Buenas, esto es BIMPRAXIS, el podcast donde el BIM se encuentra con la inteligencia artificial.
Download transcript (.srt)
0:09
0:20
0:28
0:37
0:40
0:45
0:49
0:56
0:57
1:05
1:07
1:13
1:15
1:19
1:26
1:28
1:33
1:37
1:41
1:42
1:45
1:48
1:53
2:00
2:05
2:09
2:12
2:15
2:17
2:22
2:26
2:29
2:31
2:33
2:37
2:39
2:45
2:47
2:49
2:52
2:54
2:56
3:00
3:00
3:03
3:08
3:12
3:14
3:19
3:25
3:30
3:35
3:37
3:41
3:43
3:43
3:44
3:46
3:50
3:57
4:00
4:03
4:07
4:13
4:14
4:17
4:21
4:24
4:28
4:32
4:35
4:36
4:39
4:43
4:49
4:50
4:55
5:00
5:05
5:08
5:10
5:13
5:17
5:20
5:25
5:29
5:31
5:34
5:36
5:38
5:43
5:45
5:50
5:56
6:01
6:03
6:07
6:11
6:13
6:15
6:15
6:19
6:24
6:26
6:29
6:32
6:35
6:36
6:38
6:41
6:42
6:42
6:45
6:48
6:49
6:52
6:54
6:55
7:00
7:05
7:07
7:09
7:11
7:12
7:14
7:18
7:20
7:23
7:24
7:27
7:31
7:32
7:38
7:40
7:43
7:48
7:50
7:55
7:58
7:59
8:00
8:02
8:05
8:09
8:10
8:13
8:16
8:21
8:25
8:26
8:31
8:35
8:37
8:38
8:40
8:40
8:41
8:43
8:46
8:50
8:56
9:00
9:04
9:07
9:09
9:12
9:13
9:17
9:19
9:20
9:24
9:28
9:30
9:33
9:34
9:35
9:38
9:42
9:47
9:51
9:55
9:56
9:58
10:01
10:03
10:07
10:08
10:10
10:15
10:18
10:19
10:23
10:27
10:30
10:31
10:38
10:40
10:41
10:44
10:47
10:51
10:54
10:57
10:59
11:05
11:09
11:13
11:16
11:17
11:20
11:24
11:26
11:32
11:35
11:41
11:42
11:47
11:48
11:53
11:57
11:57
12:02
12:05
12:06
12:10
12:11
12:13
12:15
12:20
12:22
12:23
12:28
12:31
12:33
12:39
12:40
12:43
12:47
12:48
12:52
12:57
12:59
13:03
13:08
13:10
13:12
13:17
13:23
13:28
13:31
13:32
13:39
13:45
13:51
13:52
13:59
14:01
14:04
14:16
14:28
14:30
Exploramos la ciencia, la tecnología y el futuro desde el enfoque de la arquitectura, ingeniería y construcción.
¡Empezamos!
Bienvenidos a una nueva inmersión en el conocimiento.
Retomamos hoy nuestra serie para BIMPRAXIS sobre los papers que cambiaron la historia de la IA
y, si no me equivoco, este es ya el undécimo capítulo.
El undécimo, sí. Y hoy nos toca uno que, bueno, cuando se publicó causó un revuelo considerable.
¿Ah, sí?
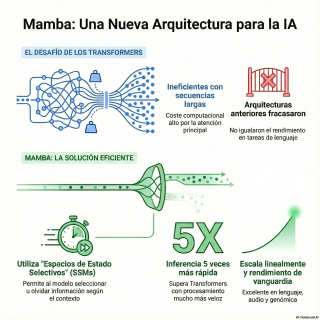
Sí, sí. Es un trabajo que mete el dedo directamente en la llaga de uno de los mayores cuellos de botella de la inteligencia artificial moderna.
Hablas de la eficiencia, ¿verdad?
Porque, a ver, todos estamos maravillados con lo que hacen los grandes modelos de lenguaje, los chat GPT y compañía,
pero, tras bambalinas...
Su arquitectura base, el famoso Transformer, tiene un talón de Aquiles enorme.
Enorme. Es increíblemente potente, pero es que devora recursos de una manera brutal.
El coste computacional se dispara de forma exponencial.
O sea que llega un punto en que es insostenible. No puedes darle una novela entera o un genoma completo
porque la factura de computación, vamos, se iría a la estratosfera.
Exacto. Y justo ahí, en ese lío, es donde aparece el paper del que vamos a hablar hoy.
Mamba.
Modelado de secuencias en tiempo lineal con espacios de estado...
