Buenas, esto es BIMPRAXIS, el podcast donde el BIM se encuentra con la inteligencia artificial.
Download transcript (.srt)
0:09
0:20
0:28
0:37
0:40
0:45
0:48
0:57
1:03
1:07
1:14
1:15
1:16
1:21
1:27
1:31
1:35
1:43
1:45
1:46
1:50
1:57
1:59
2:06
2:11
2:15
2:22
2:28
2:33
2:36
2:40
2:44
2:50
2:56
3:01
3:05
3:10
3:14
3:16
3:20
3:25
3:30
3:32
3:33
3:40
3:42
3:44
3:51
3:57
4:00
4:02
4:07
4:10
4:14
4:14
4:18
4:19
4:23
4:30
4:32
4:35
4:37
4:43
4:44
4:46
4:51
4:52
4:57
5:02
5:06
5:10
5:11
5:14
5:18
5:24
5:27
5:31
5:36
5:39
5:44
5:48
5:50
5:54
6:00
6:06
6:09
6:10
6:14
6:17
6:18
6:22
6:24
6:27
6:31
6:36
6:40
6:42
6:44
6:49
6:54
6:56
6:56
7:00
7:05
7:07
7:08
7:11
7:14
7:15
7:17
7:21
7:22
7:23
7:28
7:31
7:37
7:38
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:43
7:45
7:50
7:52
7:56
7:57
7:59
8:04
8:08
8:10
8:12
8:13
8:16
8:17
8:21
8:25
8:27
8:33
8:38
8:40
8:41
8:41
8:42
8:42
8:42
8:42
8:42
8:42
8:42
8:42
8:42
8:42
8:42
8:42
8:42
8:42
8:42
8:42
9:11
9:12
9:12
9:12
9:19
9:24
9:30
9:35
9:41
9:47
9:52
9:57
10:03
10:07
10:11
10:18
10:24
10:30
10:35
10:41
10:47
10:52
10:58
11:01
11:07
11:11
11:18
11:23
11:29
11:35
11:41
11:47
11:52
11:59
12:04
12:10
12:11
12:17
12:23
12:29
12:35
12:41
12:45
12:50
12:56
13:01
13:05
13:11
13:15
13:20
13:27
13:33
13:39
13:41
13:45
13:50
13:51
13:55
14:00
14:02
14:07
14:08
14:11
14:17
14:18
14:22
14:24
14:29
14:32
14:37
14:41
14:43
14:49
14:50
14:50
14:55
14:58
14:59
15:03
15:05
15:11
15:17
15:23
15:25
15:27
15:31
15:36
15:41
15:44
15:44
15:51
15:54
16:00
16:05
16:06
16:11
16:16
16:19
16:21
16:27
16:32
16:37
16:41
16:47
16:48
16:49
16:54
17:00
17:05
17:11
17:12
17:22
17:23
17:27
17:30
17:42
17:44
17:50
17:55
18:03
18:11
18:14
18:16
18:21
18:33
18:38
Exploramos la ciencia, la tecnología y el futuro desde el enfoque de la arquitectura, ingeniería y construcción.
¡Empezamos!
Hola y bienvenidos a una nueva entrega.
Hoy llegamos al noveno análisis de nuestra serie especial de BIMPRAXIS.
Los papers que cambiaron la historia de la IA.
Exacto. Y hoy nos metemos de lleno en un campo de batalla que es, bueno, constante en este mundo, la lucha por la eficiencia.
Todos queremos modelos de IA que sean como atletas de élite, potentes, precisos, pero a la vez…
Ágiles, rápidos y que no se agoten a la primera de cambio.
Ese es el santo grial, sí. Pero la realidad en ingeniería, y sobre todo en MLOPS, es que casi siempre te encuentras con un compromiso.
El famoso.
El famoso trade-off.
El trade-off de rendimiento, sí. Para ganar precisión tienes que pagar un precio.
Y ese precio es coste computacional, velocidad, tamaño… Un precio que a veces es altísimo.
Pero la pregunta que flota en el aire, y que es el corazón del paper de hoy, es…
¿Y si esa elección no fuera necesaria? ¿Y si pudieras tenerlo todo?
Imagina, un único modelo de IA que pudiera como cambiar de marcha, que adaptara su complejidad y su coste sobre la marcha.
