,
podrías diseñar un chip nuevo,
llamémosle un Bit Processing Unit o BPU,
optimizado solo para trabajar con estos modelos de 1.58 bits.
¿Y serían chips?
Mucho más sencillos, más pequeños, más baratos de producir
y, sobre todo, consumirían una fracción de la energía.
Pero seamos realistas.
Eso es un ciclo de desarrollo de años y una inversión de miles de millones.
¿De verdad una empresa como NVIDIA, que tiene un monopodio de facto,
va a tirar por la borda décadas de I plus D por un paper?
Esa es la gran pregunta comercial, claro.
A corto plazo, seguramente no.
Pero si esta tecnología demuestra ser viable,
la presión del mercado podría ser irresistible.
Claro.
Imagina que un nuevo competidor diseña un chip de estos
y ofrece el mismo rendimiento por una décima parte del precio y del consumo.
O piensa en Apple, Google o Samsung,
diseñando sus propios chips para sus móviles.
Ahí es donde quería llegar.
La idea de tener una IA con la potencia de GPT-4,
pero funcionando de forma nativa en mi teléfono,
sin necesidad de conexión a Internet.
Eso es el verdadero cambio de juego.
Exacto.
Las implicaciones son brutales.
Primero, la privacidad.
Tus datos no salen de tu dispositivo.
Fundamental.
Segundo, la latencia.
La respuesta es instantánea.
Y tercero, el acceso.
Democratizaría la IA de alto nivel.
Gente en zonas con mala conectividad tendría acceso a la misma tecnología.
Asistentes personales realmente inteligentes en el coche,
en el reloj, en cualquier sitio, sin depender de la nube.
Justo.
Vale, vamos a recapitular para que no se nos vaya la cabeza.
El problema es que los modelos actuales son como motores de un Bugatti Veyron.
Increíblemente potentes.
Pero necesitan un tanque de combustible gigantesco.
Y un mantenimiento carísimo.
Y una autopista perfecta para funcionar.
Son un prodigio de la fuerza bruta.
Buena analogía.
Y la solución que propone...
Este equipo es como si hubieran inventado un motor eléctrico del tamaño de una pila que da la misma potencia.
Y lo consiguen cambiando el diseño.
En lugar de miles de ajustes de precisión, los 16 bits usan un simple interruptor de tres posiciones.
Menos uno, cero y uno.
Lo que equivale a 1.58 bits.
Y la afirmación bomba es que este motor minimalista rinde igual que el motor gigante.
Si esto se confirma, no solo abarata los costes de la IA.
No, no.
Sino que podría cambiar las reglas para construir...
...el tipo de chips que usaremos y, finalmente, permitiría que la IA más potente viva dentro de nuestros propios bolsillos.
En resumen, no es una mejora.
Es una de esas ideas que te obliga a repensar todo lo que dabas por sentado.
Cuestiona la base sobre la que se ha construido la IA en los últimos cinco años.
Esto me deja con una pregunta que va más allá de la propia IA.
¿Estamos construyendo nuestros modelos de una forma innecesariamente compleja solo por inercio?
Porque es la única manera que...
...hemos conocido hasta ahora.
Esa es la gran reflexión que deja este trabajo de Xu Ming-Ma y su equipo.
A veces, en tecnología, nos obsesionamos tanto con escalar la solución que ya tenemos...
...que no nos paramos a pensar si existe una solución fundamentalmente más simple y elegante.
Cierto.
Este paper, sea cual sea su impacto final, es un recordatorio de que a veces el mayor salto adelante...
...no es añadir más complejidad, sino atreverse a quitarla.
La verdad es que te deja dándole vueltas a la cabeza.
Un análisis fascinante.
Muchas gracias por guiarnos a través de este laberinto.
Un placer.
Es que es de esos trabajos que te remueven por dentro y te fuerzan a cuestionarlo todo.
Totalmente.
Y para quienes nos escuchan, y se han quedado con ganas de más, que no se preocupen.
Mañana volvemos a la carga con otro de esos papers que te obligan a replantearlo todo.
Otro muy interesante.
No se lo pierdan.
Nos escuchamos en el próximo episodio.