De estado selectivos. De Albert Gu y Tridau.
Por el título entiendo que su misión era precisamente romper esa maldición cuadrática.
Justo esa. Su objetivo era crear una arquitectura que fuera tan inteligente y capaz de entender el contexto como un Transformer,
pero sin esa tara de la eficiencia. Querían un modelo lineal.
Que para leer un libro el doble de largo, solo necesitará el doble de esfuerzo.
Eso es. Un crecimiento sostenible.
Y vamos a ver que la forma en que lo consiguen es...
De una elegancia asombrosa.
Entendido. O sea, el Transformer es potente pero ineficiente con textos largos.
Pero, para entender por qué Mamba es una solución tan ingeniosa,
supongo que primero tenemos que meternos en las tripetas del Transformer.
Hay que ver dónde está el problema, sí.
Hablas del mecanismo de atención. ¿Ese es el culpable?
Es el héroe y el villano de la película. Las dos cosas.
La atención es lo que le da al Transformer su superpoder.
Le permite, para entender una palabra,
las palabras de la secuencia. Todas.
Sin importar lo lejos que estén.
Exacto. Dame un ejemplo práctico. Pues mira.
Imagina una novela de misterio.
En la página 300, el detective dice
Lo supe cuando vi su reacción.
¿Vale?
El mecanismo de atención permite al modelo conectar ese su
con, no sé, el nombre de un sospechoso que se mencionó en la página 15.
Ah, claro. Eso es lo que le da esa profunda comprensión del contexto.
Sí, pero el problema es cómo lo hace.
Para hacer eso, la palabra su ha tenido que mirar y compararse
con cada una de las miles y miles de palabras de las 299 páginas anteriores.
Uf. O sea, que para cada nueva palabra se crea una red de conexiones con todo lo anterior.
Sí. Y esa red es la que crece de forma exponencial y se vuelve inmanejable.
Precisamente. Y ahí está el dilema.
Esa capacidad de mirarlo todo es lo que hace a los Transformers tan buenos,
pero también lo que los frena.
Y claro.
¿Por qué?
Muchos han intentado solucionarlo.
Muchísimos. El campo está lleno de arquitecturas alternativas.
Atención lineal, modelos recurrentes, los llamados modelos de espacio de estados o SSMs.
Pero si entiendo bien, todos se quedaban a medias.
Eran más rápidos, solucionaban el problema de la eficiencia.
Pero perdían algo por el camino. No eran tan listos como los Transformers.
Exacto. Es como si hubieran intentado construir un coche de Fórmula 1 con el consumo de un utilitario.
Exacto.
Lo que tienes es un coche que consume poco, sí, pero que no gana carreras.
Justo. Perdían esa finura en la comprensión del lenguaje.
El paper de Mamba es brillante porque, primero,
diagnostica con una precisión quirúrgica por qué fallaban esos intentos.
¿Y cuál es el diagnóstico? ¿Qué se perdía exactamente?
Lo que los autores llaman razonamiento basado en el contenido.
A ver.
La atención de un Transformer es selectiva por naturaleza.
Para entender la frase del detective, decide que el nombre del sospechoso en la página 15,
es crucial, pero que el color de las cortinas en la página 80 es… irrelevante.
Claro.
Los modelos más rápidos y eficientes que existían antes de Mamba no tenían esa capacidad de discernir.
Es decir, trataban toda la información pasada como si fueran más o menos igual de importante.
Eso es. Es como tener una memoria fotográfica perfecta, pero sin un índice.
Lo recuerdas todo, pero no sabes qué es lo relevante en cada momento.
Y se ahogaban en información.
Se ahogaban en información irrelevante, en ruido.
Y en tareas complejas como el lenguaje, esa sutileza lo es todo.
Vale. Aquí es donde mi cerebro empieza a hacer cortocircuito.
Si los modelos anteriores eran o rápidos y tontos, o lentos e inteligentes,
¿me estás diciendo que los autores de Mamba encontraron un tercer camino?
Un tercer camino que nadie había visto.
Proponen una solución que llaman selectividad.
¿En qué consiste esto?
Aquí está la genialidad.
Introducen los modelos de espacio de estados selectivos, o SSSM,
y la idea es revolucionaria.
En lugar de que el modelo siga unas reglas fijas para procesar la información,
esas reglas cambian dinámicamente dependiendo de lo que está leyendo en ese preciso instante.
Espera un momento. Eso me suena increíblemente complejo, casi caótico.
Si las reglas del juego cambian con cada palabra,
¿cómo se asegura el modelo de mantener una coherencia?