Sin tener que volver al taller.
Sin reentrenarlo.
Una especie de navaja suiza para las representaciones de datos.
Justo. Y es una idea que suena casi a ciencia ficción, porque va en contra de cómo se han construido los modelos durante años.
La rigidez es la norma.
Totalmente. Pues esa es precisamente la norma que viene a romper el paper que tenemos sobre la mesa.
Matryoshka Representation Learning. Publicado por primera vez en mayo de 2022.
Y el propio nombre, Matryoshka, como las muñecas rusas, ya nos da una pista.
Una pista muy, muy clara de por dónde va la solución. Es una idea tan elegante como intuitiva.
Es una de esas ideas que, cuando la lees, piensas, ¿cómo no se le había ocurrido a nadie antes?
Ataca un problema que es un verdadero quebradero de cabeza en el despliegue de sistemas de IA a gran escala.
Y lo hace desde la raíz misma del modelo.
Exacto. De acuerdo, pues vamos a meternos en faena.
A ver, para entender la genialidad de la propuesta, primero tenemos que hablar de la pieza central.
Las representaciones aprendidas. O los embeddings, como se les conoce en la jerga.
Eso es. A mí me gusta pensar en ellos como la ficha técnica que una IA crea de algo.
Si le muestras una foto de un gato, no ve un gato. Ve una lista larguísima de números.
Y esa lista de números, para ella, codifica la esencia del hogatuno en esa imagen.
Es una analogía perfecta. Es un resumen numérico que captura las características más importantes.
Y el dilema fundamental, el pecado original de muchos sistemas,
empieza justo ahí.
En el momento de decidir cómo de larga y detallada va a ser esa ficha técnica.
Exacto. Tienes que elegir una dimensión. Pongamos 1024 números.
Con eso, obtienes una ficha súper detallada. Muy rica en matices.
Perfecta para tareas de análisis muy complejas.
Pero claro.
Mover, almacenar y comparar millones de esas fichas de 1024 números es increíblemente lento.
Y caro.
Y la alternativa es decirte al otro extremo.
Es una ficha muy corta, de 128 números. Rapidísima de procesar. Ideal para una búsqueda en un móvil.
El problema es que en esa compresión tan agresiva pierdes información. Es como intentar describir el Quijote.
Puedes hacerlo en un tuit de 280 caracteres.
O en un ensaño de 50 páginas.
Pues eso. El tuit es rápido, pero te dejas el 99% de la obra por el camino.
Es una gran analogía.
Me recuerda cuando intentas explicar una película compleja a un amigo en 30 segundos.
Te quedas con un amigo en 30 segundos.
Con... va de un tipo que... y pierdes todo el matiz.
Pues aquí pasa lo mismo.
Pero con millones de euros en costes de computación en juego.
Y lo peor de todo es que, una vez que has entrenado a tu modelo para que escriba ensayos de 50 páginas...
No puedes pedirle que te haga un tuit.
Estás atado a ese formato. No hay marcha atrás.
Y esa rigidez es una pesadilla a nivel operativo.
Obliga a las grandes empresas a entrenar y mantener, bueno, ecosistemas enteros de modelos.
Claro.
En la plataforma de comercio electrónico.
Necesitan una versión ligera del modelo para las búsquedas visuales en la app, que tienen que ser instantáneas.
Ajá.
Pero también necesitan una versión pesada, ultra precisa, en sus servidores para analizar patrones de compra.
Y son dos modelos distintos, con dos pipelines de datos, dos equipos de mantenimiento...
El coste se dispara. Y no es solo un problema de coste económico.
El propio paper señala que es un sistema estadísticamente ineficiente.
¿A qué se refieren con eso?
Pues que para una tarea simple, como distinguir un perro de un gato,
esa ficha de 1024 números es excesiva, es un derroche.
Y para una tarea muy compleja, como identificar una subespecie concreta de pájaro,
quizás la ficha de 128 se queda corta.
Y pierdes la precisión que necesitabas. Al final, es el clásico un tamaño para todo.
Que en la práctica significa que no es el tamaño perfecto para casi nada.
Siempre estás o malgastando recursos o sacrificando rendimiento.
Vale, el problema está clarísimo. O rápido y simple, o listo y lento.