Es una pregunta excelente, y es justo el desafío técnico que tuvieron que resolver.
Pero conceptualmente, la idea es revolucionaria.
Finalmente, piensa en cómo leemos nosotros.
Vale.
No le damos la misma importancia a cada palabra.
Cuando leemos el rey Juan Carlos, nuestro cerebro activa un estado de atención alta.
¿Sabe qué es importante?
Si leemos Fuea, baja la intensidad.
Estamos constantemente filtrando y priorizando.
Y Mamba le da esa misma capacidad a la máquina.
Exacto.
El modelo puede decidir sobre la marcha.
Acabo de leer un dato crucial, lo marco como importante,
y me aseguro de que esta información es importante.
y me aseguro de que esta información es importante.
Y me aseguro de que esta información se propague hacia adelante en mi memoria.
Y esto otro es paja, lo olvido para no saturarme.
Justo.
Es un filtro de relevancia integrado en su propio ADN.
Es una forma de imitar la intuición.
Has dado en el clavo.
Esa capacidad de comprimir la información irrelevante y preservarla relevante
es lo que le permite recordar detalles clave a lo largo de secuencias larguísimas.
Emulando lo que hacía la atención del Transformer.
Y a conservar sólo lo esencial.
Es brillante.
Pero me sigue rondando la cabeza el problema de que la información es importante.
Pero me sigue rondando la cabeza el problema de que la información es importante.
Me has dicho que los modelos rápidos anteriores usaban un truco para su velocidad.
Las convoluciones, sí.
Al hacer que Mamba sea selectivo, ¿no se cargan ese truco?
Totalmente.
Y ese es el segundo acto de genialidad de este paper.
Los SSMs no selectivos usaban un truco matemático.
Las convoluciones.
Para que nos entendamos, es como usar una plantilla o un filtro que se desliza sobre todo el texto a la vez.
En lugar de leer palabra por palabra,
aplicas un patrón fijo a todo el párrafo de golpe.
Sí, y es increíblemente rápido porque es una operación que las GPUs, las tarjetas gráficas,
pueden hacer en paralelo masivamente.
Pero claro, el truco sólo funciona si la plantilla es siempre la misma.
Si la plantilla cambia con cada palabra, como en Mamba…
¿Adiós a la velocidad?
Exacto.
Parecía un callejón sin salida.
O eres rápido y usas una plantilla fija, y eres tonto.
O eres inteligente y usas una plantilla adaptable, y eres lento.
¿Y qué hicieron?
Pues algo que muy poca gente hace.
En lugar de rendirse, diseñaron un nuevo algoritmo desde cero,
pensando no sólo en las matemáticas, sino en cómo funcionan las GPUs por dentro.
¿Quieres decir que diseñaron el algoritmo a medida para el propio chip?
Sí, y esto es clave.
No sólo un avance en IA, es un avance en la intersección de software y hardware.
La mayoría de investigadores crean un modelo teórico y luego, bueno,
rezan para que corra rápido.
Sí.
Ellos miraron la arquitectura de memoria de las GPUs.
Sí. Ellos miraron la arquitectura de memoria de las GPUs.
Ellos miraron la arquitectura de memoria de las GPUs.
Cómo gestionan los datos.
Y crearon un algoritmo que piensa como el propio silicio.
Un enfoque integral, de la teoría abstracta al metal.
Y el resultado, según cuentan, es una arquitectura que ellos mismos llaman simplificada.
A mí esto me fascina, porque en IA, simple no suele ser sinónimo de potente.
Es que la simplicidad aquí es una consecuencia de su elegancia.
Se dieron cuenta de que, con su mecanismo selectivo,
muchas de las piezas que se consideraban sagradas
en los transformers ya no eran necesarias.
¿Cómo cuáles?
Su arquitectura mamba ni siquiera necesita los bloques de atención, obviamente.
Pero tampoco los bloques MLP.
Un momento.
Siempre he oído que los bloques MLP son como el cerebro computacional
de cada capa del transformer, donde se produce gran parte del razonamiento.
Si los quitan, ¿con qué los reemplazan?
Es que no los reemplazan, los eliminan.
Los eliminan.
Sí.
Descubren que la propia dinámica de su sistema selectivo,
con esa capacidad de filtrar y propagar información,
ya realiza el tipo de computación que los MLPs hacían de una forma más bruta.
El resultado es un diseño mucho más limpio, menos piezas móviles.
Bueno, la teoría es espectacular, pero vamos a la prueba de fuego.