Y estás atado a tu elección inicial. Parece un callejón sin salida.
¿Cómo demonios lo solucionan los autores? ¿Cuál es el truco?
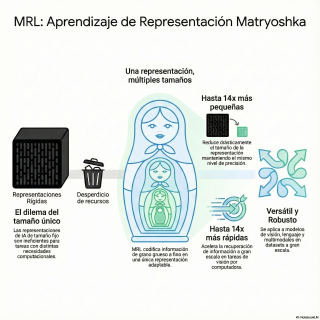
Pues el truco es dejar de pensar en la ficha técnica como un bloque monolítico.
Y empezar a pensar en ella como... como una muñeca matriosca.
La idea es brillante. Entrenas un único modelo para que genere la ficha más grande y detallada posible.
La de 1024. La más completa.
Pero lo haces de una forma muy especial.
De modo que dentro de esa gran representación,
anidadas, ya existen versiones más pequeñas.
Y totalmente funcionales.
Como las muñecas rusas. Abres la grande y dentro hay otra.
Un poco más pequeña, pero perfectamente formada.
La abres y hay otra más.
Cada una es una versión completa de la muñeca, pero a una escala diferente.
Llevado a la práctica, esto significa que si una aplicación necesita velocidad máxima,
en lugar de usar los 1024 números, simplemente coge los primeros 128.
Y ignora el resto.
Y lo revolucionario es que...
Estos 128 números no son un trozo incompleto y sinsentido de la ficha grande.
Son, por sí mismos, una ficha técnica coherente y de alta calidad.
Sólo que con menos resolución.
Exacto.
Espera, eso es lo que me parece casi mágico.
Intuitivamente, si tienes una lista de datos que describe algo y la cortas,
esperarías que el resultado fuera basura.
¿Información corrupta?
Claro, como si cortas una foto por la mitad.
¿Cómo consiguen que la primera parte del vector siga la misma?
Está teniendo sentido por sí sola.
Ahí está la clave del asunto.
Y la palabra que usan es aprendizaje de grano grueso afino.
Course to find.
De acuerdo.
La genialidad está en modificar ligeramente el objetivo del entrenamiento.
Normalmente, al entrenar, le dices al modelo.
Tu objetivo es que la ficha completa de 1024 números sea lo más precisa posible.
Ajá.
Con Matriuska Representation Learning, o MRL, el objetivo cambia.
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
¿Qué pasa?
Ahora le dices.
Tu objetivo es que la ficha completa sea precisa, pero también que los primeros 512 números
sean una versión precisa.
Y que los primeros 256 también lo sean.
Y los primeros 128.
Y así sucesivamente.
O sea que lo fuerzas a organizar la información de forma jerárquica.
Es como si le dijeras, en los primeros números quiero el boceto general, la información
más importante.
Y a medida que añades más números…
Vas añadiendo detalles.
… texturas y matices cada vez más finos.
¿Has dado en Eikau?
Es un diseño de información increíblemente inteligente.
La información más crítica y general se empaqueta al principio del vector.
Y la más específica y detallada al final.
Y lo más importante, un detalle crucial que mencionan y que es la clave de su viabilidad.
Esta flexibilidad no añade ningún coste extra en el momento de usar el modelo, en
lo que se conoce como inferencia.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
Exacto.
escala. Construir modelos gigantescos. Y luego, comprime, comprime, comprime. Intentar hacerlos
más pequeños con técnicas posteriores. Este paper demuestra que la eficiencia no tiene por
qué ser un paso posterior, una ocurrencia tardía. Puede ser una propiedad intrínseca del modelo.
Horneada en su ADN desde el principio. Y es interesante ponerlo en contexto con otras
técnicas. Antes de MPRL, ¿qué se hacía para intentar solucionar este problema? Había
principalmente dos enfoques. Uno es la poda o pruning, que es como coger el modelo ya entrenado
y literalmente ir cortando las conexiones neuronales que parecen menos importantes.
Como un jardinero que poda un arbusto. Justo. El otro es la cuantificación,
que consiste en coger los números de la ficha técnica y representarlos con menos precisión,
usando enteros en lugar de decimales largos, por ejemplo. Pero ambos métodos suenan
destructivos. Una vez que podas algo,
no lo puedes recuperar. Y si reduces la precisión, pierdes información para siempre. Ese es el punto.
Son técnicas que se aplican a posteriori y que implican una pérdida de información irreversible.
MRL es fundamentalmente distinto. No destruye nada. Exacto. Te da acceso a la representación
de máxima fidelidad si la necesitas, pero también te ofrece atajos eficientes que ya
estaban previstos en el diseño original. Es una solución mucho más elegante. Y flexible.
La verdad es que la idea es brillante. Pero las ideas hay que demostrarlas. ¿Qué tal funcionan
estas muñecas en el mundo real? ¿Los resultados que presentan están a la altura?
Están más que a la altura. Son espectaculares. Y los autores se cuidan mucho de probarlo en
múltiples escenarios para demostrar que no es un golpe de suerte.
A ver, vamos a ver esos números. En el resumen hablan de una reducción de tamaño de hasta 14
veces en los embeddings. En clasificación, en la famosa base de datos ImageNet,
1K. Y manteniendo el mismo nivel de precisión. 14 veces. Pensemos lo que eso significa. Es la
diferencia entre un archivo que ocupa 140 megas y uno que ocupa 10, para un móvil con almacenamiento
limitado. O para transmitir datos por una red con poco ancho de banda. Esa diferencia es abismal.
Abre la puerta a tener IA mucho más potente en dispositivos de borde, los Edge Devices. Claro,
como sensores, cámaras de seguridad inteligentes o incluso wearables. Eso es. Y no solo más pequeños,
también más rápidos. Mencionan aceleraciones de hasta 14 veces en tareas de búsqueda a gran escala.
Que si tienes una base de datos con millones de imágenes. Encontrar la que más se parece a la
tuya podría pasar de tardar 14 segundos a tardar solo uno. Que, a efectos prácticos para quien lo
usa, es la diferencia entre una experiencia frustrante y una que parece mágica. Casi
instantánea. Piensa en las aplicaciones de busca por imagen en el comercio electrónico. Una
velocidad así cambia por cada vez más. Y no solo en el comercio electrónico, sino en el comercio
completo la experiencia de compra. Y aquí viene algo que me sorprendió. No solo se trata de ser
más eficiente. El paper afirma que MRL puede incluso mejorar la precisión en ciertas tareas. Citan una
mejora de hasta un 2% en la clasificación Few Shot de cola larga. Esto suena muy técnico. ¿Qué
significa exactamente? Es uno de los resultados más interesantes y, como dices, contraintuitivos.
La clasificación Few Shot de cola larga es básicamente el reto de identificar categorías
muy pocos ejemplos. Entiendo. Piensa en un sistema que tiene que identificar miles de
especies de animales. Pero para una especie de mariposa muy rara, solo tiene dos fotos.
Un problema increíblemente difícil y muy común en el mundo real. Exacto. La hipótesis de por qué
MRL ayuda aquí es fascinante. Parece que las representaciones más pequeñas, las muñecas
interiores, al ser forzadas a resumir la información, capturan las características
más generales, robustas y abstractas. El concepto de mariposa, por así decirlo. Y cuando
tienes muy pocos ejemplos, apoyarte en esas características generales es más efectivo.
Que intentar aprender de los detalles súper específicos que podrían estar en la representación
más grande. Justo. Es un doble tanto. No solo eres más eficiente, sino que mejoras en los casos
más difíciles. Y para rematar, subrayan que estas representaciones son igual de robustas
que las originales. No se pierde fiabilidad. Fundamental. Pero esto es un truco que solo
funciona con imágenes. Para nada.
Y esa es otra de las grandes fortalezas del paper. Demuestran la versatilidad de la idea
aplicándola a un abanico enorme de arquitecturas y modalidades de datos.
Vale.
Lo validan en visión, con modelos clásicos como ResNet y más modernos como los Vision
Transformers, los BIT. Lo prueban en lenguaje, con el archiconocido modelo BERT.
E incluso van un paso más allá.
Y lo aplican en modelos multimodales, que entienden a la vez imágenes y texto. Como
Align.
Y todo esto no en datasets de juguete, sino en...
En conjuntos de datos a escala web, como ImageNet o JFT, que tienen millones y millones
de ejemplos.