Funciona.
¿Cuáles son los resultados en la práctica?
Porque en el mundo de la IA hay muchos papers con ideas geniales
que luego no dan la talla.
Pues aquí es donde la historia se pone aún mejor.
Los resultados son…
apabullantes.
En tareas de inferencia, es decir, cuando el modelo ya entrenado se pone a trabajar,
Mamba consigue un rendimiento cinco veces superior.
Cinco veces.
Cinco veces más rápido que los transformers de tamaño comparable.
Cinco veces es un salto generacional, no una mejora incremental.
¿Y qué pasa con el problema original, el del coste que se dispara?
Solucionado.
Su coste computacional escala de forma lineal con la longitud de la secuencia, no cuadrática.
La maldición se ha roto.
Increíble.
El paper lo demuestra a consecuencias de hasta un millón de tokens,
un millón de palabras o fragmentos de palabra.
Procesar algo así en un transformer era sencillamente ciencia ficción.
Por su coste, claro. Mamba lo hace viable.
Lo hace viable. Y ojo, que esto no es sólo para generar textos.
Mencionaste genomas antes, por ejemplo.
Efectivamente. El paper demuestra que Mamba alcanza un rendimiento de vanguardia en múltiples modalidades.
En lenguaje, por supuesto, pero también en audio y en genómica.
Son campos donde las secuencias son larguísimas por naturaleza.
Y donde el problema del coste era aún más sangrante.
Mucho más.
De todos los datos que das, ¿cuál es para ti el más impactante?
El que de verdad te hace pensar, esto cambia las reglas del juego.
Para mí, sin duda, es este.
Cogen su modelo Mamba de 3.000 millones de parámetros, que ya es un modelo considerable.
Y no sólo supera a los transformers del mismo tamaño.
Lo increíble es que iguala el rendimiento de transformers del doble de su tamaño.
Espera, espera. Repite eso.
Un Mamba de 3 millones de parámetros rinde igual que un transformer de 6 millones.
Exactamente.
Consigue los mismos resultados, la misma calidad, con la mitad de recursos.
Pero eso tiene unas implicaciones económicas y energéticas brutales.
Brutales.
Piensa en el coste de entrenar un modelo de 6.000 millones de parámetros.
En las miles de GPUs funcionando durante semanas.
En la factura de la luz.
Y Mamba demuestra que puedes obtener lo mismo gastando la mitad.
Gastando la mitad.
No es sólo más rápido.
Es dramáticamente más eficiente.
Entonces, si tuviéramos que destilar la gran lección de este paper, ¿cuál sería?
Porque está claro que no es sólo un pequeño ajuste.
Para nada.
Es un desafío frontal al dominio absoluto de la arquitectura transformer.
Demuestra que hay vida más allá de la atención.
Propone una alternativa que no sólo es potente,
sino radicalmente más eficiente justo en el punto donde los transformers son más débiles.
Es un cambio de filosofía.
Pasar de la fuerza bruta de mirarlo todo,
a la inteligencia selectiva de recordar sólo lo importante.
Exacto.
Y eso abre la puerta a aplicaciones que antes eran impensables o prohibitivas.
Imagina analizar historiales médicos completos de una sola vez para encontrar patrones,
en lugar de ir trozo a trozo.
O procesar genomas enteros con una fluidez que acelere la investigación médica.
O crear asistentes de audio que puedan recordar una conversación de una hora sin perder el hilo.
Todo gracias a esa idea central.
El poder de la selectividad.
Realmente fascinante cómo una idea elegante puede resolver un problema tan masivo.
Y si este análisis les ha abierto el apetito, no se imaginan lo que tenemos preparado para mañana.
Exploraremos otro paper que redefine otra pieza clave en el puzle de la inteligencia artificial.
Antes de cerrar, me gustaría dejar una pregunta en el aire.
Adelante.
El hecho de que Mamba iguale a un Transformer del doble de su tamaño nos obliga a reflexionar sobre algo fundamental.
¿Cuánto del impresionante rendimiento de los grandes modelos actuales se debe a la pura fuerza bruta computacional,
a hacerlos más y más y más grandes, y cuánto se debe a la elegancia de su arquitectura?
Es una muy buena pregunta.
Mamba sugiere que la elegancia y el diseño inteligente podrían llevarnos mucho más lejos,
y de forma mucho más sostenible,
de lo que la fuerza bruta jamás podrá.
Y hasta aquí el episodio de hoy.
Muchas gracias por tu atención.
Esto es BIMPRAXIS.
Nos escuchamos en el próximo episodio.