Correcto. Esto es una señal muy clara para la comunidad científica y para la industria.
El mensaje es...
Esto no es un experimento de laboratorio. Es una técnica robusta, validada a gran escala
y lista para ser implementada en producción.
Vale. Llegados a este punto, está claro que la idea es potente. Pero toda solución
suele tener sus contrapartidas. ¿Hay alguna limitación? ¿Es MRT?
¿RL la solución perfecta para todo?
Es una pregunta muy pertinente. Los propios autores son honestos al respecto. La técnica
no es perfecta.
Ajá.
Reconocen que para las representaciones más pequeñas, las muñecas más internas, sí
que existe una pequeña pero medible pérdida de precisión.
¿Comparado con qué?
Si las comparas con un modelo que hubiera sido entrenado específicamente para esta
dimensión tan pequeña desde el principio.
O sea, que una matrioska de 128 dimensiones es muy buena, pero un modelo específico,
especializado, entrenado, solo para 128 dimensiones, podría ser ligeramente mejor.
Podría serlo. El truco, y el motivo por el que MRL es tan valioso, es que esa pérdida
de rendimiento es mínima.
A menudo insignificante.
Mientras que el beneficio que obtienes en flexibilidad y en no tener que entrenar 10
modelos distintos es absolutamente gigantesco. El balance es abrumadoramente positivo.
Entonces, si tuviéramos que resumir la gran aportación, la palabra clave…
La palabra clave que se me viene a la mente es adaptabilidad.
Sí.
Es un cambio de paradigma. Pasamos de la filosofía rígida de un tamaño para todos a una mucho
más inteligente, de un tamaño para cada necesidad.
Y todo ello dentro de un único modelo entrenado una sola vez. Es la síntesis perfecta. MRL
integra la eficiencia y la flexibilidad en el núcleo mismo del aprendizaje.
No es un parche.
No es un parche, no es una compresión posterior. Es una propiedad fundamental de la representación.
Desde su concepción, es como diseñar un motor que, por su propia naturaleza, puede funcionar en
modo eco, normal o sport.
En lugar de construir tres motores distintos.
Exacto. Una idea que parece abrir un campo de posibilidades enorme. Y esto me lleva a la
pregunta que planteabas al principio. Si hemos conseguido hornear la eficiencia computacional
directamente en las representaciones, ¿qué otras capacidades podríamos integrar de la misma manera?
Esa es la pregunta del millón. Y la que hace que este paper sea
tan inspirador. Podríamos diseñar representaciones que fueran inherentemente más justas, para mitigar
sesgos.
O más interpretables.
O más interpretables, para que podamos entender mejor por qué toman una decisión. Quizás
representaciones que tuvieran capas de privacidad, donde la parte más externa fuera anónima.
Y solo ciertas aplicaciones pudieran acceder a las capas internas más detalladas.
Abre una nueva forma de pensar sobre qué propiedades deseables podemos construir en
las representaciones de la IA.
Una perspectiva fascinante. Sin duda, Matryoshka Representation Learning es un ejemplo perfecto de una idea elegante, inspirada en un objeto casi infantil.
Totalmente.
Que resulta ser profundamente práctica y con un potencial transformador enorme.
Es la belleza de la investigación en su máxima expresión.
Ha sido un análisis fascinante. Y mañana tenemos otro paper que no se queda atrás. Vamos a explorar una idea que redefinió por completo la forma en que los modelos de lenguaje entienden y generan.
Sentando las bases de mucho de lo que vemos hoy.
En los asistentes virtuales y los chatbots más avanzados. No se lo pueden perder.
Y como pensamiento final, el concepto de Matryoshka nos deja con una reflexión.
Quizás el futuro no está en la carrera armamentística de entrenar modelos cada vez más gigantes para luego intentar hacerlos más pequeños a la fuerza.
Sino que quizás el futuro está en enseñar a los modelos a ser inherentemente flexibles, modulares y eficientes.
Desde su concepción. En cada una de sus capas.
Un punto de vista muy potente.
Con esa idea nos despedimos por hoy. Gracias por acompañarnos en este análisis.
Hasta mañana.
Y hasta aquí el episodio de hoy. Muchas gracias por tu atención.
Esto es BIMPRAXIS. Nos escuchamos en el próximo episodio.